1.什么是 CAS
CAS, compare and swap的缩写,中文翻译成比较并交换。
CAS 操作包含三个操作数 —— **内存位置(V)、预期原值(A)和新值(B)**。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。
2.为什么要使用 CAS
在并发中,我们需要对一个数据进行更改,如果使用锁来保证原子性,首先在性能方面会设计到底层操作系统内核线程切换,这个开销是很大的,如果使用 CAS 实现的话,相比较之下不会设计到内核切换,开销比较轻。
使用伪代码表示
1
2
3
| if (value == expectedValue) {
value = newValue;
}
|
一个由比较和赋值两阶段组成的复合操作,CAS 可以看作是它们合并后的整体 ——一个不可分割的原子操作,并且其原子性是直接在硬件层面得到保障的。
CAS可以看做是乐观锁(对比数据库的悲观、乐观锁)的一种实现方式,Java原子类中的递增操 作就通过CAS自旋实现的。 CAS是一种无锁算法,在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。
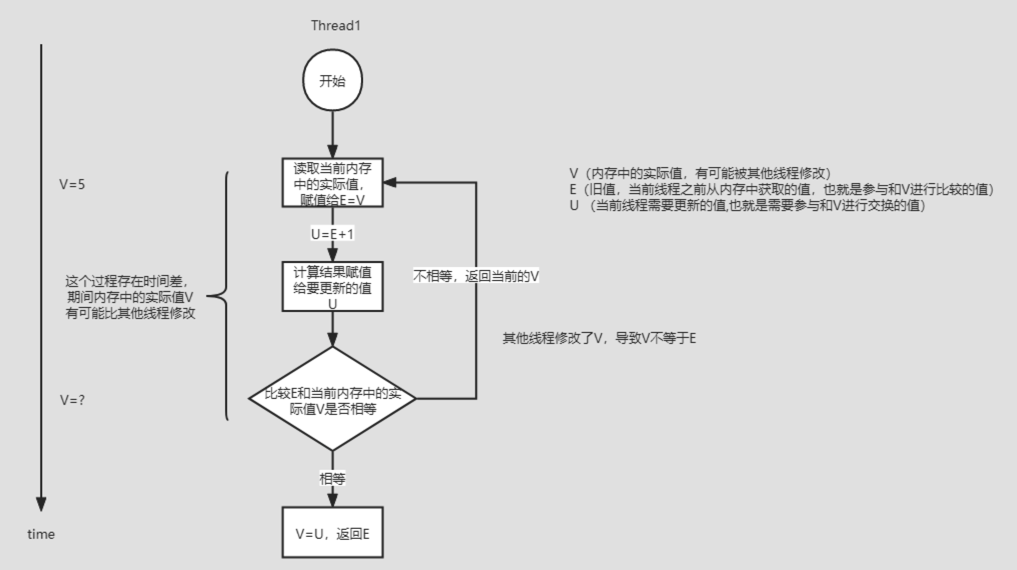
- 首先读取内存中的实际值v 如果和自己的值E相等,计算赋值给更新的值 U 成功则返回 U
- 上面更新失败,则继续重试,成功则返回,失败则继续重试。
3.CAS应用
在Java中使用 CAS:
CAS 操作是由 Unsafe 类提供支持的,该类定义了三种针对不同类型变量的 CAS 操 作

可以看到是本地方法,是由 JVM 实现的。 接收四个参数分别是:
对象的实例,内存偏移量,字段期望值,字段新值。
4.CAS缺陷
CAS 虽然解决了原子性,但是有一些问题:
ABA 问题只能保证一个共享变量的原子操作CAS 不成功,长时间会造成 CPU 空转(自旋),影响 CPU 开销
4.1 ABA问题
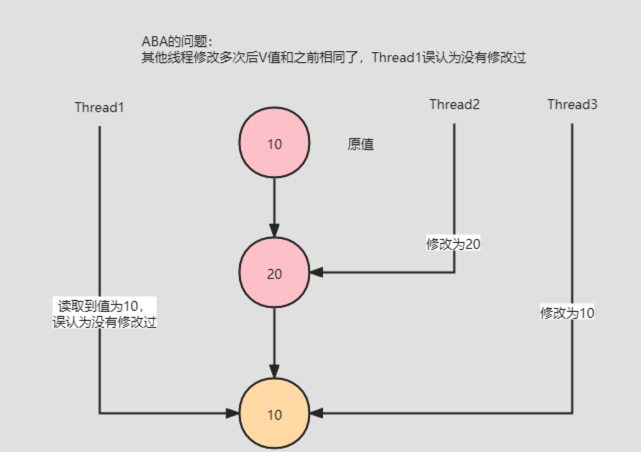
当有多个线程对一个原子类进行操作的时候,某个线程在短时间内将原子类的值A修改为B,又马上将其修改为A,此时其他线程不感知,还是会修改成功。
main 线程不清楚另一个线程对这个变量进行了修改,可能误认为没有更改过。

4.2 ABA问题的解决
可以在每一次修改时给一个版本号,这也就是乐观锁的由来。
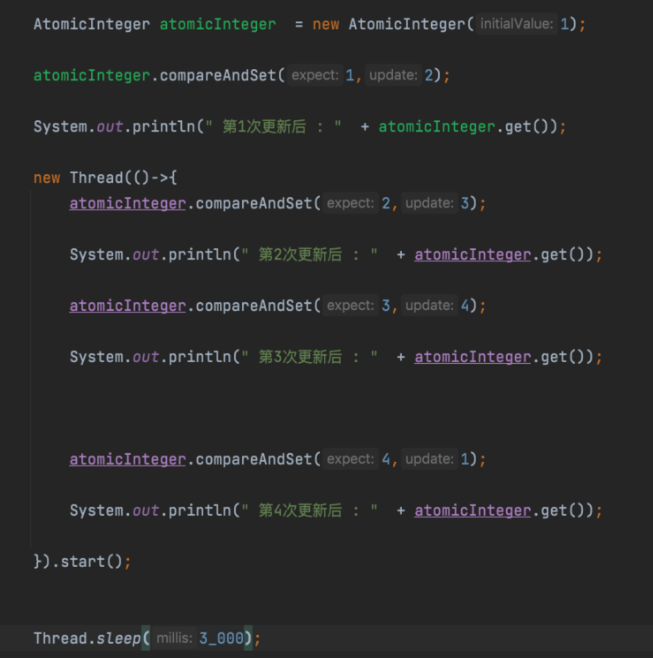
比如 Java中AtomicStampedReference类就提供了这样的功能,三个线程 t1,t2,t3 分别对变量进行修改,最后t3在更改为初始值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| AtomicStampedReference<Integer> asri = new AtomicStampedReference<>(1, 1);
new Thread(() -> {
