03-20条类、对象及方法高质量准则
书读的多而不思考,你会觉得自己知道的很多。书读的多而思考,你会觉得自己不懂的越来越多。 —— 江疏影
31:在接口中不要存在实现代码
如题。
32:静态变量一定要先声明后赋值
如题。
33:不要重写静态方法
实例对象访问静态方法或静态属性不是好习惯,直接类名调用就行了。
34:构造函数尽量简化
如题。
35:避免在构造函数中初始化其他类
如题。
36:使用构造函代码块精简程序
1、代码块基本概念:
什么叫做代码块(Code Block)?用大括号把多行代码封装在一起,形成一个独立的数据体,实现特定算法的代码集合即为代码块,一般来说代码快不能单独运行的,必须要有运行主体。在Java中一共有四种类型的代码块:
普通代码块:就是在方法后面使用”{}”括起来的代码片段,它不能单独运行,必须通过方法名调用执行;
静态代码块:在类中使用static修饰,并用”{}”括起来的代码片段,用于静态变量初始化或对象创建前的环境初始化。
同步代码块:使用synchronized关键字修饰,并使用”{}”括起来的代码片段,它表示同一时间只能有一个线程进入到该方法块中,是一种多线程保护机制。
构造代码块:在类中没有任何前缀和后缀,并使用”{}”括起来的代码片段;
2、代码实例展示:
1 | |
当实例化时:
1 | |

当实例化时,执行顺序:静态代码块>>构造代码块>>构造函数>>普通方法。
当类名调用静态方法,不实例化时:
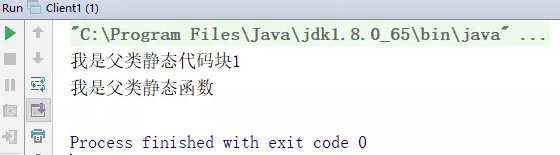
只执行静态代码块和对应的静态函数,构造函数不执行!
3、构造代码块应用场景:
① 初始化实例变量
如果每个构造函数都要初始化变量,可以通过构造代码块来实现。
注:不是每个构造函数都要加载的,而构造代码块一定加载。
② 初始化实例变量
一个对象必须在适当的场景下才能存在,如果没有适当的场景,就需要在创建该对象的时候创建场景。例如HTTP request必须首先建立HTTP session,此时就可以通过构造代码块来检查HTTP session是否已经存在,不存在则创建。
注:构造函数要实现复杂逻辑的时候,可以通过编写多个构造代码块来实现,每个代码块完成不同的业务逻辑(构造函数尽量简单的原则),按照业务顺序依次存放,这样在创建实例对象时JVM会按照顺序依次执行,实现复杂对象的模块化创建。
37:构造代码块会想你所想
38:使用静态内部类提高封装性
1、Java中的嵌套类分为两种:静态内部类和内部类。
1 | |
其中,Person类中定义了一个静态内部类Home,它表示的意思是“人的家庭信息”,由于Home类封装了家庭信息,不用在Person类中定义homeAddr,homeTel等属性,这就提高了封装性,可读性也提高了。
1 | |
2、静态内部类的优势:
提高封装性
提高代码的可读性
形似内部,神似外部
静态内部类虽然存在于外部类中,而且编译后的类文件也包含外部类(格式是:外部类+$+内部类),但是它可以摆脱外部类存在,也就是说可以通过new Home()声明一个home对象,只是需要导入Person.Home而已。
3、静态内部类和普通内部类的区别:
① 静态内部类不持有外部类的引用:
普通内部类可以访问外部类的所有属性和方法。
静态内部类只能访问外部类的静态属性和静态方法。
② 静态内部类不依赖外部类:
普通内部类与外部类同生共死,一起被垃圾回收。
静态内部类可以独立存在。
③ 普通内部类不能声明static的方法和变量,final static修饰的常量除外。
39:使用匿名类的构造函数?
40:匿名类的构造函数很特殊?
39和40暂时没看出有啥用,再说吧!如有需要请阅读原著《编写高质量代码:改善Java程序的151个》!
