日光之下,并无新事。 —— 《圣经》
83:推荐使用枚举定义常量 常量声明是每一个项目都不可或缺的,在Java1.5之前,我们只有两种方式的声明:类常量和接口常量。不过,在1.5版本以后有了改进,即新增了一种常量声明方式:枚举声明常量,看如下代码:
1 2 3 enum Season {
提倡枚举项全部大写,字母之间用下划线分割,这也是从常量的角度考虑的。
那么枚举常量与我们经常使用的类常量和静态常量相比有什么优势?问得好,枚举的优点主要表现在四个方面:
1、枚举常量简单
2、枚举常量属于稳态型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void describe (int s) {if (s >= 0 && s < 4 ) {switch (s) {case Season.SPRING:"this is spring" );break ;case Season.SUMMER:"this is summer" );break ;
对输入值的检查很吃力。
1 2 3 4 5 6 7 8 9 10 11 public void describe (Season s) {switch (s){case Spring:"this is " +Season.Spring);break ;case Summer:"this is summer" +Season.Summer);break ;
不用校验,已经限定了是Season枚举。
3、枚举具有内置方法
1 2 3 4 5 public void query () {for (Season s : Season.values()) {
通过values方法获得所有的枚举项。
4、枚举可以自定义方法
关键是枚举常量不仅可以定义静态方法,还可以定义非静态方法。
虽然枚举在很多方面比接口常量和类常量好用,但是有一点它是比不上接口常量和类常量的,那就是继承,枚举类型是不能继承的,也就是说一个枚举常量定义完毕后,除非修改重构,否则无法做扩展,而接口常量和类常量则可以通过继承进行扩展。但是,一般常量在项目构建时就定义完毕了,很少会出现必须通过扩展才能实现业务逻辑的场景。
注意:在项目中推荐使用枚举常量代替接口常量或类常量
84:使用构造函数协助描述枚举项 枚举描述:通过枚举的构造函数,声明每个枚举项必须具有的属性和行为,这是对枚举项的描述和补充。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 enum Role {"管理员" , new LifeTime (), new Scope ()), User("普通用户" , new LifeTime (), new Scope ());private String name;private LifeTime lifeTime;private Scope scope;class LifeTime {class Scope {
这是一个角色定义类,描述了两个角色:管理员和普通用户,同时它还通过构造函数对这两个角色进行了描述:
1、name:表示的是该角色的中文名称
2、lifeTime:表示的是该角色的生命周期,也就是多长时间该角色失效
3、scope:表示的该角色的权限范围
这样一个描述可以使开发者对Admin和User两个常量有一个立体多维度的认知,有名称,有周期,还有范围,而且还可以在程序中方便的获得此类属性。所以,推荐大家在枚举定义中为每个枚举项定义描述,特别是在大规模的项目开发中,大量的常量定义使用枚举项描述比在接口常量或类常量中增加注释的方式友好的多,简洁的多。
85:小心switch带来的空指针异常 使用枚举定义常量时。会伴有大量switch语句判断,目的是为了每个枚举项解释其行为,例如这样一个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static void doSports (Season season) {switch (season) {case Spring:"春天放风筝" );break ;case Summer:"夏天游泳" );break ;case Autumn:"秋天是收获的季节" );break ;case Winter:"冬天滑冰" );break ;default :"输出错误" );break ;public static void main (String[] args) {null );"main" java.lang.NullPointerException8 )28 )
输入null时应该default的啊,为什么空指针异常呢?
目前Java中的switch语句只能判断byte、short、char、int类型(JDk7允许使用String类型),这是Java编译器的限制。问题是为什么枚举类型也可以跟在switch后面呢?
