08-String类和方法
1. String特点
- 字符串是常量,创建后不可改变;
- 字符串字面值存储在字符串池中,可以共享;
JVM内存管理中:栈、堆、方法区(方法区中有常量池,常量池中嵌套了字符串池)
先来看个简单的案例:
1 | |
这种追加字符串的情况,在理论上会产生若干的中间变量,浪费内存。
而实际结果却不然,如何说明和证明呢?
2. 反编译解析追加优化
找到编译生成的.class文件,然后对应目录下,执行反编译命令:javap -v TestString > TestString.bytecode
命令说明:
- -v 是输出附加信息
- TestString 是类名即文件名
- > 重定向符号,将命令的输出全部重定向到文件中保存
- .bytecode 后缀名无所谓,使用.txt也一样,我们只需要查看内容
查看和分析反编译信息: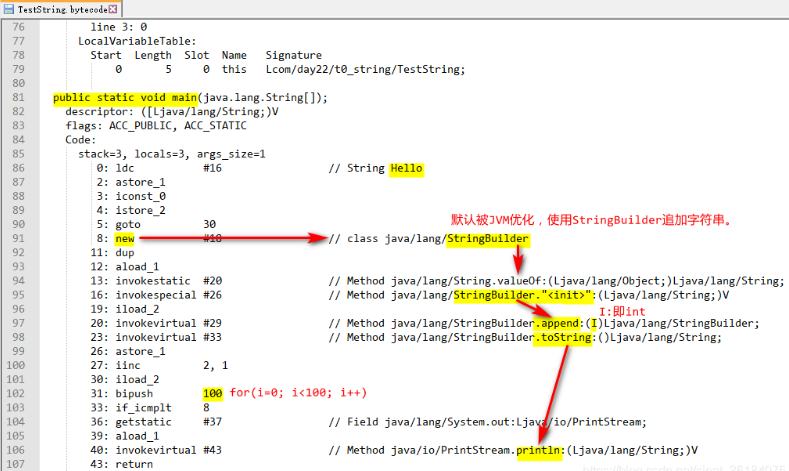
进而得出结论:
str += i; // 被JVM自动优化了,实际不会产生中间变量
JDK的实现方式是什么?
- 自动创建了StringBuilder对象
- 调用StringBuilder的构造方法
- 调用StringBuilder的append(int i)方法
- 调用StringBuilder的toString()方法转回为String类型,并赋值给str
StringBuilder直接在str指向的对象空间里扩展空间追加。
3. StringBuilder 和 StringBuffer
StringBuilder: 可变长字符串,JDK5.0提供,运行效率快、线程不安全。
StringBuffer: 可变长字符串,JDK1.0提供,运行效率慢、线程安全。
两者实现几乎一样,决定两者区别的是 StringBuffer 成员方法上增加了
synchronized关键字修饰。
3.1 StringBuilder
1 | |
StringBuilder提供与StringBuffer的API,但不保证同步。 此类设计用作简易替换为StringBuffer在正在使用由单个线程字符串缓冲区的地方(如通常是这种情况)。
在可能的情况下,建议使用这个类别优先于StringBuffer ,因为它在大多数实现中将更快。
StringBuilder的主要StringBuilder是append和insert方法,它们是重载的,以便接受任何类型的数据。 每个都有效地将给定的数据转换为字符串,然后将该字符串的字符附加或插入字符串构建器。 append方法始终在构建器的末尾添加这些字符; insert方法将insert添加到指定点。
一般情况下,如果某人是指的一个实例StringBuilder ,则sb.append(x)具有相同的效果sb.insert(sb.length(), x) 。
每个字符串构建器都有一个容量。 只要字符串构建器中包含的字符序列的长度不超过容量,则不需要分配新的内部缓冲区。 如果内部缓冲区溢出,则会自动变大。
StringBuilder不能安全使用多线程,如果需要同步,那么建议使用StringBuffer。
除非另有说明,否则将null参数传递给null中的构造函数或方法将导致抛出NullPointerException 。
3.2 StringBuffer
1 | |
一个线程安全的,字符的可变序列。一个字符串缓冲区就像一 String,但是可以修改。在任何一个时间点,它包含一些特定的字符序列,但该序列的长度和内容可以通过某些方法调用。
字符串缓冲区是安全的使用多个线程。在必要的情况下,所有的操作在任何特定的实例的行为,如果他们发生在一些串行顺序是一致的顺序的方法调用所涉及的每个单独的线程的方法是同步的。
在StringBuffer主要是是append和insert方法的重载,以便接受任何数据类型。每个有效地将一个给定的数据到一个字符串,然后追加或插入字符串的字符的字符串缓冲区。的append方法总是添加这些字符缓冲区末尾的insert方法添加的特点;在指定点。
例如,如果z指一个字符串缓冲区对象的当前内容”start”,然后调用方法z.append(“le”)会导致字符串缓冲区包含”startle”,而z.insert(4, “le”)会改变字符串缓冲区包含”starlet”。
一般来说,如果某人是一个StringBuffer实例,然后sb.append(x)具有相同的效果sb.insert(sb.length(), x)。
当一个操作发生涉及源序列(如添加或插入从源序列),这类同步只在字符串缓冲区进行操作,不在源。值得注意的是,虽然StringBuffer的设计是使用同时从多个线程安全的,如果构造函数或append或insert操作是通过源序列,跨线程共享,调用代码必须确保手术的手术时间的源序列一致的和不变的观点。通过使用一个不可变的源序列,或通过不共享在线程中的源序列,调用方在操作过程中保持一个锁,可以满足这一。
每一个字符串缓冲区都有一个容量。只要字符串缓冲区中包含的字符序列的长度不超过容量,就没有必要分配一个新的内部缓冲区阵列。如果内部缓冲区溢出,则自动作出较大的。
1 | |
1 | |
1 | |
【结论】
不论字符串被保存在堆中,还是常量池中字符串池里,只要内容一样,hashCode()也一样;
- == 关系运算符对比的是String类型的地址,堆区与方法区中常量池地址在内存的不同区域,故不同;
- “abc” + “def” 完全等价于 “abcdef” 的写法,常量池中只有一份(首次出现),赋值String变量时地址均相同;
- String类中的成员方法 intern() 可手动将堆中的字符串加入到字符串池中,但必须满足被加入的字符串为代码逻辑中首次出现;否则则会使用首次出现的字符串常量的地址去做对比。
