05-23条数组与集合高质量准则
如果你浪费了自己的年龄,那是挺可悲的。因为你的青春只能持续一点儿时间——很短的一点儿时间。 —— 王尔德
60:性能考虑,数组是首选
数组在实际的系统开发中用的越来越少了,我们通常只有在阅读一些开源项目时才会看到它们的身影,在Java中它确实没有List、Set、Map这些集合类用起来方便,但是在基本类型处理方面,数组还是占优势的,而且集合类的底层也都是通过数组实现的,比如对一数据集求和这样的计算:
1 | |
原理:
1 | |
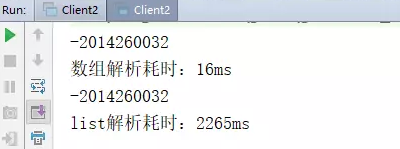
对一个int类型 的数组求和,取出所有数组元素并相加,此算法中如果是基本类型则使用数组效率是最高的,使用集合则效率次之。
再看使用List求和:
1 | |
注意看sum+=datas.get(i);这行代码,这里其实做了一个拆箱动作,Interger对象通过intValue方法自动转换成一个int基本类型,对于性能濒于临界的系统来说该方案很危险,特别是大数据量的时候,首先,在初始化list数组时都会进行装箱操作,把一个int类型包装成一个interger对象,虽然有整型池在,但不在整型池范围内的都会产生一个新的interger对象,众所周知,基本类型是在栈内存中操作的,而对象是在堆内存中操作的,栈内存的有点:速度快,容量小;堆内存的特点:速度慢,容量大。其次,在进行求和运算时,要做拆箱操作,性能消耗又产生了。对基本类型进行求和运算时,数组的效率是集合的10倍。
注:对性能要求高的场景中使用数组代替集合。
61:若有必要,使用变长数组
Java中的数组是定长的,一旦经过初始化声明就不可改变长度,这在实际使用中非常不方便。
数组也可以变长:
1 | |

1 | |
通过这样的处理方式,曲折的解决了数组的变长问题,其实,集合的长度自动维护功能的原理与此类似。在实际开发中,如果确实需要变长的数据集,数组也是在考虑范围之内的,不能因固定长度而将其否定之。
62:警惕数组的浅拷贝
1 | |
第二个箱子里最后一个气球的颜色毫无疑问是被修改为蓝色了,不过我们是通过拷贝第一个箱子里的气球然后再修改的方式来实现的,那会对第一个箱子的气球颜色有影响吗?我们看看输出结果:
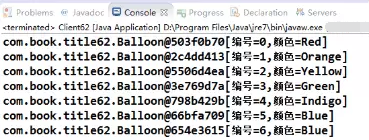
最后一个气球颜色竟然也被修改了,我们只是希望修改第二个箱子的气球啊,这是为何?这是典型的浅拷贝(Shallow Clone)问题,以前第一章序列化时讲过,但是这里与之有一点不同:数组中的元素没有实现Serializable接口。
确实如此,通过copyof方法产生的数组是一个浅拷贝,这与序列化的浅拷贝完全相同:基本类型直接拷贝值,引用类型时拷贝引用地址。
数组的clone同样也是浅拷贝,集合的clone也是浅拷贝。
问题找到了,解决起来也很简单,遍历box1的每个元素,重新生成一个气球对象,并放到box2数组中。
集合list进行业务处理时,需要拷贝集合中的元素,可集合没有提供拷贝方法,自己写很麻烦,干脆使用list.toArray方法转换成数组,然后通过arrays.copyof拷贝,再转回集合,简单边界!但非常遗憾,有时这样会产生浅拷贝的问题。
63:在明确的场景下,为集合指定初始容量
我们经常使用ArrayList、Vector、HashMap等集合,一般都是直接用new跟上类名声明出一个集合来,然后使用add、remove等方法进行操作,而且因为它是自动管理长度的,所以不用我们特别费心超长的问题,这确实是一个非常好的优点,但也有我们必须要注意的事项。
1 | |
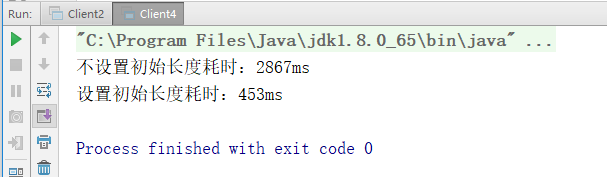
如果不设置初始容量,ArrayList的默认初始容量是10,系统会按照1.5倍的规则扩容,每次扩容都是一次数组的拷贝,如果数组量大,这样的拷贝会非常消耗资源,而且效率非常低下。所以,要设置一个ArrayList的可能长度,可以显著提升系统性能。
其它集合也类似,Vector扩容2倍。
64:多种最值算法,适时选择
对一批数据进行排序,然后找出其中的最大值或最小值,这是基本的数据结构知识。在Java中我们可以通过编写算法的方式,也可以通过数组先排序再取值的方式来实现,下面以求最大值为例,解释一下多种算法:
1 | |

从效率上将,快速查找法更快一些,只用遍历一次就可以计算出最大值,但在实际测试中发现,如果数组量少于10000,两个基本上没有区别,但在同一个毫秒级别里,此时就可以不用自己写算法了,直接使用数组先排序后取值的方式。
如果数组元素超过10000,就需要依据实际情况来考虑:自己实现,可以提高性能;先排序后取值,简单,通俗易懂。排除性能上的差异,两者都可以选择,甚至后者更方便一些,也更容易想到。
总结一下,数据量不是很大时(10000左右),使用先排序后取值比较好,看着高大上?总比自己写代码好!,数据量过大,出于性能的考虑,可以自己写排序方法!