boolean b = asri.compareAndSet(1, 2, asri.getStamp(), asri.getStamp() + 1);
while (b) {
if (b) {
System.out.println(" t1 修改成功 ");
return;
} else {
System.out.println(" t1 修改失败 ");
}
}
}, "t1 ").start();
new Thread(() -> {
boolean b = asri.compareAndSet(2, 3, asri.getStamp(), asri.getStamp() + 1);
while (b) {
if (b) {
System.out.println(" t2 修改成功 ");
return;
} else {
System.out.println(" t2 修改失败 ");
}
}
}, "t2 ").start();
new Thread(() -> {
boolean b = asri.compareAndSet(3, 1, asri.getStamp(), asri.getStamp() + 1);
while (b) {
if (b) {
System.out.println(" t3 修改成功 ");
return;
} else {
System.out.println(" t3 修改失败 ");
}
}
}, "t3 ").start();
Thread.sleep(100);
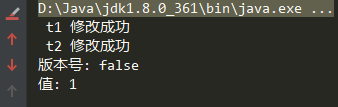
System.out.println("版本号: " + asri.getStamp());
System.out.println("值: " + asri.getReference());
|
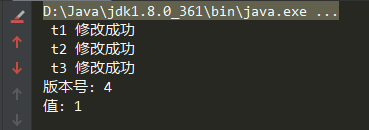
可以看到结果最后值还是 1 但是版本号已经是 4 了,已经变了三个版本了。
reference即我们实际存储的变量,stamp是版本,每次修改可以通过+1保证版本唯一性。这样就可以保证每次修改后的版本也会往上递增。
另外还有AtomicMarkableReference类 是 AtomicStampedReference 类的补充版,不关心修改了几次,只关心有没有修改过。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| AtomicMarkableReference<Integer> amri = new AtomicMarkableReference<Integer>(1, false);
new Thread(() -> {
boolean b = amri.compareAndSet(1, 2, false, true);
while (b) {
if (b) {
System.out.println(" t1 修改成功 ");
return;
} else {
System.out.println(" t1 修改失败 ");
}
}
}, "t1 ").start();
