参考官网:https://jsoup.org/
jsoup 提供了简便的API,使用了HTML5 DOM方法和CSS选择器用来解析HTML。其实现了WHATWG HTML5 规范,像浏览器一样解析HTML。
- 从文件,URL,字符串抓取和解析HTML
- 使用DOM遍历或者CSS选择器来查找和提取数据
- 操作HTML元素,属性和文字
- 清除用户提交的安全白名单以外的内容,以防止XSS攻击
- 美化HTML
引入依赖
1
2
3
4
5
| <dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>
|
解析HTML
- 从字符串解析
1
2
3
| String html = "<html><head><title>First parse</title></head>"
+ "<body><p>Parsed HTML into a doc.</p></body></html>";
Document doc = Jsoup.parse(html);
|
- 从URL解析
1
2
3
4
5
6
7
8
9
10
11
12
|
Document doc = Jsoup.connect("http://example.com/").get();
String title = doc.title();
doc = Jsoup.connect("http://example.com")
.data("query", "Java")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36")
.cookie("auth", "token")
.timeout(3000)
.post();
|
- 从文件解析
1
2
| File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
|
提取HTML
1
2
3
4
5
6
7
8
9
| File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
|
1
2
3
4
5
6
7
8
9
10
11
| String html = "<p>An <a href='http://example.com/'><b>example</b></a> link.</p>";
Document doc = Jsoup.parse(html);
Element link = doc.select("a").first();
String text = doc.body().text();
String linkHref = link.attr("href");
String linkText = link.text();
String linkOuterH = link.outerHtml();
String linkInnerH = link.html();
|
- 相对路径转换成绝对路径,一些a标签使用的是相对路径,下面的代码可以将其转换成绝对路径
1
2
3
4
5
| Document doc = Jsoup.connect("http://jsoup.org").get();
Element link = doc.select("a").first();
String relHref = link.attr("href");
String absHref = link.attr("abs:href");
|
CSS选择器
Jsoup支持CSS选择器,用的是 Element.select(String selector)方法
1
2
3
4
5
6
7
8
9
10
11
| File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
Elements links = doc.select("a[href]");
Elements pngs = doc.select("img[src$=.png]");
Element masthead = doc.select("div.masthead").first();
Elements resultLinks = doc.select("h3.r > a");
|
如何快速定位页面上元素的内容?答案是打开Chrome,按F12打开开发者工具,定位到想要的DOM节点,右键,copy,选择Copy selector,即可生成CSS选择器,类似于body > div > div.content > div.col2 > div > h3:nth-child(10)
遗憾的是Jsoup不支持Xpath选择器,但是早就有人意识到这个问题了,所以诞生了JsoupXpath
JsoupXpath 是一款纯Java开发的使用xpath解析提取html数据的解析器,针对html解析完全重新实现了W3C XPATH 1.0标准语法,xpath的Lexer和Parser基于Antlr4构建,html的DOM树生成采用Jsoup,故命名为JsoupXpath. 为了在java里也享受xpath的强大与方便但又苦于找不到一款足够好用的xpath解析器,故开发了JsoupXpath。JsoupXpath的实现逻辑清晰,扩展方便, 支持完备的W3C XPATH 1.0标准语法,W3C规范:http://www.w3.org/TR/1999/REC-xpath-19991116 ,JsoupXpath语法描述文件Xpath.g4
项目地址:https://github.com/zhegexiaohuozi/JsoupXpath
感兴趣的可以看一下测试用例:里面包含了大量的使用场景:https://github.com/zhegexiaohuozi/JsoupXpath/blob/master/src/test/java/org/seimicrawler/xpath/JXDocumentTest.java
操作HTML
jsoup可以在插入、删除、提取HTML,直接看例子代码
1
2
3
|
doc.select("div.comments a").attr("rel", "nofollow");
doc.select("div.masthead").attr("title", "jsoup").addClass("round-box");
|
1
2
3
4
5
6
7
8
9
10
|
Element div = doc.select("div").first();
div.html("<p>lorem ipsum</p>");
div.prepend("<p>First</p>");
div.append("<p>Last</p>");
Element span = doc.select("span").first();
span.wrap("<li><a href='http://example.com/'></a></li>");
|
1
2
3
4
5
6
|
Element div = doc.select("div").first();
div.text("five > four");
div.prepend("First ");
div.append(" Last");
|
避免XSS攻击(cross-site scripting)