感觉这条有点吹毛求疵了!
那如果要查找仅次于最大值的元素(也就是老二),该如何处理呢?要注意,数组的元素时可以重复的,最大值可能是多个,所以单单一个排序然后取倒数第二个元素时解决不了问题的。
此时,就需要一个特殊的排序算法了,先要剔除重复数据,然后再排序,当然,自己写算法也可以实现,但是集合类已经提供了非常好的方法,要是再使用自己写算法就显得有点重复造轮子了。数组不能剔除重复数据,但Set集合却是可以的,而且Set的子类TreeSet还能自动排序,代码如下:
1 | |
注:
① treeSet.lower()方法返回集合中小于指定值的最大值。
② 最值计算使用集合最简单,使用数组性能最优。
65:避开基本类型数组转换列表陷阱
我们在开发中经常会使用Arrays和Collections这两个工具类和列表之间转换,非常方便,但也有时候会出现一些奇怪的问题,来看如下代码:
1 | |
也许你会说,这很简单,list变量的元素数量当然是5了。但是运行后打印出来的列表数量为1。
事实上data确实是一个有5个元素的int类型数组,只是通过asList转换成列表后就只有一个元素了,这是为什么呢?其他4个元素到什么地方去了呢?
我们仔细看一下Arrays.asList的方法说明:输入一个变长参数,返回一个固定长度的列表。注意这里是一个变长参数,看源码:
1 | |
asList方法输入的是一个泛型变长参数,基本类型是不能泛型化的,也就是说8个基本类型不能作为泛型参数,要想作为泛型参数就必须使用其所对应的包装类型。
解决方法:
1 | |
把int替换为Integer即可让输出元素数量为5.需要说明的是,不仅仅是int类型的数组有这个问题,其它7个基本类型的数组也存在相似的问题,这就需要大家注意了,在把基本类型数组转换为列表时,要特别小心asList方法的陷阱,避免出现程序逻辑混乱的情况。
66:asList方法产生的List对象不可修改
上一个建议指出了asList方法在转换基本类型数组时存在的问题,接着我们看一下asList方法返回的列表有何特殊的地方,代码如下:
1 | |
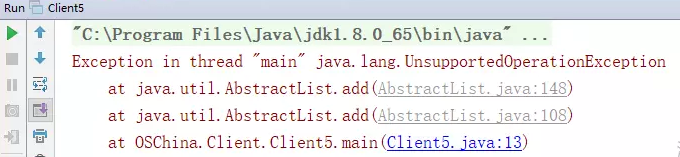
UnsupportedOperationException,不支持的操作,居然不支持list的add方法,这是什么原因呢?