new Thread(() -> {
boolean b = amri.compareAndSet(2, 1, true, false);
while (b) {
if (b) {
System.out.println(" t2 修改成功 ");
return;
} else {
System.out.println(" t2 修改失败 ");
}
}
}, "t2 ").start();
Thread.sleep(100);
System.out.println("版本号: " + amri.isMarked());
System.out.println("值: " + amri.getReference());
|
5.Atomic原子操作类
5.1 java原子操作类
Java 中已经有了 CAS 为什么还需要提供Atomic原子操作类操作。
在 Java 并发编程中很容易出现一些并发安全问题,比如i++操作,多个线程并行就有可能获取不到正确的值,解决这个问题最基本的操作是加锁保证线程安全,但是锁这个操作太重了,不是一种很高效的解决方案。
基于 CAS 操作,不需要底层一些线程内核的切换,可以使用 CAS 比较后更新,或者再进行重试。
如: 在有了 CAS 之后,synchronized 性能也变得提升了,不断的进行重试,重试一定次数失败后,实在不成功,进行内核的线程切换操作。
JDK 中为我们提供了Atomic原子操作类,保证线程对基本类型变量的操作,底层也是基于 CAS 来实现。
即使JDK 中不提供这些原子类,我们也可以自己去封装实现,区别点在于可能没 JDK 实现的那么优雅以及稳定。
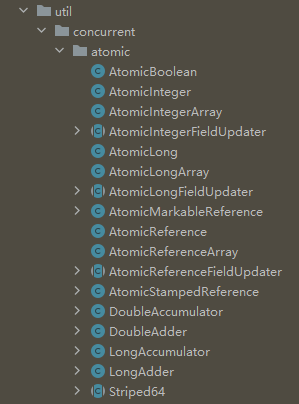
在java.util.concurrent.atomic包里提供了一组原子操作类,可以分为这么几种类型:
- 基本类型:AtomicInteger、AtomicLong、AtomicBoolean
- 引用类型:AtomicReference、AtomicStampedRerence、AtomicMarkableReference
- 数组类型:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
- 对象属性原子修改器:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、 AtomicReferenceFieldUpdater
- 原子类型累加器(jdk1.8增加的类):DoubleAccumulator、DoubleAdder、 LongAccumulator、LongAdder、Striped64
5.2 基本类型以AtomicInteger为例
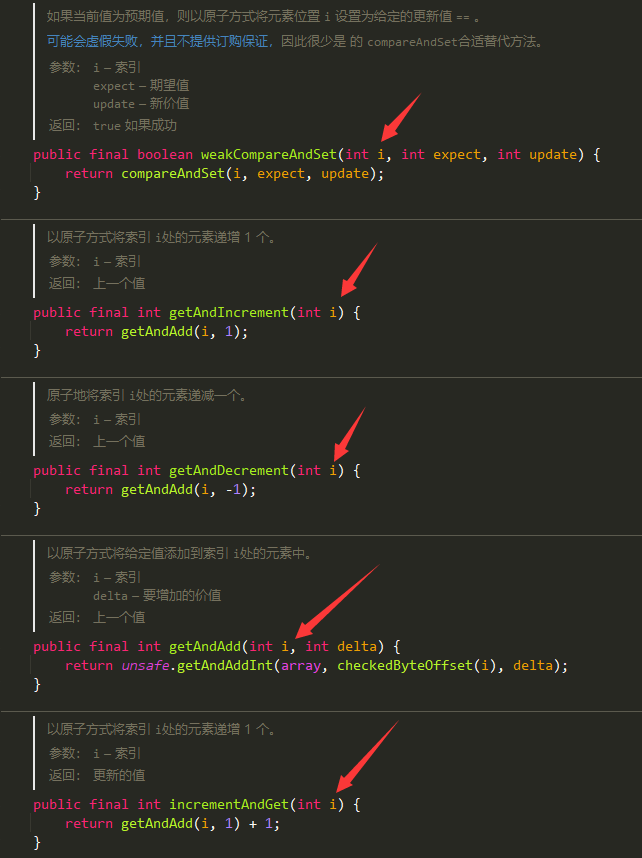
以原子的方式将实例中的原值加1,返回的是自增前的旧值;
1
2
3
| public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
|
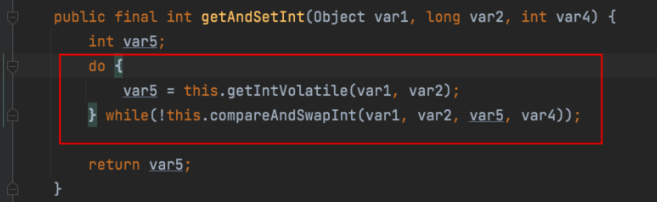