因为编译时,编译器判断出switch语句后跟的参数是枚举类型,然后就会根据枚举的排序值继续匹配,也就是或上面的代码与以下代码相同:
1 2 3 4 5 6 7 8 9 10 11 public static void doSports (Season season) {switch (season.ordinal()) {case season.Spring.ordinal():"春天放风筝" );break ;case season.Summer.ordinal():"夏天游泳" );break ;
switch语句是先计算season变量的排序值,然后与枚举常量的每个排序值进行对比,在我们的例子中season是null,无法执行ordinal()方法,于是就报空指针异常了。问题清楚了,解决很简单,在doSports方法中判断输入参数是否为null即可。
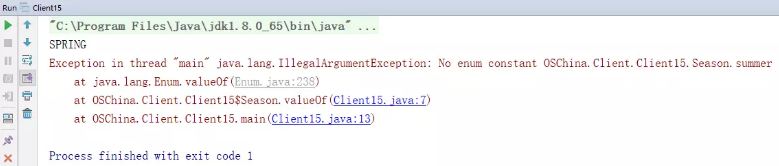
86:在switch的default代码块中增加AssertError错误 87:使用valueOf前必须进行校验 我们知道每个枚举项都是java.lang.Enum的子类,都可以访问Enum类提供的方法,比如hashCode、name、valueOf等,其中valueOf方法会把一个String类型的名称转换为枚举项,也就是在枚举项中查找出字面值与参数相等的枚举项。虽然这个方法简单,但是JDK却做了一个对于开发人员来说并不简单的处理,我们来看代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import java.util.Arrays;import java.util.List;public class Client15 {enum Season {public static void main (String[] args) {"SPRING" ,"summer" );for (String name:params){Season s = Season.valueOf(name);if (null !=s){else {"无相关枚举项" );
看着没问题啊,summer不在Season里,就输出无相关枚举项就完事了嘛。。。
valueOf方法先通过反射从枚举类的常量声明中查找,若找到就直接返回,若找不到排除无效参数异常。valueOf本意是保护编码中的枚举安全性,使其不产生空枚举对象,简化枚举操作,但却引入了一个无法避免的IllegalArgumentException异常。
解决此问题的方法:
1、抛异常
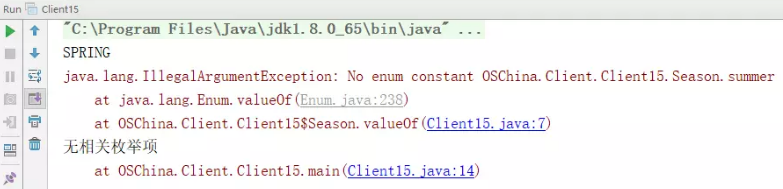
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.util.Arrays;import java.util.List;public class Client15 {enum Season {public static void main (String[] args) {"SPRING" ,"summer" );try {for (String name:params){Season s = Season.valueOf(name);catch (IllegalArgumentException e){"无相关枚举项" );
2、扩展枚举类:
枚举中是可以定义方法的,那就在枚举项中自定义一个contains方法就可以。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.util.Arrays;import java.util.List;public class Client15 {enum Season {public static boolean contains (String name) {for (Season s:Season.values()){if (s.name().equals(name)){return true ;return false ;public static void main (String[] args) {"SPRING" ,"summer" );for (String name:params){if (Season.contains(name)){Season s = Season.valueOf(name);else {"无相关枚举项" );
个人感觉第二种方法更好一些!
88:用枚举实现工厂方法模式更简洁 工厂方法模式是“创建对象的接口,让子类决定实例化哪一个类,并使一个类的实例化延迟到其它子类”。工厂方法模式在我们的开发中经常会用到。下面以汽车制造为例,看看一般的工厂方法模式是如何实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 interface Car {class FordCar implements Car {class BuickCar implements Car {class CarFactory {public static Car createCar (Class<? extends Car> c) {try {return c.newInstance();catch (InstantiationException | IllegalAccessException e) {return null ;
这是最原始的工厂方法模式,有两个产品:福特汽车和别克汽车,然后通过工厂方法模式来生产。有了工厂方法模式,我们就不用关心一辆车具体是怎么生成的了,只要告诉工厂” 给我生产一辆福特汽车 “就可以了,下面是产出一辆福特汽车时客户端的代码:
1 2 3 4 public static void main (String[] args) {Car car = CarFactory.createCar(FordCar.class);
这就是我们经常使用的工厂方法模式,但经常使用并不代表就是最优秀、最简洁的。此处再介绍一种通过枚举实现工厂方法模式的方案,谁优谁劣你自行评价。枚举实现工厂方法模式有两种方法:
1、枚举非静态方法实现工厂方法模式
我们知道每个枚举项都是该枚举的实例对象,那是不是定义一个方法可以生成每个枚举项对应产品来实现此模式呢?代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum CarFactory {public Car create () {switch (this ) {case FordCar:return new FordCar ();case BuickCar:return new BuickCar ();default :throw new AssertionError ("无效参数" );
