02-美团Leaf实战
参考资料:https://github.com/Meituan-Dianping/Leaf
1.Leaf-segment号段模式
Leaf-segment号段模式是对直接用数据库自增ID充当分布式ID的一种优化,减少对数据库的频率操作。相当于从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,业务服务将号段在本地生成1~1000的自增ID并加载到内存。 大致流程如下:
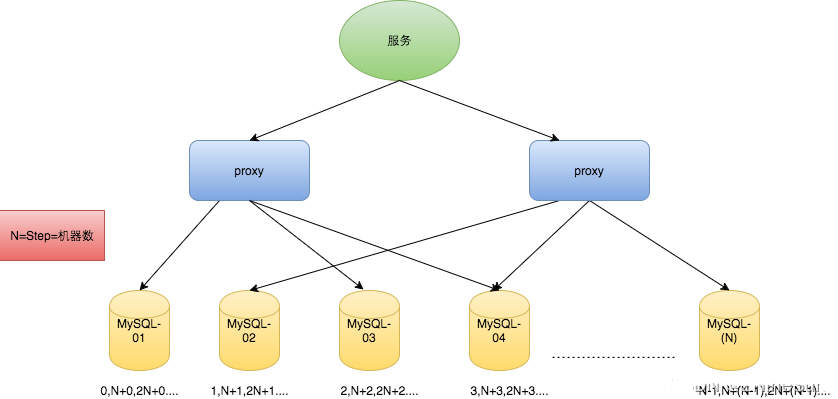
号段耗尽之后再去数据库获取新的号段,可以大大的减轻数据库的压力。对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
1.1 数据库配置
由于号段模式依赖于数据库表,我们先创建数据库和表:
- 创建数据库:leaf
- 创建数据表:
1 | |
- 初始化数据表:
1 | |
这些字段在插入数据时有哪些注意事项呢?
- biz_tag:针对不同业务需求,用biz_tag字段来隔离,如果以后需要扩容时,只需对biz_tag分库分表即可
- max_id:当前业务号段的最大值,用于计算下一个号段
- step:步长,也就是每次获取ID的数量
- description:对于业务的描述,随意写
1.2 导入并修改leaf项目
我们需要先导入Leaf项目。
导入之后的项目如下:
在leaf-server项目下修改配置(leaf.properties)如下:
1 | |
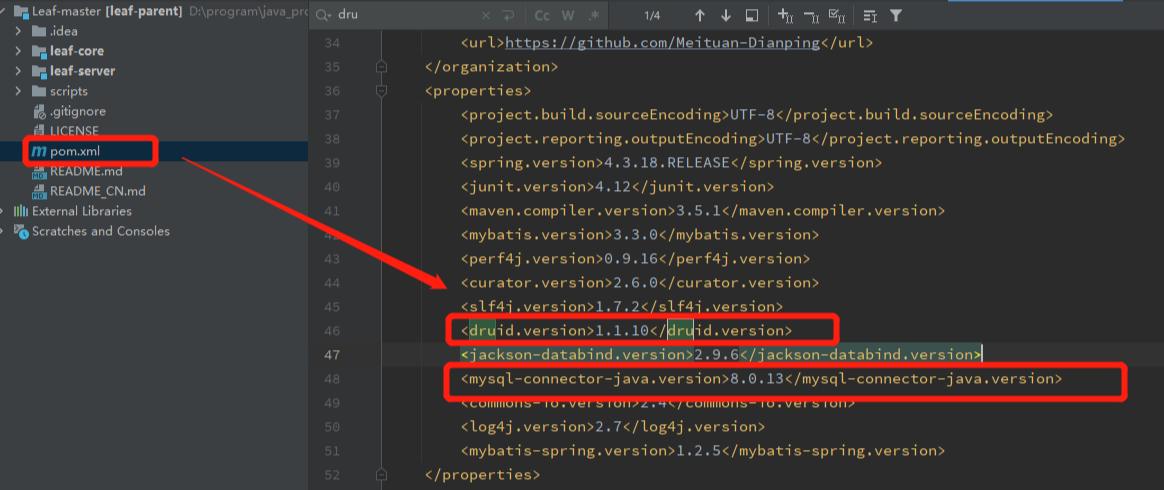
注意:leaf.segment和leaf.snowflake务必保证只有一个开启,由于使用的是segment(号段模式),所以开启此服务 然后由于我的mysql服务器是8.0.1版本,所以我将pom中的mysql-connector以及druid对做了相应的版本修改,注意如果你的mysql版本是5.x.x版本的就无须任何修改,否则的话就要到父级的pom下修改成和我同样的版本
- druid:1.1.10
- mysql-connector:8.0.13
启动项目leaf-server 访问地址:http://127.0.0.1:8080/api/segment/get/leaf-segment-test
注意:leaf-segment-test是我们的key,这个key来自于哪儿呢,来自于刚刚我们insert的biz_tag