getAndSet(int newValue):将实例中的值更新为新值,并返回旧值
1
2
3
| public final int getAndSet(int newValue) {
return unsafe.getAndSetInt(this, valueOffset, newValue);
}
|
先比较计算,成功则返回,失败则继续重试:
以原子的方式将实例中的原值进行加1操作,并返回最终相加后的结果
1
2
3
| public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
|
以原子方式将输入的数值与实例中原本的值相加,并返回最后的结果
1
2
3
| public final int addAndGet(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}
|
可以看到底层是使用unsasfe cpu指令级原子操作,并且值用 volatile 修饰对每个线程可见,保证可见性。
5.3 原子更新数组类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
AtomicIntegerArray aiArray = new AtomicIntegerArray(2);
aiArray.set(0, 1);
System.out.println(aiArray.get(0));
aiArray.set(1, 2);
System.out.println(aiArray.get(1));
System.out.println("aiArray = " + aiArray);
System.out.println(aiArray.compareAndSet(1, 1, 2));
System.out.println(aiArray.compareAndSet(1, 2, 3));
|
结果
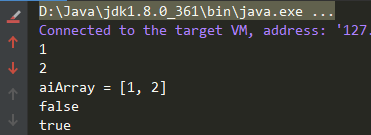
可以看到基本方法一直,只不过数组是对 Index 操作的:
5.4 原子更新引用类型
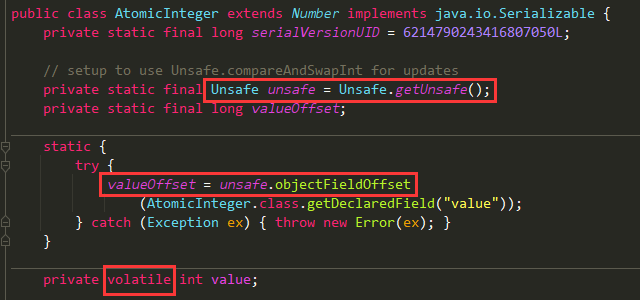
AtomicReference作用是对普通对象的封装,它可以保证你在修改对象引用时的线程安全性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class AtomicReference<V> implements java.io.Serializable {
private static final long serialVersionUID = -1848883965231344442L;
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicReference.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile V value;
...
