04-Stream实现原理分析
1.Stream 为什么会出现?
Stream 出现之前,遍历一个集合最传统的做法大概是用 Iterator,或者 for 循环。这种两种方式都属于外部迭代,然而外部迭代存在着一些问题。
开发者需要自己手写迭代的逻辑,虽然大部分场景迭代逻辑都是每个元素遍历一次。
如果存在像排序这样的有状态的中间操作,不得不进行多次迭代。
多次迭代会增加临时变量,从而导致内存的浪费。
虽然 Java 5 引入的 foreach 解决了部分问题,但也引入了新的问题。
foreach 遍历不能对元素进行赋值操作
遍历的时候,只有当前被遍历的元素可见,其他不可见
随着大数据的兴起,传统的遍历方式已经无法满足开发者的需求。
就像小作坊发展到一定程度要变成大工厂才能满足市场需求一样。大工厂和小作坊除了规模变大、工人不多之外,最大的区别就是多了流水线。流水线可以将工人们更高效的组织起来,使得生产力有质的飞跃。
所以不安于现状的开发者们想要开发一种更便捷,更实用的特性。
- 它可以像流水线一样来处理数据
- 它应该兼容常用的集合
- 它的编码应该更简洁
- 它应该具有更高的可读性
- 它可以提供对数据集合的常规操作
- 它可以拼装不同的操作
经过不懈的能力,Stream 就诞生了。加上 lambda 表达式的加成,简直是如虎添翼。
2.你可以用 Stream 干什么?
下面以简单的需求为例,看一下 Stream 的优势:
从一列单词中选出以字母a开头的单词,按字母排序后返回前3个。
2.1 外部迭代实现方式
1 | |
2.2 stream实现方式
1 | |
3.Stream 是怎么实现的?
3.1 需要解决的问题
- 如何定义流水线?
- 原料如何流入?
- 如何让流水线上的工人将处理过的原料交给下一个工人?
- 流水线何时开始运行?
- 流水线何时结束运行?
3.2 总观全局
Stream 处理数据的过程可以类别成工厂的流水线。数据可以看做流水线上的原料,对数据的操作可以看做流水线上的工人对原料的操作。
事实上 Stream 只是一个接口,并没有操作的缺省实现。最主要的实现是ReferencePipeline,而 ReferencePipeline 继承自AbstractPipeline ,AbstractPipeline 实现了 BaseStream 接口并实现了它的方法。但 ReferencePipeline 仍然是一个抽象类,因为它并没有实现所有的抽象方法,比如 AbstractPipeline 中的 opWrapSink。ReferencePipeline内部定义了三个静态内部类,分别是:Head, StatelessOp, StatefulOp,但只有 Head 不再是抽象类。
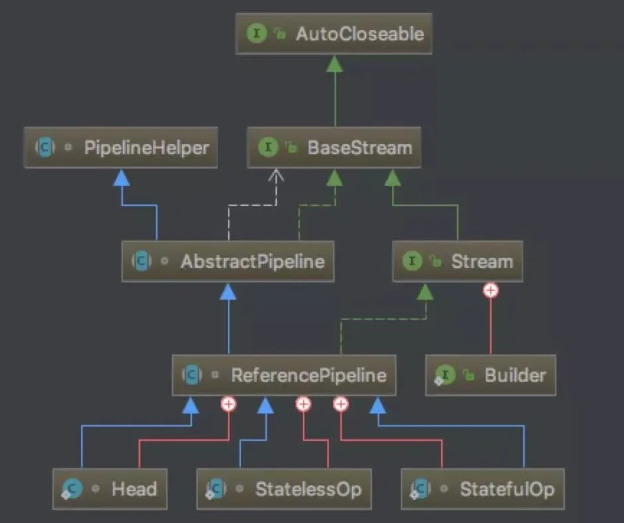
流水线的结构有点像双向链表,节点之间通过引用连接。节点可以分为三类,控制数据输入的节点、操作数据的中间节点和控制数据输出的节点。
ReferencePipeline 包含了控制数据流入的 Head ,中间操作 StatelessOp, StatefulOp,终止操作 TerminalOp。
Stream 常用的流操作包括:
中间操作(Intermediate Operations)
- 无状态(Stateless)操作:每个数据的处理是独立的,不会影响或依赖之前的数据。如
filter()、flatMap()、flatMapToDouble()、flatMapToInt()、flatMapToLong()、map()、mapToDouble()、mapToInt()、mapToLong()、peek()、unordered()等 - 有状态(Stateful)操作:处理时会记录状态,比如处理了几个。后面元素的处理会依赖前面记录的状态,或者拿到所有元素才能继续下去。如
distinct()、sorted()、sorted(comparator)、limit()、skip()等
- 无状态(Stateless)操作:每个数据的处理是独立的,不会影响或依赖之前的数据。如
