04-Java性能优化实战
欲速则不达,欲达则欲速! —— 佚名
性能优化更多要求我们关注整体效果,兼顾可靠性、扩展性,以及极端的异常场景。
1. 理论分析
1.1 衡量指标
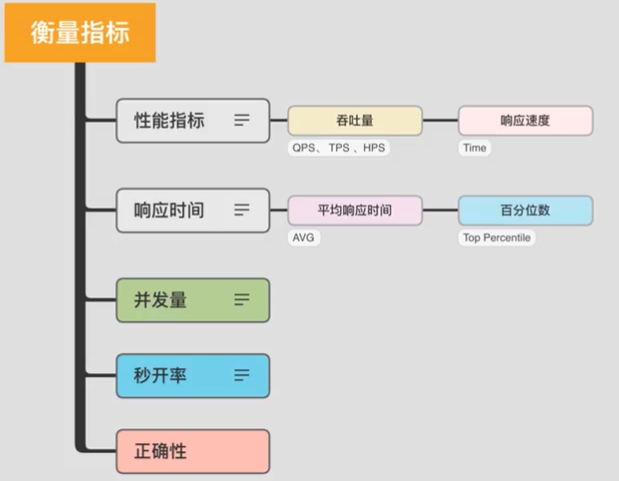
吞吐量和响应速度
吞吐量:
- QPS 每秒查询数量,TPS 每秒事务数量,HPS 每秒HTTP请求数量
- 并行执行的优化,合理利用计算资源达到目标
响应速度:
- Time 时间
- 串行执行的优化,优化执行步骤解决问题
- 响应速度提升,吞吐量也就跟着提升了
响应时间衡量
平均响应时间
并发量
同时能为多个用户提供服务的能力。
1.2 常用理论
基准测试
基准测试(Benchmark),测试某个程序的最佳性能。
测试之前,对应用进行预热,消除JIT编译器等因素的影响,java组件 JMH 就可以消除这些差异。
木桶理论
木桶理论:系统整体的性能,取决于系统重最慢的组件。
比如数据库应用中,制约性能最严重的就是磁盘I/O问题,硬盘是短板,也就是需要补齐这个短板。
1.3 注意点
- 数字说话而不是猜想
- 根据难度和影响程度:击破影响最大的点,将其他因素逐一击破
- 个体数据不足信
- 小批量数据的场景,需要有响应之间直方图去分析
- 不要过早优化和过度优化
- 项目开发和性能优化,要作为两个独立的步骤进行,
性能优化在项目功能大体进入稳定状态时在进行
- 项目开发和性能优化,要作为两个独立的步骤进行,
- 保持良好编码习惯
- 好的编码习惯、合适的设计模式
1.4 七类手段
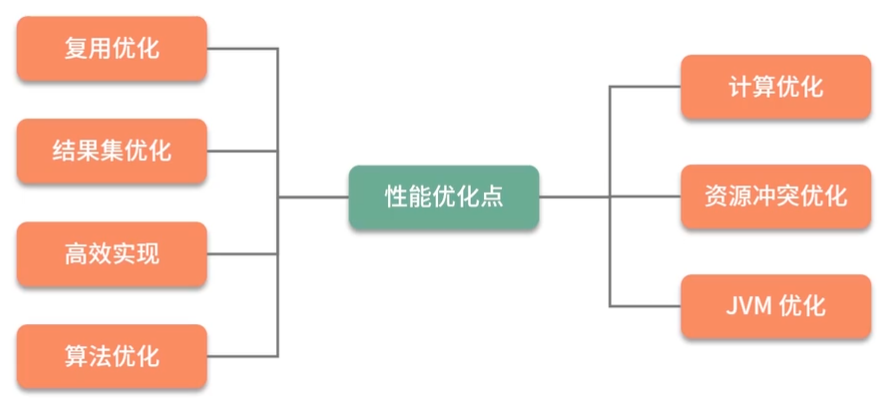
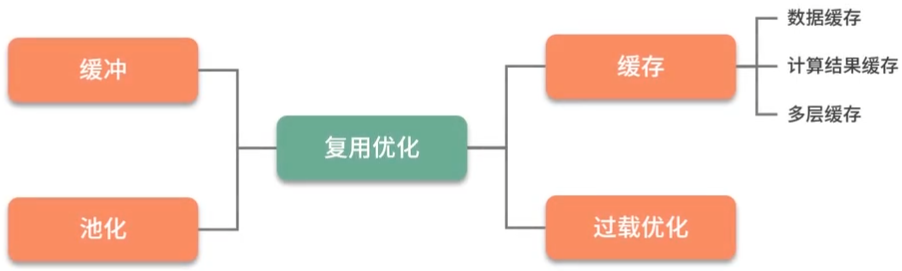
复用优化
代码:重复代码提取。
数据:数据复用,缓冲 Buffer - 主要针对写操作、缓存 Cache - 主要针对读操作
计算优化
并行执行:多机、多进程、多线程
同步变异步:涉及编程逻辑的改变
惰性加载:需要时才加载。
结果集优化
数据:传输数据的效率和解析率的提高,如 JSON 、ProtoBuf
压缩:Nginx 和 feign 的 Gzip 压缩,使传输内容保持紧凑