}
|
还有 AtomicMarkableReference、AtomicStampedReference…
5.5 对象属性原子修改器
对于AtomicIntegerFieldUpdater 的使用稍微有一些限制和约束,约束如下:
(1)字段必须是volatile类型的,在线程之间共享变量时保证立即可见.eg:volatile int value = 3
(2)字段的描述类型(修饰符public/protected/default/private)与调用者与操作对象字段的 关系一致。也就是说调用者能够直接操作对象字段,那么就可以反射进行原子操作。但是对于父 类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
(3)只能是实例变量,不能是类变量,也就是说不能加static关键字。
(4)只能是可修改变量,不能使final变量,因为final的语义就是不可修改。实际上final的语义和 volatile是有冲突的,这两个关键字不能同时存在。
(5)对于AtomicIntegerFieldUpdater和AtomicLongFieldUpdater只能修改int/long类型的字 段,不能修改其包装类型(Integer/Long)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| AtomicIntegerFieldUpdater<Test> atomicIntegerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(Test.class, "i");
Test test = new Test();
atomicIntegerFieldUpdater.set(test, 10);
IntStream.rangeClosed(1, 2).forEach(x -> {
new Thread(() -> {
System.out.println("Thread = " + Thread.currentThread().getName());
for (int i = 0; i < 20; i++) {
int andDecrement = atomicIntegerFieldUpdater.getAndIncrement(test);
System.out.println(Thread.currentThread().getName() + " : " + andDecrement);
}
}).start();
});
|
如果要修改包装类型就需要使用 AtomicReferenceFieldUpdater。
1
2
3
4
5
6
7
| Test2 test2 = new Test2();
AtomicReferenceFieldUpdater<Test2,Integer> atomicReferenceFieldUpdater = AtomicReferenceFieldUpdater.newUpdater(Test2.class,Integer.class,"i");
