08-线程池ThreadPoolExecutor
参考资料: https://developer.aliyun.com/topic/java20
参考资料:https://blog.csdn.net/ming1215919/article/details/114799184
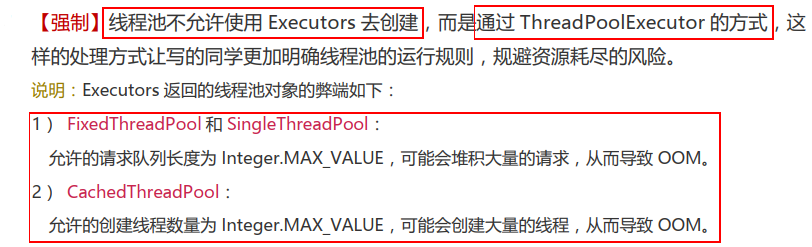
线程池
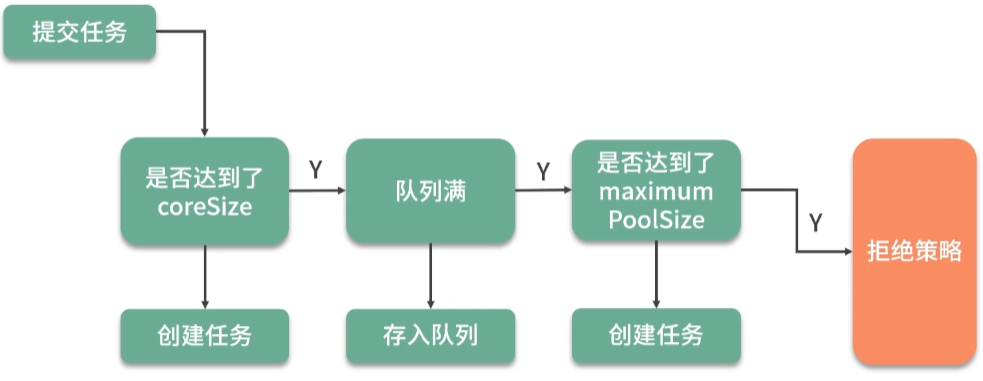
线程池的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,那么超出数量的线程排队等候,等其他线程执行完毕再从队列中取出任务来执行。
在开发过程中,合理地使用线程池能够带来3个好处:
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗;
提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行;
提高线程的可管理性。线程如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
原理:
整个过程就像下面这个有趣的动画:
OOM: Out Of Memory.
ThreadPoolExecutor
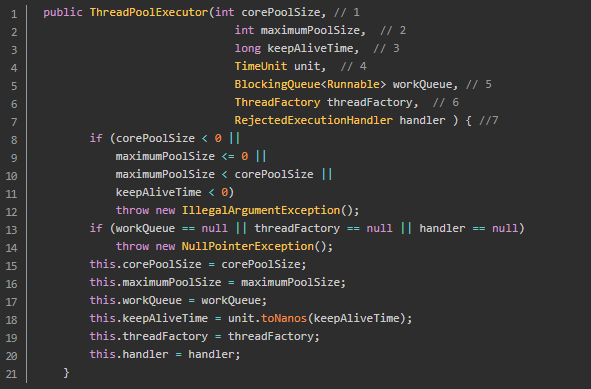


参数 6 threadFactory 和 7 handler 为可选参数,有其默认值。
1)corePoolSize:线程池的核心线程数,定义了最小可以同时运行的线程数量。
2)maximumPoolSize:线程池的最大线程数,队列中存放的任务达到队列容量时,当前可以同时运行的线程数量变为最大线程数。
3)keepAliveTime:当线程池中的线程数量大于corePoolSize时,如果没有新任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了KeepAliveTime才会被回收销毁。
4)unit:keepAliveTime参数的时间单位,包括DAYS、HOURS、MINUTES、MILLISECONDS等。
5)workQueue:用于保存等待执行任务的阻塞队列。可以选择以下集个阻塞队列:
- ArrayBlockingQueue:是一个基于数组结构的阻塞队列,此队列按FIFO原则对元素进行排序;
- LinkedBlockingQueue:是一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常高于ArrayBlockingQueue。静态工厂方法 Executors.newFixedThreadPool() 使用了这个队列;
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量常高于 LinkedBlockingQueue ,静态工厂方法Executors.newCachedThreadPool() 使用了这个队列;
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
6)threadFactory:用于设置创建线程的工厂,可以通过工厂给每个创造出来的线程设置更有意义的名字。使用开源框架guava提供的ThreadFactoryBuilder可以快速给线程池里的线程设置有意义的名字:
1 | |
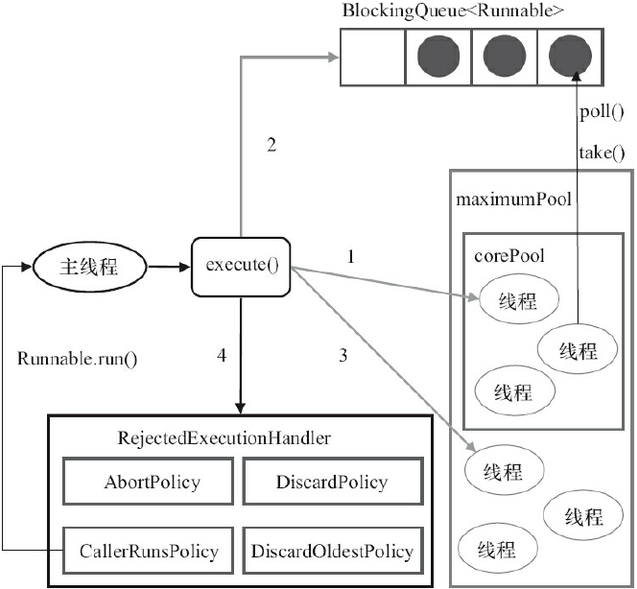
7)handler:拒绝策略。若当前同时运行的线程数量达到最大线程数量并且队列已经被放满,则执行拒绝策略。ThreadPoolExecutor 定义了一些饱和策略:
- ThreadPoolExecutor.AbortPolicy:直接抛出RejectedExecutionException异常来拒绝处理新任务;
- ThreadPoolExecutor.CallerRunsPolicy:只用调用者所在的线程来运行任务,会降低新任务的提交速度,影响程序的整体性能。
- ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃掉。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列中最近的一个任务,执行当前任务。

原理
ThreadPoolExecutor执行execute()方法原理:
使用
- 向线程池提交任务
execute()方法用于像线程池提交不需要返回值的任务
所以无法判断任务是否被线程池执行成功。
1 | |
submit()方法用于提交需要返回值的任务。
线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout, TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时有可能任务还没有执行完。
1 | |
- 关闭线程池
可以使用线程池的shutdown或 shutdownNow 方法来关闭线程池。其原理在于遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能无法终止。
二者区别在于:shutdownNow方法首先将线程池状态设置为STOP,然后尝试停止所有正在执行或暂停任务的线程,并返回等到执行任务的列表,而shutdown只是将线程池的状态设置为SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
- 合理配置线程池
查看当前设备的CPU核数:
1 | |
CPU密集型任务
任务需要大量的运算,而没有阻塞,CPU一直全速运行,CPU密集型任务配置尽可能的少的线程数量,来尽可能压榨CPU的运算能力。
公式:
CPU核数 + 1个线程的线程池。IO密集型任务
数据库交互,文件上传下载,网络传输等。
方法一:由于IO密集型任务线程并不是一直在执行任务,可以多分配一点线程数,如
CPU核数*2。方法二:任务需要大量的IO,即大量的阻塞。在单线程上运IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。所以在IO密集型任务中使用多线程可以大大的加速程序运行,即使在单核CPU上,这种加速主要就是利用了被浪费掉的阻塞时间。
公式:
CPU核数/(1-阻塞系数),其中阻塞系数在0.8-0.9之间(比如8核CPU:8/(1 - 0.9)=80个线程数)。
《Java并发编程实战》的作者 Brain Goetz 推荐的计算方法:
- 线程数 =
CPU核数 * (1 + 平均等待时间 / 平均工作时间)
在I/O密集型的逻辑处理中,当线程池的数量定义得太小时,会导致请求的频繁失败,原因如下:
- 阻塞IO操作:I/O密集型的任务通常会涉及到与外部资源(如数据库、网络等)的交互,这些操作往往是阻塞的,即线程在执行这些操作时会被阻塞,等待操作完成。如果线程池中的线程数量过小,无法满足并发请求的需求,导致请求被阻塞等待可用的线程,从而导致请求的频繁失败。
- 请求堆积:当线程池中的线程数量不足以处理并发请求时,新的请求会被放入线程池的等待队列中等待执行。如果等待队列的容量有限,而请求的到达速度过快,超过了线程池的处理能力,那么请求会被拒绝或者丢弃,从而导致请求的频繁失败。
- 线程资源耗尽:线程池中的线程数量有限,如果线程池的数量定义得太小,而请求的到达速度过快,超过了线程池的处理能力,那么线程资源会很快耗尽。当所有的线程都被占用时,新的请求无法得到处理,从而导致请求的频繁失败。
