09-索引和存储过程

1. 数据库索引
- 概念
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护者满足特定查找算法的数据结构,这些数据结构以某 种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
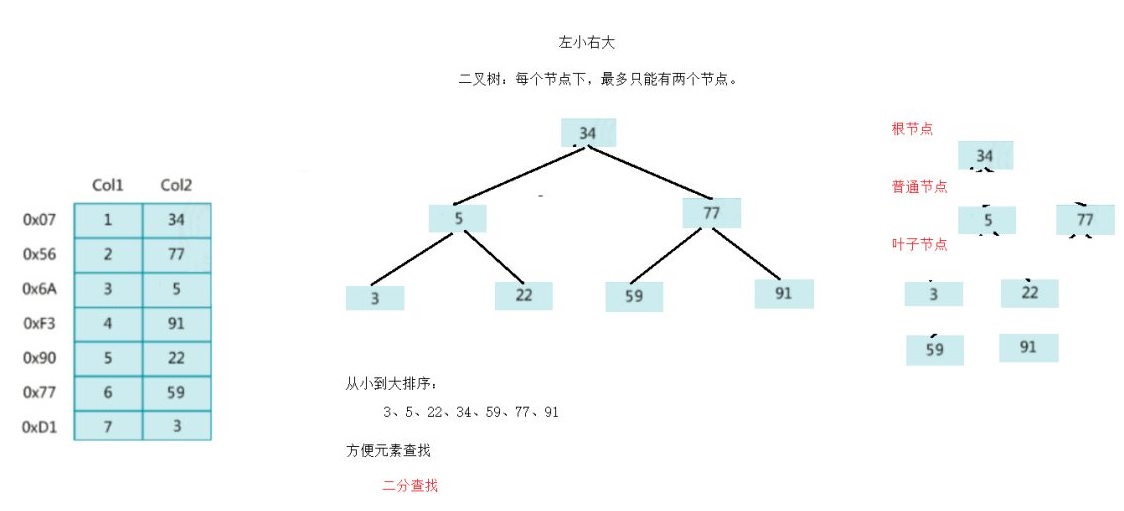
如图,左边是
数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的 记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就 可以运用二分查找快速获取到相应数据。
- 索引为什么可以大幅提升查询效率?
- 可以将索引看作一本书的目录。
- 设想一下要是 没有目录,那么我们就要一页一页进行查找,如果我们所需要的是这本书的最后一页,那么 就太费时了。
1.1 优势和劣势
- 优势
- 提高了记录查询的速度
- 提高了记录排序的效率
- 劣势
- 索引占用了空间
- 索引会降低DML(增删改)操作的速度
1.2 索引结构
- 索引是在MySQL的
存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引 都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型的。MySQL目前提供了以下4 种索引:- B+TREE 索引
- Hash 索引
- R-TREE 索引
- FULL-TEXT 索引
- 主要使用的索引结果是 **
B+TREE 索引**。
1.3 B+TREE结构
- B+TREE 结构又叫
多路平衡索引树,一颗 m 叉的 B+Tree 特性如下:- 树中每个节点最多包含m个孩子。
- 除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子。
- 若根节点不是叶子节点,则至少有两个孩子。
- 所有的叶子节点都在同一层。
- 每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
- 以5叉 B+Tree 为例,key的数量:公式推导[ceil(m/2)-1] <= n <= m-1。所以 2 <= n <=4 。当 n>4时,中间节点分裂到父节点,两边节点分裂。
1.4 索引分类
- 唯一索引:索引字段的值必须唯一
- 单值索引:所以只包含一个字段
- 复合索引:索引包含多个字段
1.5 索引语法
- 查看索引:
show index from 表名; - 创建索引:
create index 索引名 on 表名 (字段名1,字段名2...); - 删除索引:
alter table 表名 drop index 索引名; - 注意事项:查询多,增删改,就适合使用索引;否则不适合。
索引名:一般格式为
idx_字段名
1.6 联合索引
1 | |
1 | |
创建联合索引前后,使用 explain 查看 sql语句的执行计划,从结果中看是否命中索引,以及扫描行数 rows(越少越好)。
2. 数据库存储过程
概念
- 就是在数据库端存储一个已经编译好的SQL语句
作用
- 如果没有使用存储过程,存在的问题
- SQL语句从服务器传输到数据库时,存在安全问题
- 数据库执行SQL语句时,每次都要进行编译再运行,效率一般
- 如果使用
存储过程,就可以解决以上两个问题。
- 如果没有使用存储过程,存在的问题
使用场景
- 通常,复杂的业务逻辑需要多条 SQL 语句。这些语句要分别地从客户机发送到服务器,当客户机和服务器之间的操作很多时,将产生大量的网络传输。如果将这些操作放在一个存储过程中,那么客户机和服务器之间的网络传输就会大大减少,降低了网络负载。
优点
- 存储过程只在创建时进行编译,以后每次执行存储过程都不需再重新编译,而一般 SQL语句每执行一次就编译一次,因此使用存储过程可以大大
提高数据库执行速度。 - 存储过程创建一次便可以
重复使用,从而可以减少数据库开发人员的工作量。 安全性高,存储过程可以屏蔽对底层数据库对象的直接访问,使用 EXECUTE 权限调用存储过程,无需拥有访问底层数据库对象的显式权限。正是由于存储过程的上述优点,目前常用的数据库都支持存储过程,例如 IBM DB2,Microsoft SQL Server,Oracle,Access 等,开源数据库系统 MySQL 也在 5.0 的时候实现了对存储过程的支持。
- 存储过程只在创建时进行编译,以后每次执行存储过程都不需再重新编译,而一般 SQL语句每执行一次就编译一次,因此使用存储过程可以大大
2.1 语法
- 创建存储过程,并执行:
create procedure
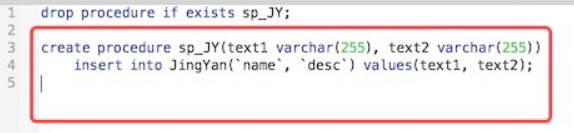
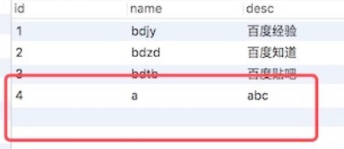
- 查询确认数据

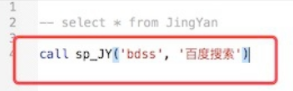
- 调用存储过程:
call
- 环境准备
1 | |
语法
- 创建存储过程
1 | |
- 调用存储过程
1 | |
需求1
- 将id为1的用户的年龄修改为28岁
1 | |
需求2
- 给指定id的用户修改为指定年龄
1 | |
需求3
- 统计用户人数
1 | |
类似于 函数 的写法。

09-索引和存储过程
https://janycode.github.io/2017/06/18/05_数据库/01_MySQL/09-索引和存储过程/