1
2
3
4
| String unsafe =
"<p><a href='http://example.com/' onclick='stealCookies()'>Link</a></p>";
String safe = Jsoup.clean(unsafe, Whitelist.basic());
|
csdn2md
使用 jsoup 爬虫爬取 csdn 的博客信息并同时转为 markdown 格式:
1. pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>csdn2md</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>6</source>
<target>6</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
</dependencies>
</project>
|
2. Csdn2MdUtil.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
| import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
@SuppressWarnings("all")
public class Csdn2MdUtil {
public static void main(String[] args) {
String csdnArticleUrl = "https://blog.csdn.net/qq_32828253/article/details/109412992";
climbDetailByUrl(csdnArticleUrl);
}
public static void climb(String userName) {
String baseUrl = "https://blog.csdn.net/" + userName + "/";
String secondUrl = baseUrl + "article/list/";
File file = new File("./_posts/");
if (!file.exists()) {
file.mkdir();
}
for (int i = 1; ; i++) {
String startUrl = secondUrl + i;
Document doc = null;
try {
doc = Jsoup.connect(startUrl).get();
} catch (IOException e) {
System.out.println("jsoup获取url失败" + e.getMessage());
}
Element element = doc.body();
element = element.select("div.article-list").first();
if (element == null) {
break;
}
Elements elements = element.children();
for (Element e : elements) {
String articleId = e.attr("data-articleid");
climbDetailById(baseUrl, articleId);
}
}
}
private static void climbOne(String userName, String articleId) {
System.out.println("》》》》》》》爬虫开始《《《《《《《");
String baseUrl = "https://blog.csdn.net/" + userName + "/";
String secondUrl = baseUrl + "article/list/";
File file = new File("./_posts/");
if (!file.exists()) {
file.mkdir();
}
System.out.println(articleId);
climbDetailById(baseUrl, articleId);
System.out.println("》》》》》》》爬虫结束《《《《《《《");
}
public static void climbDetailByUrl(String csdnUrl) {
File file = new File("./_posts/");
if (!file.exists()) {
file.mkdir();
}
String startUrl = csdnUrl;
Document doc = null;
try {
doc = Jsoup.connect(startUrl).get();
} catch (IOException e) {
System.out.println("jsoup获取url失败" + e.getMessage());
}
Element element = doc.body();
Element htmlElement = element.select("div#content_views").first();
Element titleElement = element.selectFirst(".title-article");
String fileName = titleElement.text();
System.out.println(fileName);
String jekyllTitle = "title: " + fileName + "\n";
Elements elements = element.select("div.tags-box");
String jekyllCategories = "";
if (elements.size() > 1) {
jekyllCategories = "categories:\n";
jekyllCategories = getTagsBoxValue(elements, 1, jekyllCategories);
}
String jekyllTags = "tags:\n";
jekyllTags = getTagsBoxValue(elements, 0, jekyllTags);
Element timeElement = element.selectFirst("span.time");
String time = timeElement.text().substring(5);
System.out.println(time);
String jekyllDate = "date: " + time + "\n";
String md = Html2MdUtil.getMarkDownText(htmlElement);
System.out.println(md);
String jekylltr = "---\n" + "layout: post\n" + jekyllTitle + jekyllDate
+ "author: 'Jerry(姜源)'\nheader-img: 'img/post-bg-2015.jpg'\ncatalog: false\n"