批量:时效要求不高,处理能力有高要求的情况
资源冲突优化
锁:乐观锁效率更高
算法优化
空间换时间:CPU紧张的业务中,空间换时间的方式提高性能
算法本身:采用降低时间负责度的算法,递归、二分、排序、动态规划等
高效实现
组件:使用高性能组件,如长连接 netty 等
JVM 优化
垃圾回收器:广泛使用的是 G1
1.5 性能瓶颈
CPU
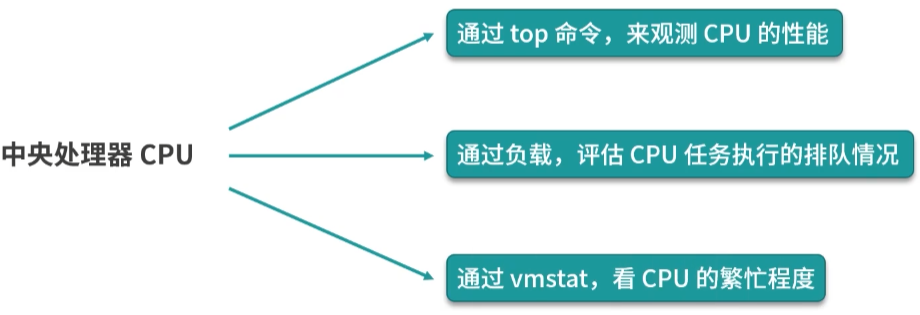
top 命令:CPU 占用情况查看。
uptime 命令:查看负载情况,分别显示 1min、5min、15min的数值。
vmstat 命令:CPU 繁忙程度查看。
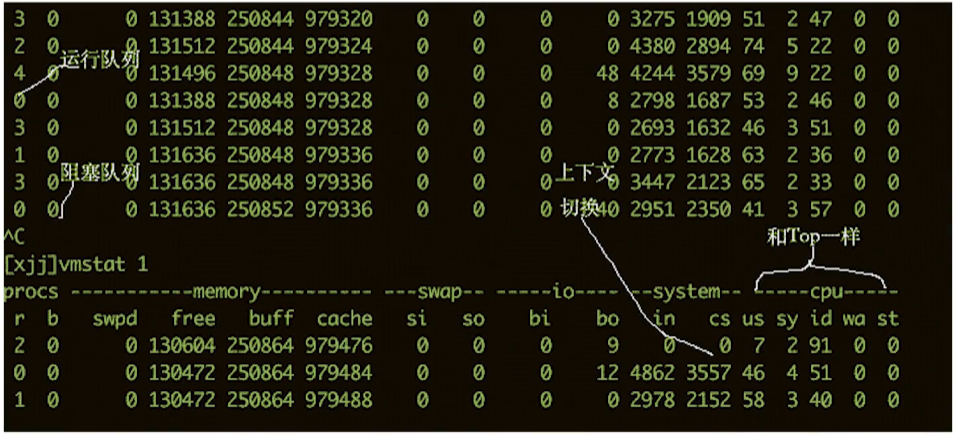
每个进程上下文切换的具体数量,查看内存映射文件获取:
2
3
4
5#进程id 2788
[root@localhost~]# cat /proc/2788/status
...
voluntary_ctxt_switches: 93950
nonvoluntary_ctxt_switches: 171204
内存
一些程序的默认行为会对性能有所影响,比如JVM的 -XX:+AlwaysPreTouch 参数。默认情况下,JVM虽然配置了Xmx、Xms等参数,指定堆的初始化大小和最大大小。如果加上 AlwaysPreTouch,JVM会在启动的时候,把所有的内存预先分配。
I/O
缓冲区:解决速度差异的唯一工具。
iostat 命令:查看磁盘I/O情况的工具。
零拷贝:非常重要的性能优化手段,如kafka、Nginx都使用了这种手段。
2. 工具支持
2.1 nmon 获取系统性能数据
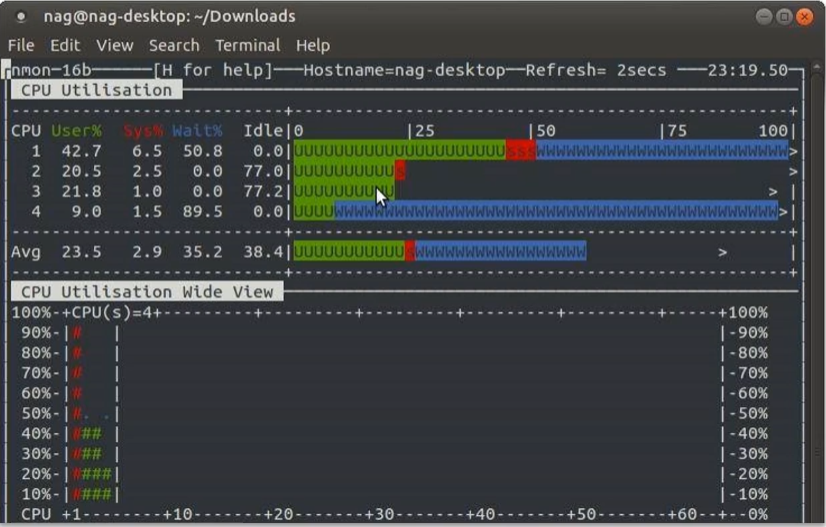
选择对应的版本,如 ./nmon_x86_64_centos7
- 按 C 可以加入 CPU 面板
- 按 M 可以加入 内存 面板
- 按 N 可以加入 网络 面板
- 按 D 可以加入 磁盘 面板
1 | |
监控:最流行的组合是 prometheus + grafana + telegraf 搭建功能强大的监控平台。
