text = f""" You should express what you want a model to do by \ providing instructions that are as clear and \ specific as you can possibly make them. \ This will guide the model towards the desired output, \ and reduce the chances of receiving irrelevant \ or incorrect responses. Don't confuse writing a \ clear prompt with writing a short prompt. \ In many cases, longer prompts provide more clarity \ and context for the model, which can lead to \ more detailed and relevant outputs. """ prompt = f""" Summarize the text delimited by triple backticks \ into a single sentence. ```{text}``` """ response = get_completion(prompt) print(response)
output
1
Clear and specific instructions should be provided to guide a model towards the desired output, and longer prompts can provide more clarity and context for the model, leading to more detailed and relevant outputs.
prompt = f""" Generate a list of three made-up book titles along \ with their authors and genres. Provide them in JSON format with the following keys: book_id, title, author, genre. """ response = get_completion(prompt) print(response)
text_1 = f""" Making a cup of tea is easy! First, you need to get some \ water boiling. While that's happening, \ grab a cup and put a tea bag in it. Once the water is \ hot enough, just pour it over the tea bag. \ Let it sit for a bit so the tea can steep. After a \ few minutes, take out the tea bag. If you \ like, you can add some sugar or milk to taste. \ And that's it! You've got yourself a delicious \ cup of tea to enjoy. """ prompt = f""" You will be provided with text delimited by triple quotes. If it contains a sequence of instructions, \ re-write those instructions in the following format: Step 1 - ... Step 2 - … … Step N - … If the text does not contain a sequence of instructions, \ then simply write \"No steps provided.\" \"\"\"{text_1}\"\"\" """ response = get_completion(prompt) print("Completion for Text 1:") print(response)
output
1 2 3 4 5 6 7 8
Completion for Text 1: Step 1 - Get some water boiling. Step 2 - Grab a cup andputa tea bag init. Step 3 - Once the water is hot enough, pour it over the tea bag. Step 4 - Let it sit fora bit so the tea can steep. Step 5 - After a few minutes, take out the tea bag. Step 6 - Add some sugar or milk to taste. Step 7 - Enjoy your delicious cup of tea!
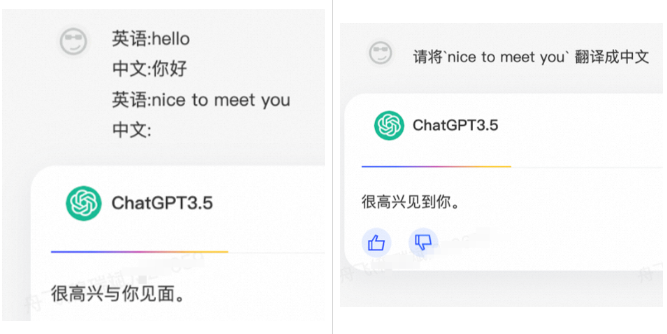
少样本提示( “Few-shot” prompting)
通过提供给模型一个或多个样本的提示,模型可以更加清楚需要你预期的输出。
关于few-shot learning,感兴趣的同学可以看一下GPT-3的论文:Language Models are Few-Shot Learners
Prompt示例:
1 2 3 4 5 6 7 8 9 10 11
prompt = f""" Your task is to answer in a consistent style. <child>: Teach me about patience. <grandparent>: The river that carves the deepest \ valley flows from a modest spring; the \ grandest symphony originates from a single note; \ the most intricate tapestry begins with a solitary thread. <child>: Teach me about resilience. """ response = get_completion(prompt) print(response)
output
1
<grandparent>: Resilience is like a tree that bends withthe wind but never breaks. It isthe ability to bounce backfrom adversit y and keep moving forward, even when things get tough. Just like a tree that grows stronger with each storm it weathers, resilience is a quality that can be developed and strengthened overtime.