此ArrayList非java.util.ArrayList,而是Arrays工具类的一个内部类
我们深入地看看这个ArrayList静态内部类,它仅仅实现了5个方法:
① size:元素数量
② get:获得制定元素
③ set:重置某一元素值
④ contains:是否包含某元素
⑤ toArray:转化为数组,实现了数组的浅拷贝
对于我们经常使用list.add和list.remove方法它都没有实现,也就是说asList返回的是一个长度不可变的列表,数组是多长,转换成的列表也就是多长,换句话说此处的列表只是数组的一个外壳,不再保持列表的动态变长的特性,这才是我们关注的重点。有些开发人员喜欢这样定义个初始化列表:
1 | |
一句话完成了列表的定义和初始化,看似很便捷,却隐藏着重大隐患—列表长度无法修改。想想看,如果这样一个List传递到一个允许添加的add操作的方法中,那将会产生何种结果,如果有这种习惯的javaer,请慎之戒之,除非非常自信该List只用于只读操作。
67:不同的列表选择不同的遍历算法
测试来看简单for循环比foreach能快那么一丢丢。
68:频繁插入和删除时使用LinkedList
ArrayList在进行插入元素时:
1 | |
注意看arrayCopy方法,只要插入一个元素,其后的元素就会向后移动一位,虽然arrayCopy是一个本地方法,效率非常高,但频繁的插入,每次后面的元素都要拷贝一遍,效率变的就低了。而使用LinkedList就显得更好了,LinkedList是一个双向列表,它的插入只是修改了相邻元素的next和previous引用。
原理不说了。
修改元素:LinkedList不如ArrayList,因为LinkedList是按顺序存储的,因此定位元素必然是一个遍历过程,效率大打折扣。而ArrayList的修改动作是数组元素的直接替换,简单高效。
LinkedList:删除和插入效率高;ArrayList:修改元素效率高。
69:列表相等只关心元素数据
判断集合是否相等只须关注元素是否相等即可,不用看容器
70:子列表只是原列表的一个视图
List接口提供了subList方法,其作用是返回一个列表的子列表,这与String类subSting有点类似。
注意:subList产生的列表只是一个视图,所有的修改动作直接作用于原列表。
71:推荐使用subList处理局部列表
我们来看这样一个简单的需求:一个列表有100个元素,现在要删除索引位置为20~30的元素。这很简单,一个遍历很快就可以完成,代码如下:
1 | |
这段代码很符合我的风格!
下面用subList解决这个问题:
1 | |
72:生成子列表后不要再操作原列表
注意:subList生成子列表后,保持原列表的只读状态。
73:使用Comparator进行排序
1、默认排序
Collections.sort(list)
2、按某字段排序
Collections.sort(list,new PositionComparator())
74:不推荐使用binarySearch对列表进行检索
不推荐,干脆就不要写了,好吗?
对列表进行检索就使用indexOf就挺好的!
1 | |
binarySearch采用的是二分法搜索的Java版实现。从中间开始搜索,结果肯定是2了。
使用binarySearch的二分法查找比indexOf的遍历算法性能上高很多,特别是在大数据集且目标值又接近尾部时,binarySearch方法与indexOf方法相比,性能上会提升几十倍,因此从性能的角度考虑时可以选择binarySearch。
75:集合中的元素必须做到compareTo和equals同步
一看到标题,短时间有些发懵,简单来说,
indexOf依赖equals方法查找,binarySearch则依赖compareTo方法查找;
equals是判断元素是否相等,compareTo是判断元素在排序中的位置是否相同。
注意:实现了compareTo方法就应该覆写equals方法,确保两者同步。
76:集合运算的并集、交集、差集
1、并集 addAll
2、交集 retainAll
3、差集 removeAll
4、无重复的并集
并集是集合A加集合B,那如果集合A和集合B有交集,就需要确保并集的结果中只有一份交集,此为无重复的并集,此操作也比较简单,代码如下:
1 | |
之所以介绍并集、交集、差集,那是因为在实际开发中,很少有使用JDK提供的方法实现集合这些操作,基本上都是采用了标准的嵌套for循环:要并集就是加法,要交集就是contains判断是否存在,要差集就使用了!contains(不包含)。
之所以会写这么low的东西是想告诫自己多用JDK提供的方法,不要总想着自己去实现,很多东西Java老贼都有现成的!
77:使用shuffle打乱列表
简而言之,言而总之,shuffle就是用来打乱list列表顺序的,应用的场景比如
1、在抽奖程序中:比如年会的抽奖程序,先使用shuffle把员工顺序打乱,每个员工的中奖几率相等,然后就可以抽出第一名、第二名。
2、用于安全传输方法:比如发送端发送一组数据,先随机打乱顺序,然后加密发送,接收端解密,然后进行排序!