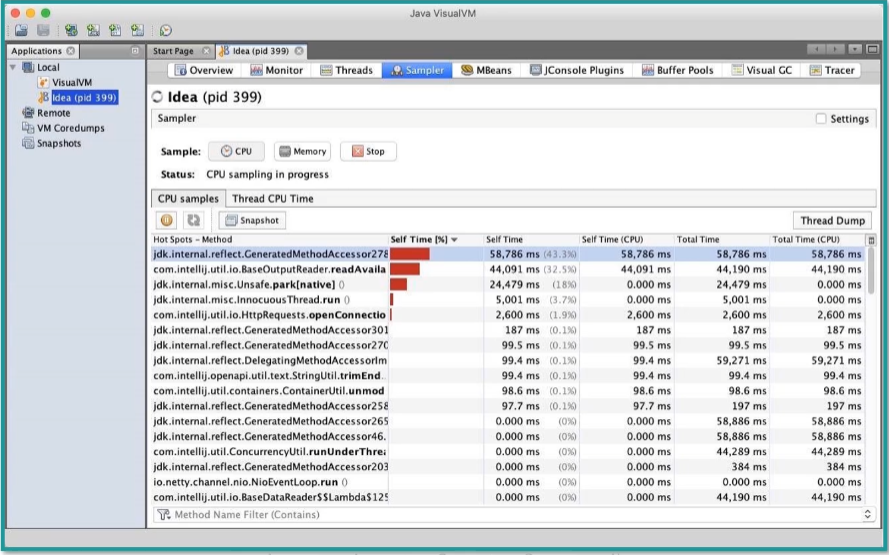
2.2 jvisualvm 获取JVM性能数据
插件上加入 jmx 参数:

参数的含义:在 14000 端口上开启 jmx,同时不需要 ssl
2.3 jmc 获取java应用详细性能数据
录制1分钟后查看线程的执行情况:

2.4 arthas 获取单个请求的调用链耗时
主要使用 trace 命令,参考:Arthas阿里开源诊断工具
2.5 wrk 获取web接口的性能数据
HTTP 压测工具,和 ab命令类似,命令行工具,参考:https://github.com/wg/wrk
扩展:jmeter 是专业的压测工具,可以生成压测报告。
2.6 java JMH 精准测量方法性能
如上图常用的java代码耗时计算,但并不是一定准确。因为 JVM执行时,会对一些代码或频繁执行的逻辑,进行 JIT编译和内联优化,在得到一个稳定的测试结果之前,需要先循环上万次进行预热。
JMH (the Java Microbenchmark Harness) 基准测试的工具,测量精读非常高,可达纳秒级别。它已经在 JDK12 中被默认包含,其他版本需要单独引入。
使用参考:https://www.cnblogs.com/54chensongxia/p/15485421.html
官方示例:https://hg.openjdk.org/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/
使用前需引入依赖:
1 | |
1 | |
图形化结果:jmh-result.json 文件
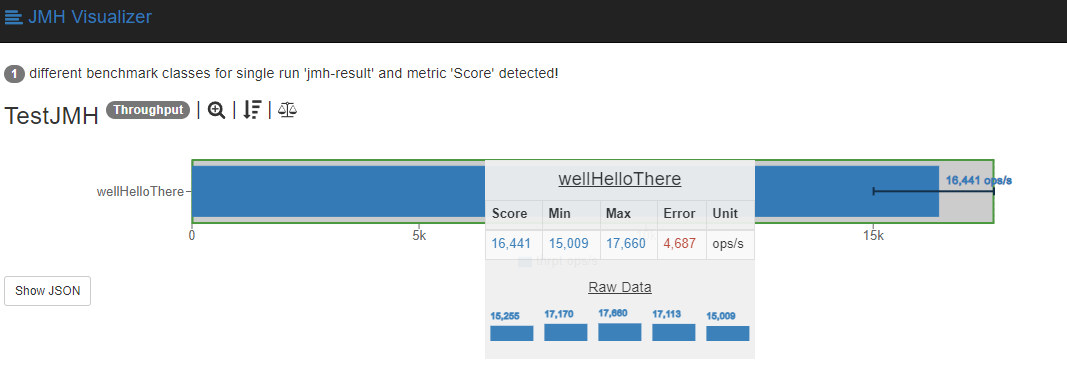
常用注解:
- @Warmup:预热所需要配置的一些基本测试参数,可用于类或者方法上。
- @Measurement:实际调用方法所需要配置的一些基本测试参数,可用于类或者方法上,参数和
@Warmup相同。 - @BenchmarkMode:用来配置 Mode 选项,可用于类或者方法上,这个注解的 value 是一个数组,可以把几种 Mode 集合在一起执行,如:
@BenchmarkMode({Mode.SampleTime, Mode.AverageTime}),还可以设置为Mode.All,即全部执行一遍。 - @OutputTimeUnit:为统计结果的时间单位,可用于类或者方法注解。
- @Fork:进行 fork 的次数,可用于类或者方法上。一般设置为 1 只使用一个进程进行测试;如果 fork 数是 2 的话,则 JMH 会 fork 出两个进程来进行测试。
独立的进程进行测试的,环境数据隔离。它也可以通过 jvmArgsAppend 参数来传入 JVM 参数。

- @Threads:每个进程中的测试线程,可用于类或者方法上。如果配置了 Threads.MAX 则使用和处理机器核数相同的线程数。
- @State:通过 State 可以指定一个对象的作用范围,JMH 根据 scope 来进行实例化和共享操作。
- @Param:指定某项参数的多种情况,特别适合用来测试一个函数在不同的参数输入的情况下的性能,只能作用在字段上,使用该注解必须定义 @State 注解。
常用示例 - 输出耗时:
1 | |
使用@BenchmarkMode注解,将测试模式设置为Mode.AverageTime,表示测试方法的耗时为平均时间。然后使用@OutputTimeUnit注解,将输出时间单位设置为TimeUnit.MILLISECONDS,表示以毫秒为单位输出耗时。
在运行该示例代码时,控制台输出将显示每个操作的平均耗时(ms/ops)。
2.7 性能深挖工具

3. 代码性能优化
3.1 缓冲 buffer
Buffer 缓冲:数据一般只使用一次,等待缓冲区满了,就执行 flush 操作。
如 JVM 的堆,就是一个缓冲的概念,代码在堆中不停的生成对象,垃圾回收器在堆中回收。
文件读写流:
- 缓冲保存在内存中,显著提升读写速度,折中的值是 8k,也就是 8192 字节。
日志缓冲:
- 高速日志组件 SLF4J 实现的 Logback,缓冲队列实现异步日志
- Logback 异步日志配置:

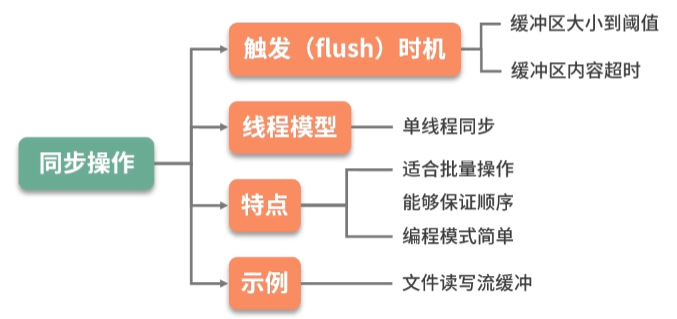