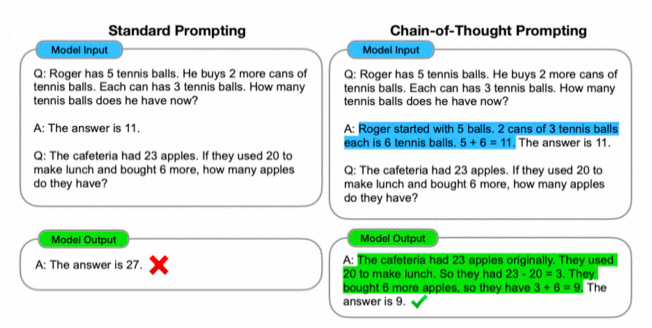
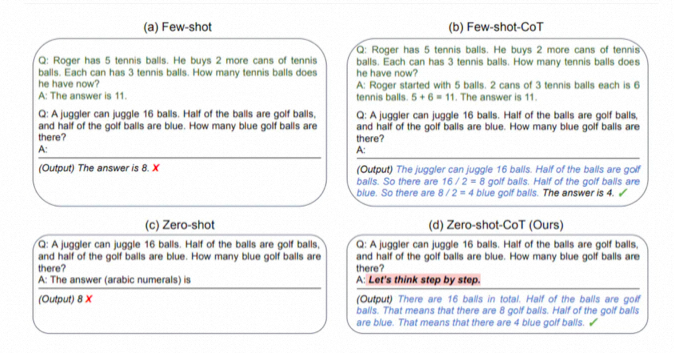
2、给模型时间来“思考”(Give the model time to “think” )
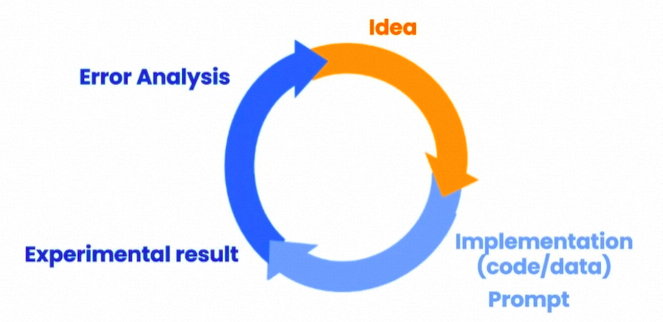
这个原则利用了思维链的方法,将复杂任务拆成N个顺序的子任务,这样可以让模型一步一步思考,从而给出更精准的输出。具体可以参见paper:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models。
策略1:指定完成任务所需的步骤 (Specify the steps required to complete a task)
text = f""" In a charming village, siblings Jack and Jill set out on \ a quest to fetch water from a hilltop \ well. As they climbed, singing joyfully, misfortune \ struck—Jack tripped on a stone and tumbled \ down the hill, with Jill following suit. \ Though slightly battered, the pair returned home to \ comforting embraces. Despite the mishap, \ their adventurous spirits remained undimmed, and they \ continued exploring with delight. """ # example 1 prompt_1 = f""" Perform the following actions: | 1 - Summarize the following text delimited by triple \ backticks with 1 sentence. 2 - Translate the summary into French. 3 - List each name in the French summary. 4 - Output a json object that contains the following \ keys: french_summary, num_names. Separate your answers with line breaks. Text: ```{text}``` """ response = get_completion(prompt_1) print("Completion for prompt 1:") print(response)
output:
1 2 3 4 5 6 7 8
Completion for prompt 1: Two siblings, Jack and Jill, go on a quest tofetch water from a well on a hilltop, but misfortune strikes and they both tumble down the hill, returning home slightly battered but with their adventurous spirits undimmed. Deux frères et sœurs, Jack et Jill, partent en quête d'eau d'un puits sur une colline, mais un malheur frappe et ils tombent tous les deux de la colline, rentrant chez eux légèrement meurtris mais avec leur esprit d'aventure intact. Noms: Jack, Jill. { "french_summary": "Deux frères et sœurs, Jack et Jill, partent en quête d'eau d'un puits sur une colline, mais un malheur frappe et ils tombent tous les deux de la colline, rentrant chez eux légèrement meurtris mais avec leur esprit d'aventure intact.", "num_names": 2 }
prompt_2 = f""" Your task isto perform the following actions: - Summarize the following text delimited by <> with 1 sentence. - Translate the summary into French. - List each name in the French summary. - Output a json object that contains the following keys: french_summary, num_names.