test2.i=1;
atomicReferenceFieldUpdater.compareAndSet(test2,1,2);
System.out.println(atomicReferenceFieldUpdater.get(test2));
|
5.6 LongAdder/DoubleAdder详解
AtomicLong、AtomicInteger 是利用了底层的CAS操作来提供并发性的。我们都知道CAS 会在cpu上不断的重试,当线程数量少还可以接收,大量并发情况下,会出现大量失败并且不断的自旋重试,导致 CPU 空转,严重影响性能。
为了解决高并发下 AtomicLong、AtomicInteger 自旋瓶颈问题,引入 LongAdder/DoubleAdder 类。
5.6.1 内部原理
AtomicLong中有个内部变量value保存着实际的long值,所有的操作都是针对该变 量进行。
也就是说,高并发环境下,value变量其实是一个热点,也就是N个线程竞争 一个热点。LongAdder的基本思路就是分散热点,将value值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
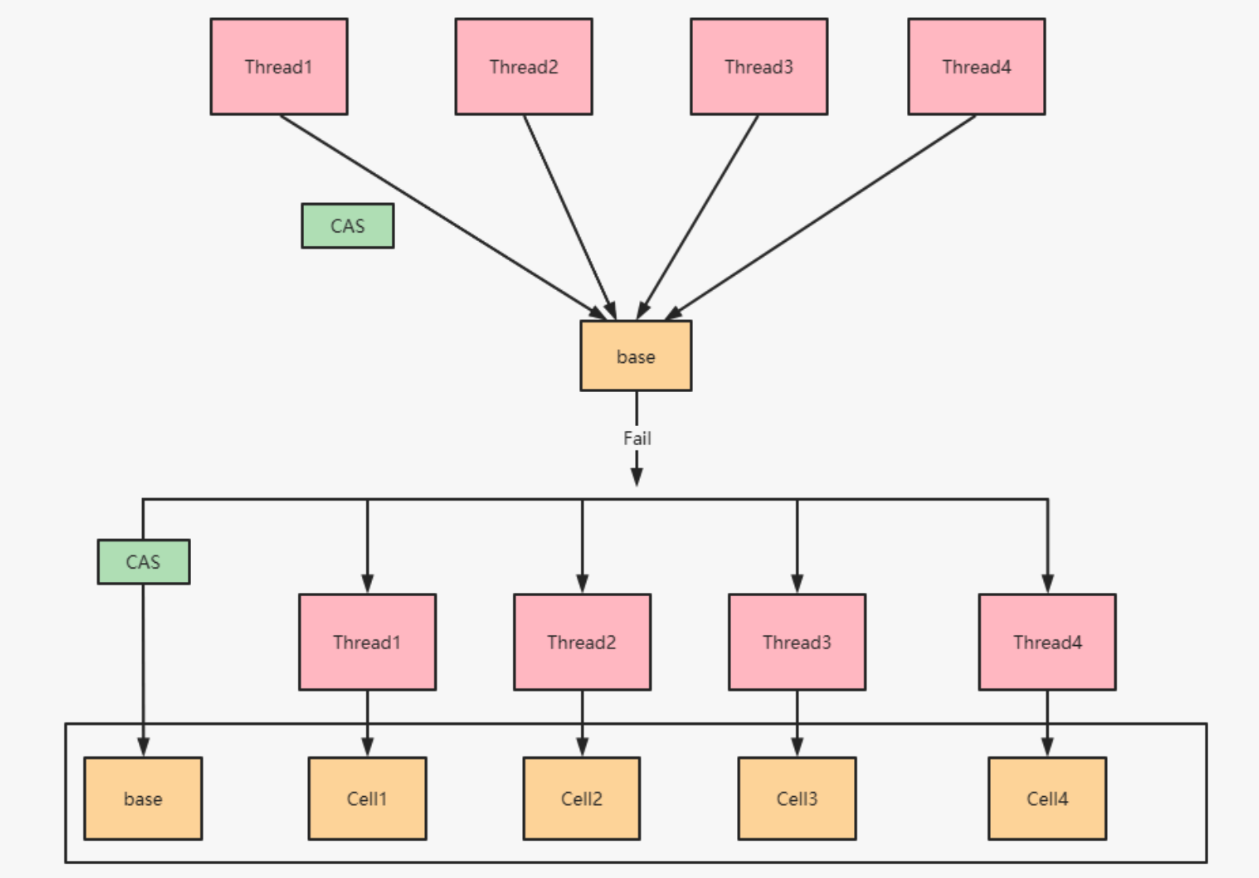
LongAdder内部有一个base变量,一个Cell[]数组: base变量:非竞态条件下,直接累加到该变量上 Cell[]数组:竞态条件下,累加个各个线程自己的槽Cell[i]中。
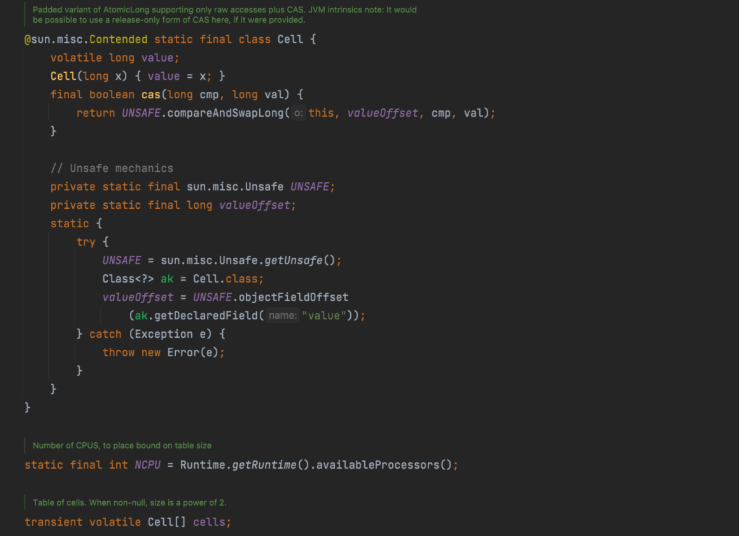
定义了一个内部Cell类,这就是我们之前所说的槽,每个Cell对象存有一个value值,可以通过 Unsafe来CAS操作它的值。
LongAdder中add方法:
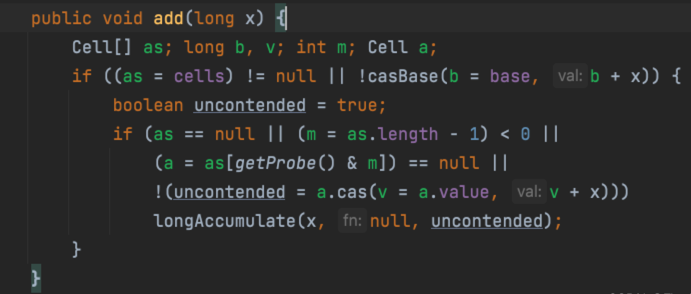
Cell[] 是否初始化,cells是null 则没有则初始化,casBase 方法 b=base值,这个是cas原子操作,表明没有竞争。 如果出现了冲突,则再判断 cells 是否初始化,出现冲突更新base 更新base冲突则查看 一个线程base原子操作,另一个失败则进行 cells初始化 初始化了则 定位hash 指定到 Cell 数组指定曹中,使用cas更新每个槽里的值。
最后将每个槽和base相加起来:
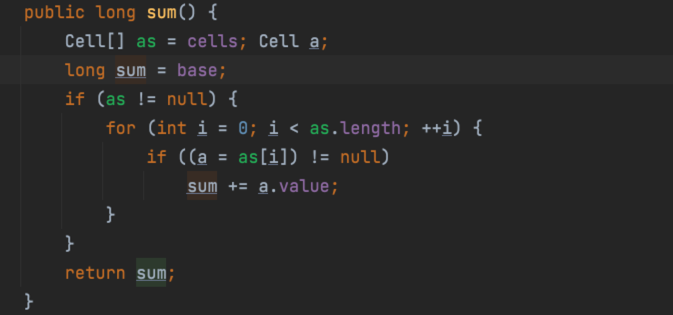
由于计算总和时没有对Cell数组进行加锁,所以在累加过程中可能有其他线程对Cell中的值进 行了修改,也有可能对数组进行了扩容,所以sum返回的值并不是非常精确的,其返回值并不是 一个调用sum方法时的原子快照值。
longAccumelate 这个方法很长
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current();
h = getProbe();