+ jekyllCategories + jekyllTags + "\n---\n";
String date = time.split(" ")[0];
String mdFileName = "./_posts/" + date + '-' + fileName + ".md";
md = jekylltr + md;
FileWriter writer;
try {
writer = new FileWriter(mdFileName);
writer.write(md);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void climbDetailById(String baseUrl, String articleId) {
String startUrl = baseUrl + "article/details/" + articleId;
Document doc = null;
try {
doc = Jsoup.connect(startUrl).get();
} catch (IOException e) {
System.out.println("jsoup获取url失败" + e.getMessage());
}
Element element = doc.body();
Element htmlElement = element.select("div#content_views").first();
Element titleElement = element.selectFirst(".title-article");
String fileName = titleElement.text();
System.out.println(fileName);
String jekyllTitle = "title: " + fileName + "\n";
Elements elements = element.select("div.tags-box");
String jekyllCategories = "";
if (elements.size() > 1) {
jekyllCategories = "categories:\n";
jekyllCategories = getTagsBoxValue(elements, 1, jekyllCategories);
}
String jekyllTags = "tags:\n";
jekyllTags = getTagsBoxValue(elements, 0, jekyllTags);
Element timeElement = element.selectFirst("span.time");
String time = timeElement.text().substring(5);
System.out.println(time);
String jekyllDate = "date: " + time + "\n";
String md = Html2MdUtil.getMarkDownText(htmlElement);
System.out.println(md);
String jekylltr = "---\n" + "layout: post\n" + jekyllTitle + jekyllDate
+ "author: 'Jerry(姜源)'\nheader-img: 'img/post-bg-2015.jpg'\ncatalog: false\n"
+ jekyllCategories + jekyllTags + "\n---\n";
String date = time.split(" ")[0];
String mdFileName = "./_posts/" + date + '-' + fileName + ".markdown";
md = jekylltr + md;
FileWriter writer;
try {
writer = new FileWriter(mdFileName);
writer.write(md);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
private static String getTagsBoxValue(Elements elements, int index, String jekyllCategories) {
Elements categories = elements.get(index).select("a.tag-link");
for (Element e : categories) {
String temp = e.text().replace("\t", "").replace("\n", "").replace("\r", "");
jekyllCategories += "-" + temp + "\n";
}
return jekyllCategories;
}
}
|
3. Html2MdUtil.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
| import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.nodes.Node;
import org.jsoup.select.Elements;
@SuppressWarnings("all")
public class Html2MdUtil {
private Html2MdUtil() {
}
public static String getMarkDownText(String html) {
StringBuilder result = new StringBuilder();
Document document = Jsoup.parseBodyFragment(html.replace(" ", ""));
for (Node node : document.body().childNodes()) {
result.append(handleNode(node));
}
return result.toString();
}
public static String getMarkDownText(Element element) {
StringBuilder result = new StringBuilder();
for (Node node : element.childNodes()) {
result.append(handleNode(node));
}
return result.toString();
}
private static String handleNode(Node node) {
String nodeName = node.nodeName();
String nodeStr = node.toString();
if ("p".equals(nodeName)) {
Element pElement = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("p").first();