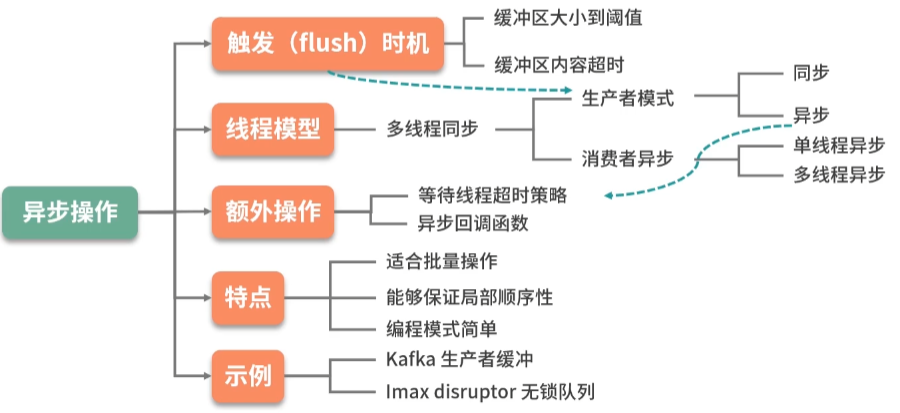
★★★★★缓冲区优化思路:
- 同步操作:控制缓冲区大小,把握处理的时机
- 异步操作:多线程,等待线程超时策略,异步回调函数
- StringBuilder 和 StringBuffer:将要处理的字符串缓冲起来,提高拼接性能
- flush函数强制刷新数据:在写入磁盘或网络I/O时
- MySQL的InnoDB中,配置合理的 innodb_buffer_pool_size 来减少换页,增加数据库的性能
注意事项:
内容写入缓冲区前,需要
先预写日志,断电/异常退出/kill -9时等故障重启时,根据日志进行数据恢复。
3.2 缓存 cache
缓存 Cache:数据被载入之后,可以多次使用,数据将会共享多次。
缓存的指标:命中率。
影响命中率的因素:
- 缓存容量
- 数据集类型
- 缓存失效策略
本地缓存 (堆内缓存)
推荐比如 Guava 的 LoadingCache(LC),是堆内缓存工具。也可以理解为 本地缓存。
1 | |
具体使用参考:https://www.jianshu.com/p/3d546868a1db
分布式缓存(Redis)
java的Redis客户端 jedis、redisson、lettuce(Spring默认使用的是lettuce)
- 引入 spring-boot-starter-data-redis 时,使用 redisTemplate.opsXxx 方法操作缓存
- 引入 spring-boot-starter-cache 时,使用注解+AOP方式,可以在堆内缓存和分布式缓存之间切换
- 启动类加 @EnableCaching
- @CacheConfig 注解注入要使用的缓存框架
- @Cacheable 对资源进行缓存
- @Cacheable 缓存里没有,则将方法返回值进行缓存
- @CachePut 每次执行该方法,都将返回值缓存起来
- @CacheEvict 执行方法的时候,清除某些缓存值
示例:秒杀业务处理

- Lua 脚本完成秒杀:解决同步问题
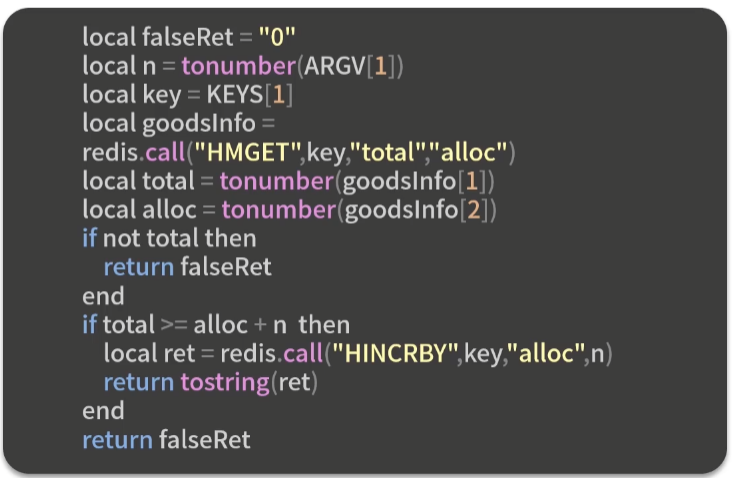
- 秒杀代码

注意事项:
缓存一致性问题:懒加载的方式。
- 读缓存时无缓存数据则执行业务逻辑载入缓存
- 与缓存有关的资源变动时,先删除相应的缓存项,再对资源进行更新(此时即使资源更新失败也没问题)
3.3 池化对象 pool
连接池
公共池化包 Commons Pool 2.0
- Jedis 是在 Commons Pool 2.0 的基础上封装的。
- HikariCP 是数据库连接池中速度最快的。

常见连接池 http连接池、RPC使用连接池技术、Dubbo连接池技术等…
3.4 大对象复用 obj
占用资源多,垃圾回收花费时间递增;网络I/O变大;解析和处理耗时高。
大对象回收:切断与大对象的引用关系,便于让大对象及时回收。
集合大对象扩容:初始化容量的考量关联扩容因子来设计。
保持合适的对象粒度:对象存储缓存的时候,使用 hash 结构代替 JSON 结构,加快字段获取和信息流转速度。
Bitmap 把对象变小:100亿的 Boolean 数据只占128M内存,java虚拟机中对 Boolean 和 int 一样都是 32位。
数据的冷热分离:数据的时间维度划分。数据双写、写入MQ分发冷热库、使用Binlog同步(Canal组件结合MQ)
3.5 设计模式 design
和性能相关的几个设计模式:代理模式、单例模式、享元模式、原型模式…
代理模式:jdk方式 和 cglib 的创建和执行差别不大,spring选择 cglib是因为可以代理普通类。
单例模式:double check 双检锁单例,兼顾安全和效率,不推荐使用。推荐枚举实现懒加载的单例。
享元模式:共享技术最大限度复用对象。对象复用角度属于 享元模式,功能角度属于 策略模式。
原型模式:加快创建对象的一种思想。
对性能帮助最大的是 生产者消费者模式,比如异步消息、reactor模型等…
3.6 多线程 threads
使用线程池 :ThreadPoolExector
I/O密集型:核心线程数量 = I/O任务的数量,最大线程数 = 核心线程数 × 2,效果是最好的。在充分利用CPU资源的同时,确保有足够的线程来处理业务逻辑。
CPU密集型:核心线程数量 = CPU核数,最大线程数 = 核心线程数,效率是最高的。因为任务之间切换少,可以充分压榨CPU的计算性能。