终止操作(Terminal Operations)
- 非短路操作:处理完所有数据才能得到结果。如
collect()、count()、forEach()、forEachOrdered()、max()、min()、reduce()、toArray()等。 - 短路(short-circuiting)操作:拿到符合预期的结果就会停下来,不一定会处理完所有数据。如
anyMatch()、allMatch()、noneMatch()、findFirst()、findAny()等。
- 非短路操作:处理完所有数据才能得到结果。如
3.3 源码分析
了解了流水线的结构和定义,接下来我们基于上面的例子逐步看一下源代码。
3.3.1 定义输入源
stream() 是 Collection 中的 default 方法,实际上调用的是 StreamSupport.stream() 方法,返回的是 ReferencePipeline.Head的实例。
ReferencePipeline.Head的构造函数传递是 ArrayList 中实现的 spliterator 。常用的集合都实现了 Spliterator 接口以支持 Stream。可以这样理解,Spliterator 定义了数据集合流入流水线的方式。
3.3.2 定义流水线节点
filter() 是 Stream 中定义的方法,在 ReferencePipeline 中实现,返回StatelessOp 的实例。
可以看到
filter()接收的参数是谓词,可以用lambda表达式。StatelessOp的构造函数接收了this,也就是ReferencePipeline.Head实例的引用。并且实现了AbstractPipeline中定义的opWrapSink方法。
1 | |
sorted() 和 limit() 的返回值和也都是 Stream 的实现类,并且都接收了this 。不同的是 sorted() 返回的是 ReferencePipeline.StatefulOp 的子类 SortedOps.OfRef 的实例。limit() 返回的 ReferencePipeline.StatefulOp 的实例。
现在可以粗略地看到,这些中间操作(不管是无状态的 filter(),还是有状态的sorted() 和 limit() 都只是返回了一个包含上一节点引用的中间节点。有点像 HashMap 中的反向单向链表。就这样把一个个中间操作拼接到了控制数据流入的 Head 后面,但是并没有开始做任何数据处理的动作。
这也就是 Stream 延时执行的特性原因之所在。
代码中会发现 StatelessOp 和StatefulOp 初始化的时候还会将当前节点的引用传递给上一个节点。
previousStage.nextStage = this;所以各个节点组成了一个双向链表的结构。
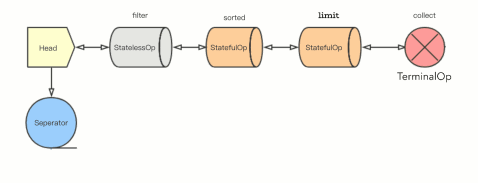
3.3.3 组装流水线
最后来看一下终止操作 .collect() 接收的是返回类型对应的 Collector。
此例中的 Collectors.toList() 是 Collectors 针对 ArrayList 的创建的 CollectorImpl 的实例。
1 | |
先忽略并行的情况,来看一下加注释了1的代码:
ReduceOps.makeRef接收此 Collector 返回了一个ReduceOp(实现了TerminalOp接口)的实例。- 返回的
ReduceOp实例又被传递给 AbstractPipeline 中的evaluate()方法。 - 在
evaluate中,调用了ReduceOp实例的evaluateSequential方法,并将上流水线上最后一个节点的引用和sourceSpliterator传递进去。
1 | |
- 然后调用
ReduceOp实例的makeSink()方法返回其makeRef()方法内部类ReducingSink的实例。 - 接着