String pStr = pElement.html();
for (Element child : pElement.children()) {
pStr = handleInnerHtml(pStr, child);
}
return pStr + "\n";
} else if ("pre".equals(nodeName)) {
return "```java\n" + Jsoup.parseBodyFragment(nodeStr).body().text() + "\n```\n";
} else if ("ul".equals(nodeName)) {
Element ulElement = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("ul").first();
String ulStr = ulElement.html().replace("<li>", "- ").replace("</li>", "");
for (Element li : ulElement.getElementsByTag("li")) {
for (Element child : li.children()) {
ulStr = handleInnerHtml(ulStr, child);
}
}
return ulStr + "\n";
} else if ("ol".equals(nodeName)) {
Element olElement = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("ol").first();
String olStr = olElement.html();
Elements liElements = olElement.getElementsByTag("li");
for (int i = 1; i <= liElements.size(); i++) {
Element li = liElements.get(i - 1);
olStr = olStr.replace(li.toString(), li.toString().replace("<li>", i + ". ").replace("</li>", ""));
for (Element child : li.children()) {
olStr = handleInnerHtml(olStr, child);
}
}
return olStr + "\n";
} else if ("blockquote".equals(nodeName)) {
Element blockquoteElement = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("blockquote").first();
Element pElement = blockquoteElement.getElementsByTag("p").first();
String pStr = pElement.html();
pStr = ">" + handleInnerHtml(pStr, pElement);
return pStr + "\n";
} else if ("h2".equals(nodeName)) {
Element h2Element = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("h2").first();
String h2Str = "## " + h2Element.text();
return h2Str + "\n";
} else if ("h3".equals(nodeName)) {
Element h3Element = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("h3").first();
String h3Str = "### " + h3Element.text();
return h3Str + "\n";
} else if ("h4".equals(nodeName)) {
Element h4Element = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("h4").first();
String h2Str = "#### " + h4Element.text();
return h2Str + "\n";
} else if ("h5".equals(nodeName)) {
Element h5Element = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("h5").first();
String h5Str = "##### " + h5Element.text();
return h5Str + "\n";
} else if ("#text".equals(nodeName)) {
return "\n";
}
return "";
}
private static String handleInnerHtml(String innerHTML, Element child) {
String s = child.tag().toString();
if ("strong".equals(s)) {
innerHTML = innerHTML.replace(child.toString(), "**" + child.text() + "**");
} else if ("img".equals(s)) {
String src = child.attr("src");
if (src.charAt(0) == '/') {
src = "http://img-blog" + src;
}
innerHTML = "\n" + innerHTML.replace(child.toString(), "");
} else if ("em".equals(s)) {
innerHTML = innerHTML.replace(child.toString(), " *" + child.text() + "* ");
} else if ("a".equals(s)) {
String href = child.attr("href");
innerHTML = innerHTML.replace(child.toString(), " [" + child.text() + "]" + "(" + href + ")");
} else {
innerHTML = innerHTML.replace(child.toString(), child.text());
}
return innerHTML;
}
}
|
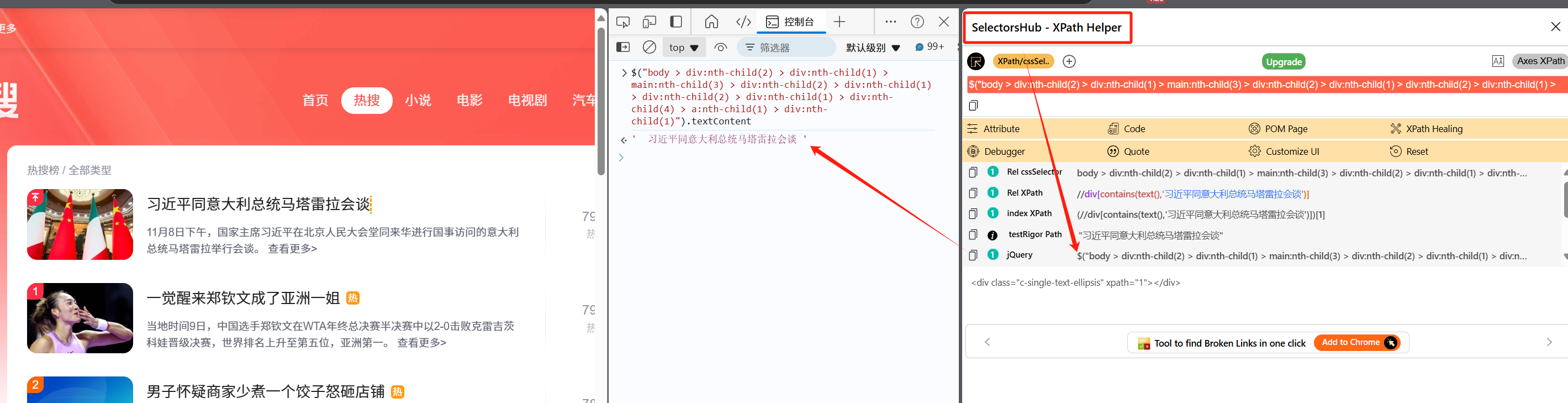
浏览器插件
补充市面上有一些浏览器插件可以协助快速定位dom以获取具体的遍历或值,比如
SelectorsHub - XPath Helper