create是一个非静态方法,也就是只有通过FordCar、BuickCar枚举项才能访问。采用这种方式实现工厂方法模式时,客户端要生产一辆汽车就很简单了,代码如下:
1 2 3 4 public static void main (String[] args) {Car car = CarFactory.BuickCar.create();
2、通过抽象方法生成产品
枚举类型虽然不能继承,但是可以用abstract修饰其方法,此时就表示该枚举是一个抽象枚举,需要每个枚举项自行实现该方法,也就是说枚举项的类型是该枚举的一个子类,我们来看代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum CarFactory {public Car create () {return new FordCar ();public Car create () {return new BuickCar ();public abstract Car create () ;
首先定义一个抽象制造方法create,然后每个枚举项自行实现,这种方式编译后会产生CarFactory的匿名子类,因为每个枚举项都要实现create抽象方法。客户端调用与上一个方案相同,不再赘述。
大家可能会问,为什么要使用枚举类型的工厂方法模式呢?那是因为使用枚举类型的工厂方法模式有以下三个优点:
1、避免错误调用的发生:一般工厂方法模式中的生产方法,可以接收三种类型的参数:类型参数、String参数、int参数,这三种参数都是宽泛的数据类型,很容易发生错误(比如边界问题、null值问题),而且出现这类错误编辑器还不会报警,例如:
1 2 3 4 public static void main (String[] args) {Car car = CarFactory.createCar(Car.class);
Car是一个接口,完全合乎createCar的要求,所以它在编译时不会报任何错误,但一运行就会报出InstantiationException异常,而使用枚举类型的工厂方法模式就不存在该问题了,不需要传递任何参数,只需要选择好生产什么类型的产品即可。
2、性能好,使用简洁:枚举类型的计算时以int类型的计算为基础,这是最基本的操作,性能当然会快,至于使用便捷,注意看客户端的调用,代码的字面意思是“汽车工厂,我们要一辆别克汽车,赶快生产”。
3、降低类间耦合:不管生产方法接收的是class、string还是int的参数,都会成为客户端类的负担,这些类并不是客户端需要的,而是因为工厂方法的限制必须输入,例如class参数,对客户端main方法来说,它需要传递一个fordCar.class参数才能生产一台福特汽车,除了在create方法中传递参数外,业务类不需要改car的实现类。这严重违反了迪克特原则,也就是最少知识原则:一个对象该对其它对象有最少的了解。
而枚举类型的工厂方法就没有这种问题,它只需要依赖工厂类就可以生产一辆符合接口的汽车,完全可以无视具体汽车类的存在。
89:枚举类的数量限制在64个以内 为了更好地使用枚举,Java提供了两个枚举集合:EnumSet和EnumMap,这两个集合使用的方法都比较简单,EnumSet表示其元素必须是某一枚举的枚举项,EnumMap表示Key值必须是某一枚举的枚举项,由于枚举类型的实例数量固定并且有限,相对来说EnumSet和EnumMap的效率会比其它Set和Map要高。
注意:枚举项数量不要超过64,否则建议拆分。
90:小心继承注解 Java从1.5版本开始引入注解(Annotation),@Inheruted,它表示一个注解是否可以自动继承。
91:枚举和注解结合使用威力更大 注解的写法和接口很相似,都采用关键字interface,而且都不能有实现代码,常量定义默认都是public static final类型的,它们的主要不同点是:注解要在interface前加@字符,而且不能继承,不能实现。
我们举例说明一下,以访问权限列表为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 interface Identifier {String REFUSE_WORD = "您无权访问" ;public boolean identify () ;package OSChina.reflect;public enum CommonIdentifier implements Identifier {@Override public boolean identify () {return false ;package OSChina.reflect;import java.lang.annotation.ElementType;import java.lang.annotation.Retention;import java.lang.annotation.RetentionPolicy;import java.lang.annotation.Target;@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) public @interface Access {level () default CommonIdentifier.Admin;package OSChina.reflect;@Access(level=CommonIdentifier.Author) public class Foo {package OSChina.reflect;public class Test {public static void main (String[] args) {Foo b = new Foo ();Access access = b.getClass().getAnnotation(Access.class);if (null == access || !access.level().identify()) {
看看上面的代码,简单易懂,所有的开发人员只要增加注解即可解决访问控制问题。
92:注意@override不同版本的区别 @Override注解用于方法的覆写上,它是在编译器有效,也就是Java编译器在编译时会根据注解检查方法是否真的是覆写,如果不是就报错,拒绝编译。