03-RocketMQ 延迟消息
如何保证顺序消费?
- RabbitMQ:一个Queue对应一个Consumer即可解决。
- RocketMQ:hash(key)%队列数
- Kafka:hash(key)%分区数
如何实现延迟消费?
- RabbitMQ:两种方案死信队列 + TTL引入RabbitMQ的延迟插件
- RocketMQ:天生支持延时消息。
- Kafka:步骤如下专门为要延迟的消息创建一个Topic新建一个消费者去消费这个Topic消息持久化再开一个线程定时去拉取持久化的消息,放入实际要消费的Topic实际消费的消费者从实际要消费的Topic拉取消息。
如何保证消息的可靠性投递
RabbitMQ
- Broker–>消费者:手动ACK
- 生产者–>Broker:两种方案
数据库持久化:
1 | |
优点:能够保证消息百分百不丢失。
缺点:第一步会涉及到分布式事务问题。
消息的延迟投递:
1 | |
优点:相对于持久化方案来说响应速度有所提升
缺点:系统复杂性有点高,万一两条消息都失败了,消息存在丢失情况,仍需Confirm机制做补偿。
RocketMQ
生产者弄丢数据:
Producer在把Message发送Broker的过程中,因为网络问题等发生丢失,或者Message到了Broker,但是出了问题,没有保存下来。针对这个问题,RocketMQ对Producer发送消息设置了3种方式:
1 | |
Broker弄丢数据:
Broker接收到Message暂存到内存,Consumer还没来得及消费,Broker挂掉了。
可以通过 持久化 设置去解决:
- 创建Queue的时候设置持久化,保证Broker持久化Queue的元数据,但是不会持久化Queue里面的消息
- 将Message的deliveryMode设置为2,可以将消息持久化到磁盘,这样只有Message支持化到磁盘之后才会发送通知Producer ack
这两步过后,即使Broker挂了,Producer肯定收不到ack的,就可以进行重发。
消费者弄丢数据:
Consumer有消费到Message,但是内部出现问题,Message还没处理,Broker以为Consumer处理完了,只会把后续的消息发送。这时候,就要 关闭autoack,消息处理过后,进行手动ack , 多次消费失败的消息,会进入 死信队列 ,这时候需要人工干预。
Kafka
生产者弄丢数据
设置了 acks=all ,一定不会丢,要求是,你的 leader 接收到消息,所有的 follower 都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
Broker弄丢数据
Kafka 某个 broker 宕机,然后重新选举 partition 的 leader。大家想想,要是此时其他的 follower 刚好还有些数据没有同步,结果此时 leader 挂了,然后选举某个 follower 成 leader 之后,不就少了一些数据?这就丢了一些数据啊。
此时一般是要求起码设置如下 4 个参数:
1 | |
我们生产环境就是按照上述要求配置的,这样配置之后,至少在 Kafka broker 端就可以保证在 leader 所在 broker 发生故障,进行 leader 切换时,数据不会丢失。
消费者弄丢数据
你消费到了这个消息,然后消费者那边自动提交了 offset,让 Kafka 以为你已经消费好了这个消息,但其实你才刚准备处理这个消息,你还没处理,你自己就挂了,此时这条消息就丢咯。
这不是跟 RabbitMQ 差不多吗,大家都知道 Kafka 会自动提交 offset,那么只要 关闭自动提交 offset,在处理完之后自己手动提交 offset,就可以保证数据不会丢。但是此时确实还是可能会有重复消费,比如你刚处理完,还没提交 offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
如何保证消息的幂等?
以 RocketMQ 为例,下面列出了消息重复的场景:
发送时消息重复
当一条消息已被成功发送到服务端并完成持久化,此时出现了网络闪断或者客户端宕机,导致服务端对客户端应答失败。如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同并且Message ID也相同的消息。
投递时消息重复
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。为了保证消息至少被消费一次,消息队列RocketMQ版的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且Message ID也相同的消息。
负载均衡时消息重复(包括但不限于网络抖动、Broker重启以及消费者应用重启)
当消息队列RocketMQ版的Broker或客户端重启、扩容或缩容时,会触发Rebalance,此时消费者可能会收到重复消息。
那么,有什么解决方案呢?直接上图。
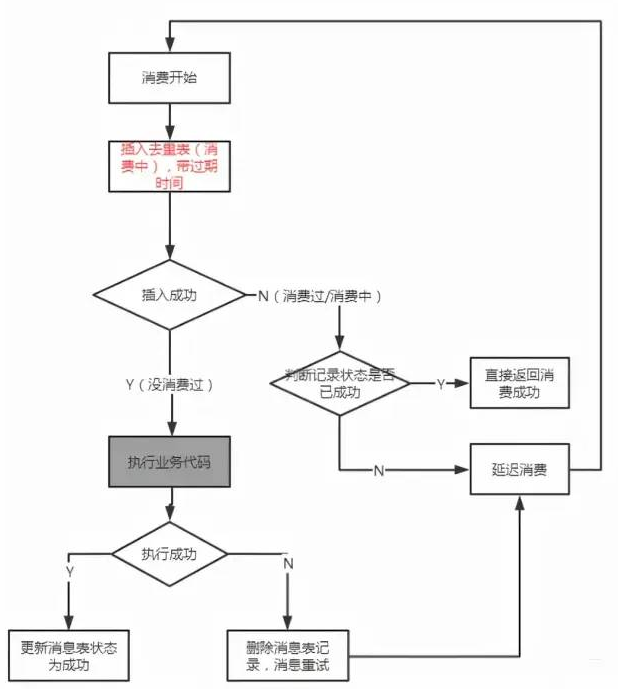
如何解决消息积压的问题?
关于这个问题,有几个点需要考虑:
如何快速让积压的消息被消费掉?
临时写一个消息分发的消费者,把积压队列里的消息均匀分发到N个队列中,同时一个队列对应一个消费者,相当于消费速度提高了N倍。
积压时间太久,导致部分消息过期,怎么处理?
批量重导。在业务不繁忙的时候,比如凌晨,提前准备好程序,把丢失的那批消息查出来,重新导入到MQ中。
消息大量积压,MQ磁盘被写满了,导致新消息进不来了,丢掉了大量消息,怎么处理?
这个没办法。谁让【消息分发的消费者】写的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