1.3 Leaf-segment双buffer模式
leaf的号段模式在更新号段时是无阻塞的,当号段耗尽时再去DB中取下一个号段,如果此时网络发生抖动,或者DB发生慢查询,业务系统拿不到号段,就会导致整个系统的响应时间变慢,对流量巨大的业务,这是不可容忍的。
所以Leaf在当前号段消费到某个点时,就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。这样做很大程度上的降低了系统的风险。 好,眼见为实,我们看看 这个点到底什么时候会发生,由于我们初始化的时候把maxx_id和step设置的太大,我们修改一下,step=10,max_id=1,如下所示:

我们去访问地址:http://127.0.0.1:8080/api/segment/get/leaf-segment-test


我们可以看到我们id生成到2的时候,max_id就变成了11,我们再继续获取id


我们获取到3的时候,max_id就已经变成了21 这是怎么一回事呢?
Leaf-segment采用双buffer的方式,它的服务内部有两个号段缓存区segment。 当前号段已消耗10%时,还没能拿到下一个号段,则会另启一个更新线程去更新下一个号段。 简而言之就是Leaf保证了总是会多缓存两个号段,即便哪一时刻数据库挂了,也会保证发号服务可以正常工作一段时间。

那我们在平时开发时去怎么设置步长呢?
通常推荐号段(segment)长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
1.4 Leaf segment监控
访问:http://127.0.0.1:8080/cache
可以看到:

1.5 优缺点
- 优点: Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务。
- 缺点: ID号码不够随机,能够泄露发号数量的信息,不太安全。 DB宕机会造成整个系统不可用(用到数据库的都有可能)。
2.Leaf-snowflake雪花算法
我简单的给大家说一下雪花算法的原理:Leaf-snowflake 基本上就是沿用了snowflake的设计,ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 机房ID(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
Leaf-snowflake不同于原始snowflake算法地方,主要是在workId的生成上,Leaf-snowflake依靠Zookeeper生成workId,也就是上边的机器ID(占5比特)+ 机房ID(占5比特)。Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
好了说了那么多,我们看看Leaf-snowflake是怎么启动的?
2.1 Leaf-snowflake的启动过程
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
但Leaf-snowflake对Zookeeper是一种弱依赖关系,除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件。一旦ZooKeeper出现问题,恰好机器出现故障需重启时,依然能够保证服务正常启动。
启动Leaf-snowflake模式也比较简单,启动本地ZooKeeper,修改一下项目中的leaf.properties文件,关闭leaf.segment模式,启用leaf.snowflake模式即可。
1 | |
注意:在启动项目之前,请保证已经正常启动zookeeper
访问:http://127.0.0.1:8080/api/snowflake/get/leaf-segment-test
可以看到:

2.2 优缺点
- 优点: ID号码是趋势递增的8 byte的64位数字,满足上述数据库存储的主键要求。
- 缺点: 依赖ZooKeeper,存在服务不可用风险