wasUncontended = true;
}
boolean collide = false;
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) {
Cell r = new Cell(x);
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue;
}
}
collide = false;
}
else if (!wasUncontended)
wasUncontended = true;
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
else if (n >= NCPU || cells != as)
collide = false;
else if (!collide)
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue;
}
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try {
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
}
}
|
大致的逻辑是:
只有从未出现过并发冲突的时候,base基数才会使用到,一旦出现了并发冲突,之后所有的操作 都只针对Cell[]数组中的单元Cell。
如果Cell[]数组未初始化,会调用父类的longAccumelate去初始化Cell[], 如果Cell[]已经初始化 但是冲突发生在Cell单元内,则也调用父类的longAccumelate,此时可能就需要对Cell[]扩容 了。
这也是LongAdder设计的精妙之处:尽量减少热点冲突,不到最后万不得已,尽量将CAS操作延迟。
5.6.2 LongAccumulator
LongAccumulator是LongAdder的增强版。LongAdder只能针对数值的进行加减运算。LongAccumulator内部原理和LongAdder几乎完全一样,都是使用了父类Striped64的longAccumulate方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
LongAccumulator longAccumulator = new LongAccumulator((x,y)-> x + y,10);
for (int i = 1; i <= 100; i++) {
int finalI = i;
new Thread(()->{
longAccumulator.accumulate(finalI);
}).start();
}
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(longAccumulator.get());
|
最后
CAS 和 加锁相比,CAS 更加轻量,但也带来了两个问题一个是ABA问题、一个是自旋时间问题。