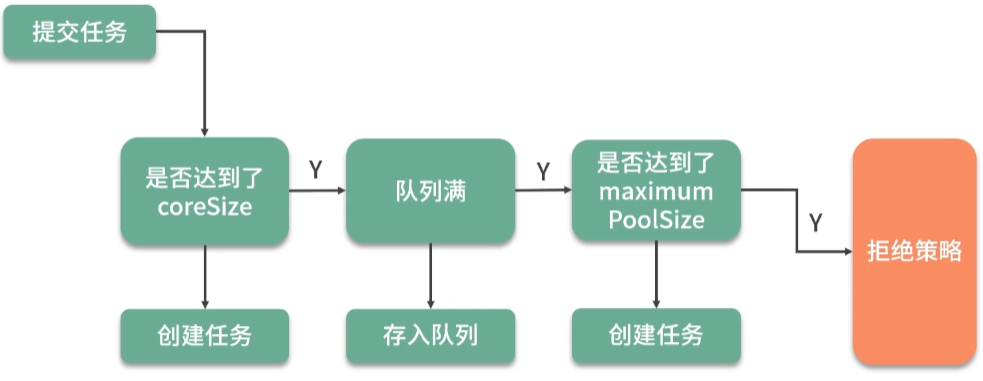
使用线程池:SpringBoot启动类上加 @EnableAsync 注解,在具体的方法上加 @Async(“线程池bean”)
注意事项:
- 多线程中,如果抛出了异常,该异常没有被 try-catch 则会导致该线程异常中止。
3.7 SpringBoot服务性能优化
- 在 SpringBoot 的配置文件中,通过如下配置开启 gzip,对结果集去除无用的信息和合理的压缩来提高性能。
1 | |
同时针对 feign 的底层网络工具改为
OkHTTP,使用 OkHTTP 的透明压缩(默认开启 gzip),即可完成服务间调用的信息压缩。将结果集合并,使用批量的方式,可以显著增加性能
3.8 代码优化法则
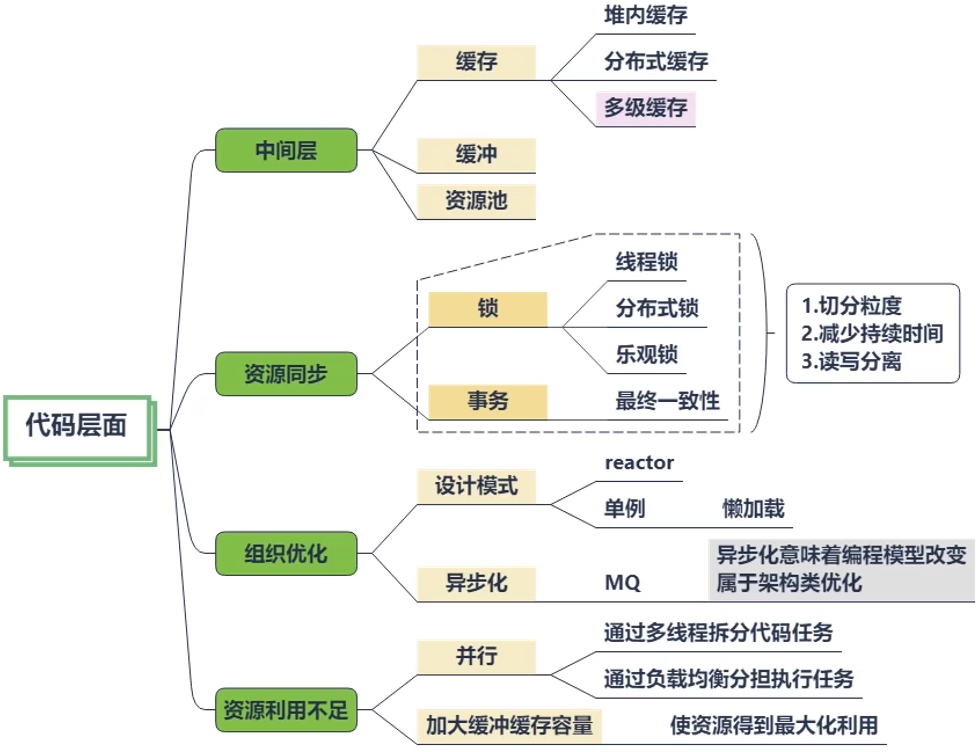
使用局部变量可避免在堆上分配:堆资源是多线程共享的,过多的对象会造成GC压力,局部变量的方式,将变量在栈上分配。减少变量的作用范围:除了循环中。访问静态变量直接使用类名:对象操作会增加寻址操作。字符串拼接:使用 StringBuilder 或 StringBuffer,不要使用 + 号。重写对象的 HashCode,不要简单的返回固定值:固定返回 0 相当于把 hash 寻址的功能废除了。HashMap 等集合初始化的时候,指定初始值大小:大对象的复用,减少扩容带来的损耗。遍历 Map 的时候使用 EntrySet 方法:比 KeySet 步骤更少。不要在多线程下使用同一个 Random:Random类的seed会在并发访问的情况下发生竞争,造成性能降低。建议在多线程环境下使用ThreaLocalRandom类。也可以通过 JVM 配置加入-Djava.security.egd=file:/dev/./urandom使用 urandom 随机生成器,在随机数获取时,速度会更快。自增推荐使用 LongAddr:也可以使用原子类 AtomicLong。不要使用异常控制程序流程:异常比条件判断更消耗资源。不要在循环中使用 try-catch:应该放在最外层。