ReducingSink的实例作为参数和spliterator一起传入最后一个节点的wrapAndCopyInto()方法,返回值是 Sink 。
3.3.4 启动流水线
流水线组装好了,现在就该启动流水线了。这里的核心方法是 wrapAndCopyInto,根据方法名也能看出来这里应该做了两件事,wrapSink() 和 copyInto()。
wrapSink()
将最后一个节点创建的 Sink 传入,并且看到里面有个 for 循环。
每个节点都记录了上一节点的引用( previousStage )和每一个节点的深度(depth )。
所以这个 for 循环是从最后一个节点开始,到第二个节点结束。每一次循环都是将上一节点的 combinedFlags 和当前的 Sink 包起来生成一个新的 Sink 。这和前面拼接各个操作很类似,只不过拼接的是 Sink 的实现类的实例,方向相反。
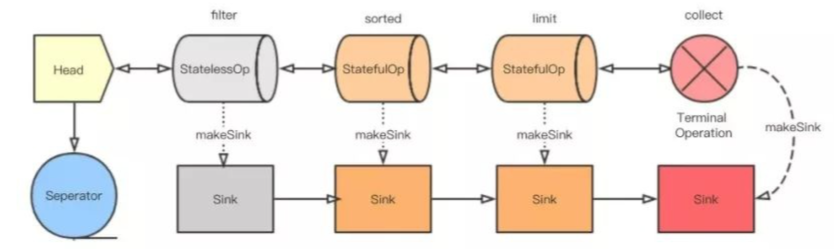
(Head.combinedFlags, (StatelessOp.combinedFlags, (StatefulOp.combinedFlags,(StatefulOp.combinedFlags ,TerminalOp.sink)))
1 | |
copyInto()
终于到了要真正开始迭代的时候,这个方法接收两个参数 Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator 。wrappedSink对应的是Head节点后面的第一个操作节点(它相当于这串 Sink 的头),spliterator 对应着数据源。
这个时候我们回过头看一下 Sink 这个接口,它继承自 Consumer 接口,又定义了begin()、end()、cancellationRequested() 方法。Sink 直译过来是水槽,如果把数据流比作水,那水槽就是水会流过的地方。begin() 用于通知水槽的水要过来了,里面会做一些准备工作,同样 end() 是做一些收尾工作。cancellationRequested() 是原来判断是不是可以停下来了。Consumer 里的accept() 是消费数据的地方。
1 | |
有了完整的水槽链,就可以让水流进去了。copyInto() 里做了三个动作:
- 通知第一个水槽(Sink)水要来了,准备一下。
- 让水流进水槽(Sink)里。
- 通知第一个水槽(Sink)水流完了,该收尾了。
突然想到宋丹丹老师的要把大象放冰箱要几步?
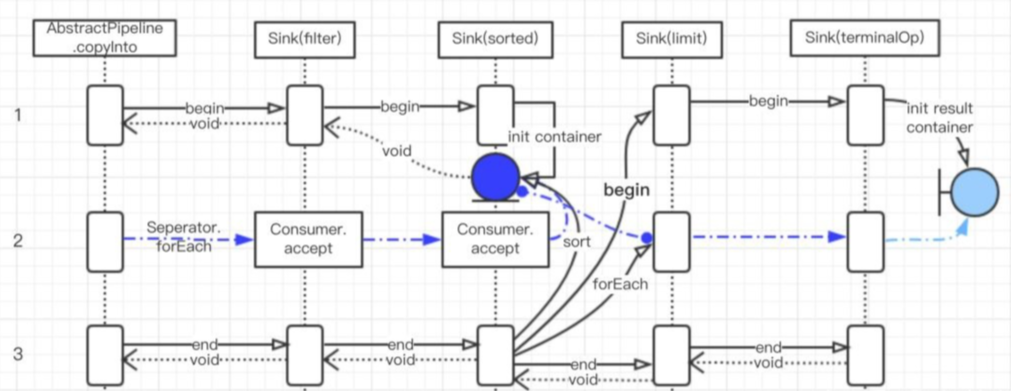
注:图中蓝色线表示数据实际的处理流程。
每一个 Sink 都有自己的职责,但具体表现各有不同。无状态操作的 Sink 接收到通知或者数据,处理完了会马上通知自己的 下游。有状态操作的 Sink 则像有一个缓冲区一样,它会等要处理的数据处理完了才开始通知下游,并将自己处理的结果传递给下游。
例如 sorted() 就是一个有状态的操作,一般会有一个属于自己的容器,用来记录处自己理过的数据的状态。sorted() 是在执行 begin 的时候初始化这个容器,在执行 accept 的时候把数据放到容器中,最后在执行 end 方法时才正在开始排序。排序之后再将数据,采用同样的方式依次传递给下游节点。
最后数据流到终止节点,终止节点将数据收集起来就结束了。
然后就没有然后了,copyInto() 返回类型是 void ,没有返回值。
wrapAndCopyInto() 返回了 TerminalOps 创建的 Sink,这时候它里面已经包含了最终处理的结果。调用它的 get() 方法就获得了最终的结果。
4.总结
首先是将 Collection 转化为 Stream,也就是流水线的头。然后将各个中间操作节点像拼积木一样拼接起来。每个中间操作节点都定义了自己对应的 Sink,并重写了 makeSink() 方法用来返回自己的 Sink 实例。直到终止操作节点出现时才开始将 Sink 实例化并串起来。然后就是上面提到的那三步:通知、数据流入、结束。
