什么是负载均衡
负载均衡是指多台服务器以对称的方式组成一个服务器集群,每台服务器的地位相当(但不同的服务器可能性能不同),可以独立提供服务,无需其他服务器的辅助。为了保证系统的可扩展性,需要有一种算法能够将系统负载平均分配给集群中的每台服务器,这种算法称为负载均衡算法。
负责执行负载均衡算法并平均分配请求的服务器称为负载均衡器。
1. 随机算法
随机算法非常简单,该算法的核心是通过随机函数随机获取一个服务器进行访问。假设现在有四台服务器,192.168.1.1~ 192.168.1.4, 该算法用java实现大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class RandomTest {
private static final List<String> servers = Arrays.asList("192.168.1.1", "192.168.1.2", "192.168.1.3", "192.168.1.4");
public static String getServer() {
Random random = new Random();
int index = random.nextInt(servers.size());
return servers.get(index);
}
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
String server = getServer();
System.out.println("select server: "+server);
}
}
}
|
当样本较小时,算法可能分布不均匀,但根据概率论,样本越大,负载会越均匀,而负载均衡算法本来就是为应对高并发场景而设计的。该算法的另一个缺点是所有机器都有相同的访问概率, 如果服务器性能不同,负载将不平衡。
2. 轮询算法
Round-Robin轮询算法是另一种经典的负载均衡算法。请求以循环的方式分发到集群中的所有服务器。同理,对于上述四台服务器,假设客户端向集群发送10个请求,则请求分布将如下图所示:
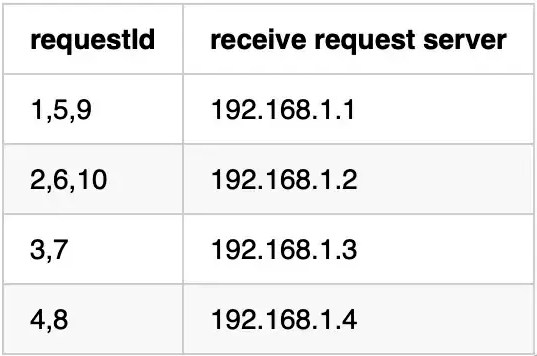
在十个请求中,第一、第五和第九个请求将分配给192.168.1.1,第二、第六和第十个请求将分配给192.168.1.2,依此类推。可以看到round-robin算法可以在集群中均匀的分配请求。但是,该算法具有与随机算法相同的缺点,如果服务器性能不同,负载将不平衡,因此需要加权轮询算法。
3. 加权轮询算法
Weighted Round-Robin加权轮询算法是在round-robin算法的基础上根据服务器的性能分配权重。服务器能支持的请求越多,权重就越高,分配的请求也就越多。对于同样的10个请求,使用加权轮询算法的请求分布会如下图所示:
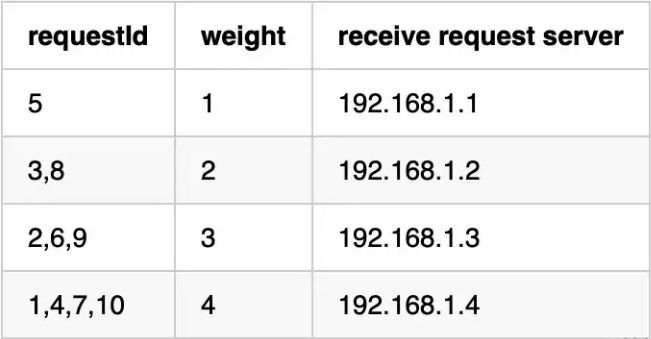
可以看到192.168.1.4权重最大,分配的请求数最多,java实现加权循环算法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| public class RoundRobinTest {
public class Node{
private String ip;
private Integer weight;
private Integer currentWeight;
public Node(String ip,Integer weight) {
this.ip = ip;
this.weight = weight;
this.currentWeight = weight;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public Integer getWeight() {
return weight;
}
public void setWeight(Integer weight) {
this.weight = weight;
}
public Integer getCurrentWeight() {
return currentWeight;
}
public void setCurrentWeight(Integer currentWeight) {
this.currentWeight = currentWeight;
}
}
List<Node> servers = Arrays.asList(
new Node("192.168.1.1",1),
new Node("192.168.1.2",2),
new Node("192.168.1.3",3),
new Node("192.168.1.4",4));
private Integer totalWeight;
public RoundRobinTest() {
this.totalWeight = servers.stream()
.mapToInt(Node::getWeight)
.reduce((a,b)->a+b).getAsInt();
}
public String getServer() {
Node node = servers.stream().max(Comparator.comparingInt(Node::getCurrentWeight)).get();
node.setCurrentWeight(node.getCurrentWeight()-totalWeight);
servers.forEach(server->server.setCurrentWeight(server.getCurrentWeight()+server.getWeight()));
return node.getIp();
}
public static void main(String[] args) {
RoundRobinTest roundRobinTest = new RoundRobinTest();
for (int i = 0; i < 10; i++) {
String server = roundRobinTest.getServer();
System.out.println("select server: "+server);
}
}
|
该算法的核心是的动态计算currentWeight。每个服务器被选中后,currentWeight需要减去所有服务器的权重之和,这样可以避免权重高的服务器一直被选中。权重高的服务器有更多的分配请求,请求可以平均分配给所有服务器。
4. 哈希算法
哈希算法,顾名思义,就是利用哈希表根据 计算出请求的路由hashcode%N。这里hashcode代表哈希值,N代表服务器数量。该算法的优点是实现起来非常简单。具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| private static final List<String> servers = Arrays.asList("192.168.1.1", "192.168.1.2", "192.168.1.3", "192.168.1.4");
public static String getServer(String key) {
int hash = key.hashCode();
int index = hash % servers.size();
return servers.get(index);
}
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
String server = getServer(String.valueOf(i));
System.out.println("select server: "+server);
}
}
|
哈希算法在很多缓存分布式存储系统中很常见,比如Memorycached和Redis,但是一般不会用到上面的哈希算法,而是优化后的一致性哈希算法。
其实可以发现nginx或者spring cloud中的ribbon都使用到了这样的算法思想。