不要捕捉 RuntimeException:应该在编码层面就要解决掉。合理使用 PreparedStatement:预编译对 SQL 进行提速。日志打印注意事项-占位符:使用占位符的方式提高日志的性能,减少事务的作用范围:事务的隔离性使用锁实现的,锁对性能有损耗。使用位移操作代替乘除法:位移操作会极大提高性能。不要打印大集合或大集合的toString方法:非常不好的习惯,占用大量的内存 I/O。程序中少用反射:反射通过解析字节码实现的,性能不太理想。正则表达式可以预先编译,加快速度:Pattern 可以作为类的静态变量使用来预编译。- … 参考汇总图
4. JVM虚拟机优化
参考1:JVM参数调优
参考2:4Cpu8G的JVM参数设置方案
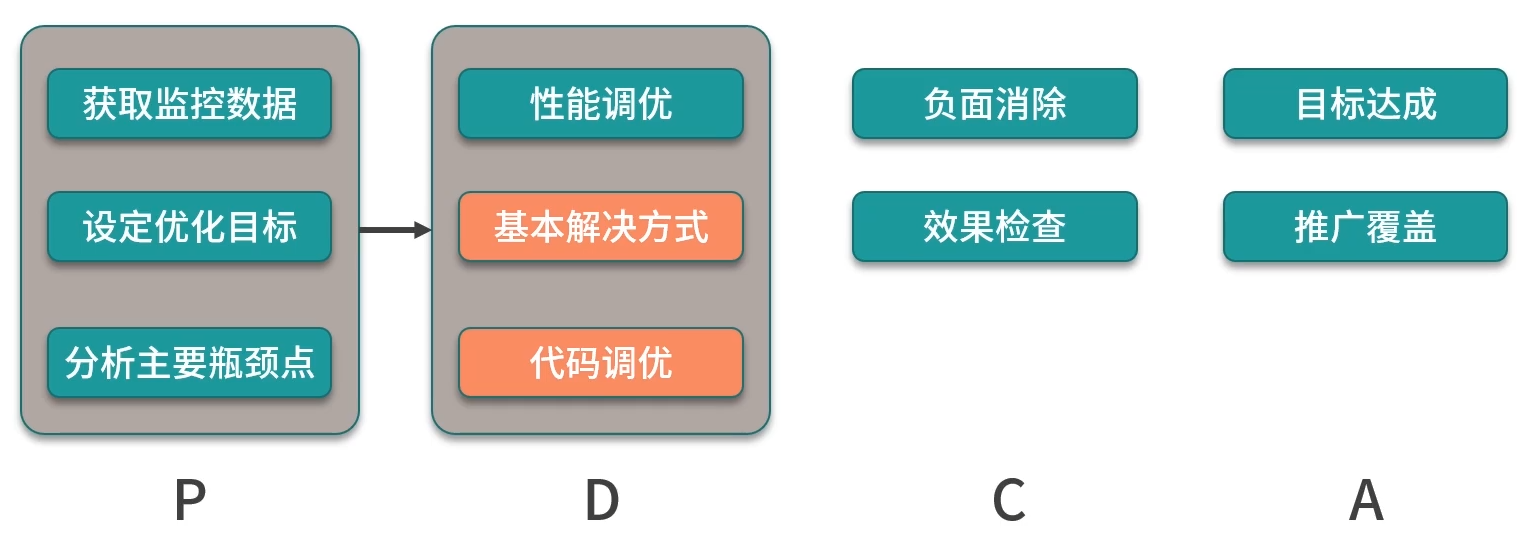
5. 性能优化过程方法
- 优化目标
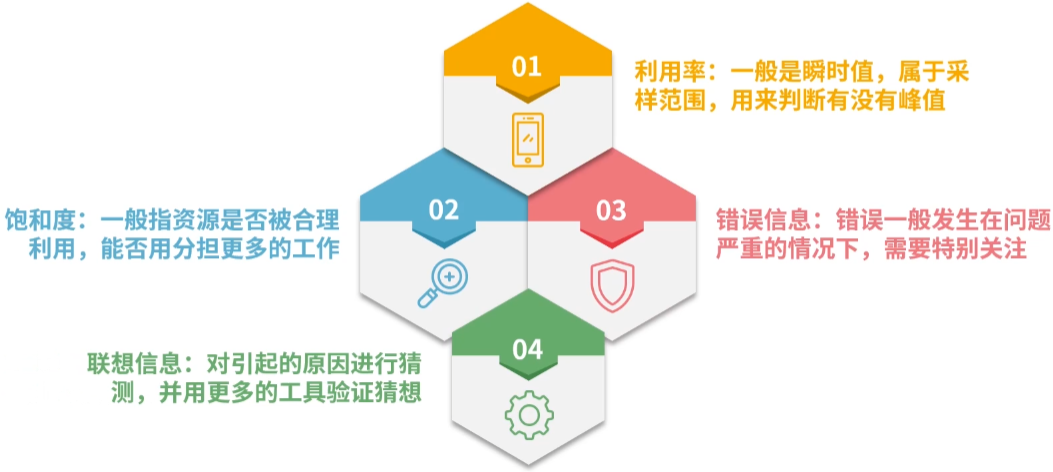
- 核心维度
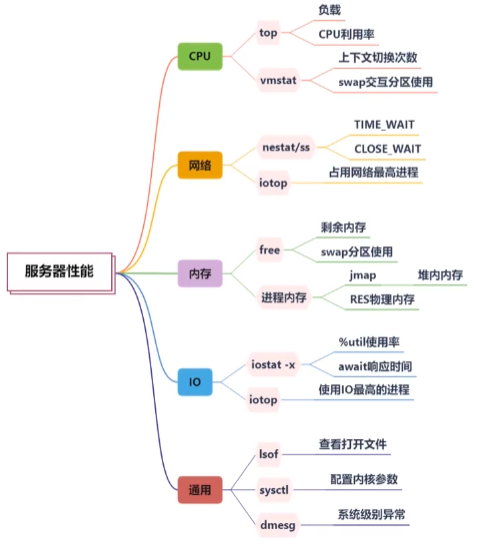
CPU
- top 命令,注意它的负载 load 和 使用率。比如
top -Hp便能很容易获取占用 CPU 最高的线程,进行针对性的优化。 - vmstat 命令,也可以看到一些运行状况,如上下文切换和swap交换分区使用情况。
- top 命令,注意它的负载 load 和 使用率。比如
内存
- free 命令,关注剩余内存的大小 free。
- top 命令,RES 列显示的就是进程实际占用的物理内存。
网络I/O
- iotop 命令,可以看到占用 I/O 最多的进程。
- netstat 命令 或 ss 命令,可以看到当前机器上的网络连接汇总。
- iostat 命令,可以查看磁盘 I/O 的使用情况。
通用
- lsof 命令,可以查看当前进程所关联的所有资源。
- sysctl 命令,可以查看当前系统内核的配置参数。
- dmesg 命令,可以显示系统级别的一些信息。
- 基本解决方式
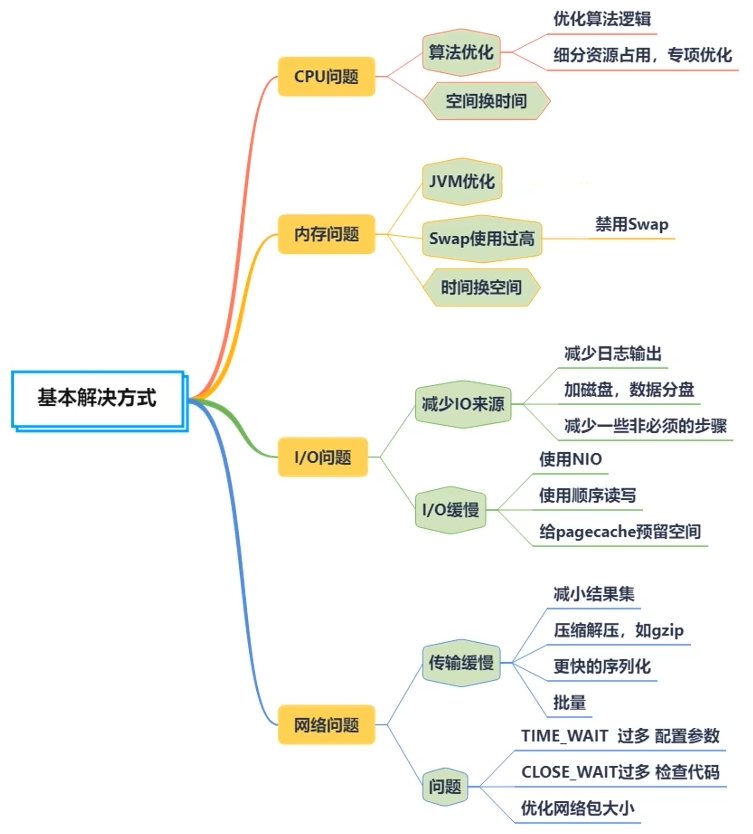
- PDCA 循环方法论