41:让多继承成为现实
在Java中一个类可以多重实现,但不能多重继承,也就是说一个类能够同时实现多个接口,但不能同时继承多个类。
Java中提供的内部类可以曲折的解决此问题。
42:让工具类不可实例化
43:避免对象的浅拷贝
我们知道一个类实现了cloneable接口就表示它具备了被拷贝的能力,如果重写clone()方法就会完全具备拷贝能力。拷贝是在内存中进行的,所以性能方面比直接new生成的对象要快很多,特别在大对象的生成上,性能提升非常显著。但是浅拷贝存在对象属性拷贝不彻底的问题。
浅拷贝:
1、概念
创建一个新对象,然后将当前对象的非静态字段复制到新对象,如果是值类型,对该字段进行复制;如果是引用类型,复制引用但不复制引用的对象。因此,原始对象及其副本引用同一个对象。
2、实现方法
调用对象的 clone 方法,必须要让类实现 Cloneable 接口,并且覆写 clone 方法。
44:推荐使用序列化对象的拷贝
深拷贝:
1、概念
创建一个新对象,然后将当前对象的非静态字段复制到该新对象,无论该字段是值类型的还是引用类型,都复制独立的一份。当你修改其中一个对象的任何内容时,都不会影响另一个对象的内容。
2、实现方法
① 让每个引用类型属性内部都重写clone()方法
② 利用序列化
序列化是将对象写到流中便于传输,而反序列化则是把对象从流中读取出来。这里写到流中的对象是原始对象的一个拷贝,因为原始对象还存在在JVM中,所以我们可以利用对象的序列化产生克隆对象,然后通过反序列化获取这个对象。
注意每个需要序列化的类都要实现serializable接口,如果有某个属性不需要序列化,可以将其声明为transient,即将其排除在克隆属性之外。
3、利用序列化完成深拷贝的代码实例
1 | |
此工具类要求被拷贝的对象实现serializable接口。
注:Apache下的Commons工具包中SerializationUtils类,直接使用更加简洁。
45:重写equals方法时不要识别不出自己
重写的equals方法做了多个校验,考虑到Web上传递过来的对象有可能输入了前后空格,所以用trim方法剪切了一下。
46:equals应该考虑null值情景
47:在equals中使用getClass进行类型判断
48:重写equals方法必须重写hashcode方法
为啥?官方解释没看懂。
49:推荐重写toString方法
Java提供的默认toString方法不友好,打印出来看不懂,不重写不行!
50:使用package-info类为包服务
package-info简称包文档,为包级文档和包级别注释提供一个地方,而且该文件唯一必须包含的是包的声明。
1、package-info的创建
2、package-info类不能继承,没有接口,没有类间关系等。
但package-info有啥用呢?只是对这个包的注释说明?
① 声明友好类和包内访问常量:
这个比较简单,而且很实用,比如一个包中有很多内部访问的类或常量,就可以统一放到package-info类中,这样很方便,便于集中管理,可以减少友好类到处游走的情况,代码如下:
1 | |
注意以上代码是放在package-info.java中的,虽然它没有编写package-info的实现,但是package-info.class类文件还是会生成。通过这样的定义,我们把一个包需要的常量和类都放置在本包下,在语义上和习惯上都能让程序员更适应。
② 为在包上提供注解提供便利:
比如我们要写一个注解(Annotation),查一下包下的对象,只要把注解标注到package-info文件中即可,而且很多开源项目中也采用了此方法,比如Struts2的@namespace、hibernate的@filterDef等。
③ 提供包的整体注释说明:
如果是分包开发,也就是说一个包实现了一个业务逻辑或功能点或模块或组件,则该包需要一个很好的说明文档,说明这个包是做什么用的,版本变迁历史,与其他包的逻辑关系等,package-info文件的作用在此就发挥出来了,这些都可以直接定义到此文件中,通过javadoc生成文档时,会吧这些说明作为包文档的首页,让读者更容易对该包有一个整体的认识。
51:不要主动进行垃圾回收
System.gc要停止所有的响应,才能检查内存中是否存在可以回收的对象,这对一个应用系统来说风险极大。