Use the following format: Text: <text to summarize> Summary: <summary> Translation: <summary translation> Names: <list of names in Italian summary> Output JSON: <json with summary and num_names>
Completion for prompt 2: Summary: Jack and Jill go on a quest to fetch water, but misfortune strikes and they tumble down the hill, returning home slightly battered butwith their adventurous spirits undimmed. Translation: Jack et Jill partent en quête d'eau, mais un malheur frappe et ils tombent de la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts. Names: Jack, Jill Output JSON: { "french_summary": "Jack et Jill partent en quête d'eau, mais un malheur frappe et ils tombent de la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.", "num_names": 2 }
策略2:在匆忙得出结论之前,让模型自己找出解决方案(Instruct the model to work out its own solution before rushing to a conclusion)
prompt = f""" Determine if the student's solution is correct or not. Question: I'm building a solar power installation and I need \ help working out the financials. - Land costs $100 / square foot - I can buy solar panels for $250 / square foot - I negotiated a contract for maintenance that will cost \ me a flat $100k per year, and an additional $10 / square \ foot What is the total cost for the first year of operations as a function of the number of square feet. Student's Solution: Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000 """ response = get_completion(prompt) print(response)
prompt = f""" Your task is to determine if the student's solution \ is correct or not. To solve the problem do the following: - First, work out your own solution to the problem. - Then compare your solution to the student's solution \ and evaluate if the student's solution is correct or not. Don't decide if the student's solution is correct until you have done the problem yourself. Use the following format: Question: ``` question here ``` Student's solution: ``` student's solution here ``` Actual solution: ``` steps to work out the solution and your solution here ``` Is the student's solution the same as actual solution \ just calculated: ``` yes or no ``` Student grade: ``` correct or incorrect ``` Question: ``` I'm building a solar power installation and I need help \ working out the financials. - Land costs $100 / square foot - I can buy solar panels for $250 / square foot - I negotiated a contract for maintenance that will cost \ me a flat $100k per year, and an additional $10 / square \ foot What is the total cost for the first year of operations \ as a function of the number of square feet. ``` Student's solution: ``` Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000 ``` Actual solution: """ response = get_completion(prompt) print(response)
正确的输出:
1 2 3 4 5 6 7 8 9 10
Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 10x Total cost: 100x + 250x + 100,000 + 10x = 360x + 100,000 Is the student's solution the same as actual solution just calculated: No Student grade: Incorrect
针对这个问题,作者提供了一个比较有效的方法可以缓解模型的幻觉问题:让模型给出相关信息,并基于相关信息给我回答。比如告诉模型:“First find relevant information, then answer the question based on the relevant information”。
3.2 技巧
零样本
分类的实例
prompt:
1 2 3
Classify the textinto neutral, negative or positive. Text: I think the vacation is okay. Sentiment:
A "whatpu" is a small, furry animal native to Tanzania. An example ofasentence that usesthe word whatpu is:We were traveling in Africa and we saw these very cute whatpus. To doa"farduddle" means to jump up and down really fast. An example ofasentence that usesthe word farduddle is:
输出:
1
When we won the game, we all started to farduddle in celebration.
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False. The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24. A: Adding all the odd numbers (17, 19) gives 36. The answer is True. The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24. A: Adding all the odd numbers (11, 13) gives 24. The answer is True. The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2. A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False. The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A:
output:
1
Addingall the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is F alse.
The odd numbers in this group add up to an even number: 4, 8, 9, 15,12, 2, 1.A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.The odd numbers in this group add up to an even number: 15, 32, 5 , 13, 82, 7, 1. A:
输出:
1
Addingall the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.
I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
输出:
1
11 apples
答案不正确!现在让我们尝试使用特殊提示。
prompt:
1 2 3 4 5
I went tothe market and bought 10 apples. I gave 2 apples tothe neighbor and2tothe repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with? Let's think step by step.
输出:
1 2 3 4
First, you started with 10 apples. You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left. Then you bought 5 more apples, so now you had 11 apples. Finally, you ate 1 apple, so you would remain with 10 apples.
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question. Chat History: {chat_history} Follow Up Input: {question} Standalone question:"""