78:减少hashmap中元素的数量
1、hashmap和ArrayList的长度都是动态增加的,二者机制有些不同
2、先说hashmap,它在底层是以数组的方式保存元素的,其中每一个键值对就是一个元素,也就是说hashmap把键值对封装成一个entry对象,然后再将entry对象放到数组中,也就是说hashmap比ArrayList多一层封装,多出一倍的对象。
在插入键值对时会做长度校验,如果大于或者等于阈值,则数组长度会增大一倍。
hashMap的size大于数组的0.75倍时,就开始扩容,一次扩容两倍。
3、ArrayList的扩容策略,它是在小于数组长度的时候才会扩容1.5倍。
综合来说,HashMap比ArrayList多了一层Entry的底层封装对象,多占用了内存,并且它的扩容策略是2倍长度的递增,同时还会根据阈值判断规则进行判断,因此相对于ArrayList来说,同样的数据,它就会优先内存溢出。
注:Entry是Map中用来保存一个键值对的,而Map实际上就是多个Entry的集合。
79:集合中哈希码不要重复
1、Java中hashcode的理解
JVM每new一个Object,都会在Hash哈希表中产生一个hashcode。假设不同的对象产生了相同的hashcode,hash key相同导致冲突,那么就在这个hash key的地方产生了一个链表,将同样hashcode的对象放到单链表中,串到一起。
重写equals时一定要重写hashcode方法
两个相等对象的equals方法一定为true, 但两个hashcode相等的对象不一定是相等的对象。
hashcode相等仅仅保证两个对象在hash表里的同一个hash链上,继而通过equals方法才能确定是不是同一个对象。
总而言之,hashmap中hashcode应避免冲突。
80:多线程使用Vector或HashTable
Vector是ArrayList的多线程版本,HashTable是HashMap的多线程版本。
81:非稳定排序推荐使用List
什么叫非稳定排序?
1 | |

奇了怪了,为什么呢?这个就是非稳定排序。
SortedSet接口(TreeSet实现了此接口)只是定义了在给集合加入元素时将其进行排序,并不能保证元素修改后的排序结果,因此TreeSet适用于不变量的集合数据排序。
解决方法:
1、Set集合重排序:重新生成一个Set对象,再排序。
1 | |
感觉如果这么写就失去了代码了乐趣了,太愚蠢了,pass。
2、使用List解决
使用Collections.sort()方法对List排序。
list中允许有重复的元素,避免重复可以先转成HashSet,去重后再转回来。
82:由点及面,集合大家族总结
Java中的集合类实在是太丰富了,有常用的ArrayList、HashMap,也有不常用的Stack、Queue,有线程安全的Vector、HashTable,也有线程不安全的LinkedList、TreeMap,有阻塞式的ArrayBlockingQueue,也有非阻塞式的PriorityQueue等,整个集合大家族非常庞大,可以划分以下几类:
1、List:
实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack,其中ArrayList是一个动态数组,LinkedList是一个双向链表,Vector是一个线程安全的动态数组,Stack是一个对象栈,遵循先进后出的原则。
stack简介:
Stack来自于Vector,那么显然stack的底层实现是数组。
stack的方法:
① push(xx); //入栈
② pop() ; //栈顶元素出栈
③ empty() ; //判定栈是否为空
④ peek(); //获取栈顶元素
⑤ search(xx); //判端元素num是否在栈中,如果在返回1,不在返回-1。
2、Set:
Set是不包含重复元素的集合,其主要实现类有:EnumSet、HashSet、TreeSet,其中EnumSet是枚举类型专用Set,所有元素都是枚举类型;HashSet是以哈希吗决定其元素位置的Set,其原理和hashmap相似,它提供快速的插入和查找方法;TreeSet是一个自动排序的Set,它实现了SortedSet接口。
3、Map:
HashMap、HashTable、Properties、EnumMap、TreeMap等。
其中properties是hashtable的子类,它的主要用途是从property文件中加载数据,并提供方便的操作,EnumMap则要求其key必须是一个枚举类型。
map中还有一个WeakHashMap类需要简单说明一下,它是一个采用弱键方式的map类,它的特点是:WeakHashMap对象的存在并不会阻止垃圾回收器对键值对的回收,也就是说使用WeakHashMap不用担心内存溢出的问题,GC会自动删除不用的键值对,但存在一个严重的问题:GC是静悄悄的回收的(何时回收,God,Knows!)我们的程序无法知晓该动作,存在着重大的隐患。
WeakHashMap存在重大隐患,那这个东西什么时候使用呢?
在《Effective Java》一书中第六条,消除陈旧对象时,提到了weakHashMap,使用短时间内就过期的缓存时最好使用weakHashMap。
4、Queue:
5、数组:
数组与集合的最大区别是数组能够容纳基本类型,而集合只能容纳引用类型,所有的集合底层存储的都是数组。
