05-Stream流高级
Java 强大的 stream 流处理,必会!
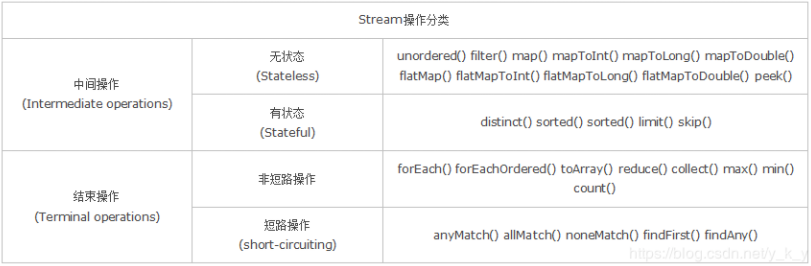
无状态:指元素的处理不受之前元素的影响;
有状态:指该操作只有拿到所有元素之后才能继续下去。
非短路操作:指必须处理所有元素才能得到最终结果;
短路操作:指遇到某些符合条件的元素就可以得到最终结果,如 A || B,只要A为true,则无需判断B的结果。
一 基本汇总
1. 创建流
1.1 使用Collection下的 stream() 和 parallelStream() 方法
1 | |
1.2 使用Arrays 中的 stream() 方法,将数组转成流
1 | |
1.3 使用Stream中的静态方法:of()、iterate()、generate()
1 | |
1.4 使用 BufferedReader.lines() 方法,将每行内容转成流
1 | |
1.5 使用 Pattern.splitAsStream() 方法,将字符串分隔成流
1 | |
2. 中间操作
2.1 筛选与切片
- filter:过滤流中的某些元素
- limit(n):获取n个元素
- skip(n):跳过n元素,配合limit(n)可实现分页
- distinct:通过流中元素的 hashCode() 和 equals() 去除重复元素
1 | |
2.2 映射
- map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
- flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
1 | |
2.3 排序
- sorted():自然排序,流中元素需实现Comparable接口
- sorted(Comparator com):定制排序,自定义Comparator排序器
1 | |
2.4 消费
- peek:如同于map,能得到流中的每一个元素。但map接收的是一个Function表达式,有返回值;而peek接收的是Consumer表达式,没有返回值。
1 | |
3. 终止操作
3.1 匹配、聚合操作
- allMatch:接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false
- noneMatch:接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false
- anyMatch:接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false
- findFirst:返回流中第一个元素
- findAny:返回流中的任意元素
- count:返回流中元素的总个数
- max:返回流中元素最大值
- min:返回流中元素最小值
1 | |
3.2 规约操作
- Optional reduce(BinaryOperator accumulator):
- 第一次执行时,accumulator函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素;
- 第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素;依次类推。
- T reduce(T identity, BinaryOperator accumulator):
- 流程跟上面一样,只是第一次执行时,accumulator函数的第一个参数为identity,而第二个参数为流中的第一个元素。
- U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator combiner):
- 在串行流(stream)中,该方法跟第二个方法一样,即第三个参数combiner不会起作用。在并行流(parallelStream)中,我们知道流被fork join出多个线程进行执行,此时每个线程的执行流程就跟第二个方法reduce(identity,accumulator)一样,而第三个参数combiner函数,则是将每个线程的执行结果当成一个新的流,然后使用第一个方法reduce(accumulator)流程进行规约。
1 | |
3.3 收集操作
collect:接收一个Collector实例,将流中元素收集成另外一个数据结构。
Collector<T, A, R> 是一个接口,有以下5个抽象方法:
Supplier<A> supplier():创建一个结果容器A
BiConsumer<A, T> accumulator():消费型接口,第一个参数为容器A,第二个参数为流中元素T。
BinaryOperator<A> combiner():函数接口,该参数的作用跟上一个方法(reduce)中的combiner参数一样,将并行流中各 个子进程的运行结果(accumulator函数操作后的容器A)进行合并。
Function<A, R> finisher():函数式接口,参数为:容器A,返回类型为:collect方法最终想要的结果R。
Set<Characteristics> characteristics():返回一个不可变的Set集合,用来表明该Collector的特征。有以下三个特征:
CONCURRENT:表示此收集器支持并发。(官方文档还有其他描述,暂时没去探索,故不作过多翻译)
UNORDERED:表示该收集操作不会保留流中元素原有的顺序。
IDENTITY_FINISH:表示finisher参数只是标识而已,可忽略。
3.3.1 Collector 工具库:Collectors
1 | |
3.3.2 Collectors.toList() 解析
1 | |
二 经验累积
1. 统计
1.1 取最大值
1 | |
1.2 取最小值
1 | |
1.3 取总和值
1 | |
1.4 取平均值
1 | |
2. 过滤
2.1 获取最近时间
1 | |
3. 排序
3.1 根据字段排序
1 | |
4. 分组
4.1 获取字段出现次数
1 | |
4.2 过滤并获取指定字段列表
1 | |
