参考资料: https://www.hutool.cn/
参考资料-api文档: https://apidoc.gitee.com/loolly/hutool/overview-summary.html
本文主要用作汇总和自查用。
依赖:
1 2 3 4 5 <dependency > <groupId > cn.hutool</groupId > <artifactId > hutool-all</artifactId > <version > 5.8.16</version > </dependency >
线程工具-ThreadUtil 并发在Java中算是一个比较难理解和容易出问题的部分,而并发的核心在线程。好在从JDK1.5开始Java提供了concurrent包可以很好的帮我们处理大部分并发、异步等问题。
不过,ExecutorService和Executors等众多概念依旧让我们使用这个包变得比较麻烦,如何才能隐藏这些概念?又如何用一个方法解决问题?ThreadUtil便为此而生。
Hutool使用GlobalThreadPool持有一个全局的线程池,默认所有异步方法在这个线程池中执行。
直接在公共线程池中执行线程
获得一个新的线程池
执行异步方法
创建CompletionService,调用其submit方法可以异步执行多个任务,最后调用take方法按照完成的顺序获得其结果。若未完成,则会阻塞。
新建一个CountDownLatch,一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
挂起当前线程,是Thread.sleep的封装,通过返回boolean值表示是否被打断,而不是抛出异常。
ThreadUtil.safeSleep方法是一个保证挂起足够时间的方法,当给定一个挂起时间,使用此方法可以保证挂起的时间大于或等于给定时间,解决Thread.sleep挂起时间不足问题,此方法在Hutool-cron的定时器中使用保证定时任务执行的准确性。
此部分包括两个方法:
getStackTrace 获得堆栈列表getStackTraceElement 获得堆栈项
createThreadLocal 创建本地线程对象interupt 结束线程,调用此方法后,线程将抛出InterruptedException异常waitForDie 等待线程结束. 调用 Thread.join() 并忽略 InterruptedExceptiongetThreads 获取JVM中与当前线程同组的所有线程getMainThread 获取进程的主线程
自定义线程池-ExecutorBuilder 在JDK中,提供了Executors用于创建自定义的线程池对象ExecutorService,但是考虑到线程池中存在众多概念,这些概念通过不同的搭配实现灵活的线程管理策略,单独使用Executors无法满足需求,构建了ExecutorBuilder。
corePoolSize 初始池大小maxPoolSize 最大池大小(允许同时执行的最大线程数)workQueue 队列,用于存在未执行的线程handler 当线程阻塞(block)时的异常处理器,所谓线程阻塞即线程池和等待队列已满,无法处理线程时采取的策略
如果池中任务数 < corePoolSize -> 放入立即执行
如果池中任务数 > corePoolSize -> 放入队列等待
队列满 -> 新建线程立即执行
执行中的线程 > maxPoolSize -> 触发handler(RejectedExecutionHandler)异常
SynchronousQueue 它将任务直接提交给线程而不保持它们。当运行线程小于maxPoolSize时会创建新线程,否则触发异常策略LinkedBlockingQueue 默认无界队列,当运行线程大于corePoolSize时始终放入此队列,此时maxPoolSize无效。当构造LinkedBlockingQueue对象时传入参数,变为有界队列,队列满时,运行线程小于maxPoolSize时会创建新线程,否则触发异常策略ArrayBlockingQueue 有界队列,相对无界队列有利于控制队列大小,队列满时,运行线程小于maxPoolSize时会创建新线程,否则触发异常策略
默认线程池
策略如下:
初始线程数为corePoolSize指定的大小
没有最大线程数限制
默认使用LinkedBlockingQueue,默认队列大小为1024(最大等待数1024)
当运行线程大于corePoolSize放入队列,队列满后抛出异常
1 ExecutorService executor = ExecutorBuilder builder = ExecutorBuilder.create()..build();
单线程线程池
初始线程数为 1
最大线程数为 1
默认使用LinkedBlockingQueue,默认队列大小为1024
同时只允许一个线程工作,剩余放入队列等待,等待数超过1024报错
1 2 3 4 5 ExecutorService executor = ExecutorBuilder.create()1 )1 )0 )
更多选项的线程池
初始5个线程
最大10个线程
有界等待队列,最大等待数是100
1 2 3 4 5 ExecutorService executor = ExecutorBuilder.create()5 )10 )new LinkedBlockingQueue <>(100 ))
特殊策略的线程池
初始5个线程
最大10个线程
它将任务直接提交给线程而不保持它们。当运行线程小于maxPoolSize时会创建新线程,否则触发异常策略
1 2 3 4 5 ExecutorService executor = ExecutorBuilder.create()5 )10 )
高并发测试-ConcurrencyTester 很多时候,我们需要简单模拟N个线程调用某个业务测试其并发状况,于是Hutool提供了一个简单的并发测试类——ConcurrencyTester。
1 2 3 4 5 6 7 8 9 ConcurrencyTester tester = ThreadUtil.concurrencyTest(100 , () -> {long delay = RandomUtil.randomLong(100 , 1000 );"{} test finished, delay: {}" , Thread.currentThread().getName(), delay);
图片工具-ImgUtil 针对awt中图片处理进行封装,这些封装包括:缩放、裁剪、转为黑白、加水印等操作。
提供两种重载方法:其中一个是按照长宽缩放,另一种是按照比例缩放。
1 2 3 4 5 ImgUtil.scale("d:/face.jpg" ), "d:/face_result.jpg" ), 0.5f
1 2 3 4 5 ImgUtil.cut("d:/face.jpg" ), "d:/face_result.jpg" ), new Rectangle (200 , 200 , 100 , 100 )
1 ImgUtil.slice(FileUtil.file("e:/test2.png" ), FileUtil.file("e:/dest/" ), 10 , 10 );
1 ImgUtil.convert(FileUtil.file("e:/test2.png" ), FileUtil.file("e:/test2Convert.jpg" ));
1 ImgUtil.gray(FileUtil.file("d:/logo.png" ), FileUtil.file("d:/result.png" ));
1 2 3 4 5 6 7 8 9 ImgUtil.pressText("e:/pic/face.jpg" ), "e:/pic/test2_result.png" ), "版权所有" , Color.WHITE, new Font ("黑体" , Font.BOLD, 100 ), 0 , 0 , 0.8f
1 2 3 4 5 6 7 8 ImgUtil.pressImage("d:/picTest/1.jpg" ), "d:/picTest/dest.jpg" ), "d:/picTest/1432613.jpg" )), 0 , 0 , 0.1f
1 2 3 BufferedImage image = ImgUtil.rotate(ImageIO.read(FileUtil.file("e:/pic/366466.jpg" )), 180 );"e:/pic/result.png" ));
1 ImgUtil.flip(FileUtil.file("d:/logo.png" ), FileUtil.file("d:/result.png" ));
图片编辑器-Img 针对awt中图片处理进行封装,这些封装包括:缩放、裁剪、转为黑白、加水印等操作。
1 2 3 4 "e:/pic/face.jpg" ))0 , 0 , 200 )"e:/pic/face_radis.png" ));
图片压缩只支持Jpg文件。
1 2 3 Img.from(FileUtil.file("e:/pic/1111.png" ))0.8 )"e:/pic/1111_target.jpg" ));
网络工具-NetUtil 在日常开发中,网络连接这块儿必不可少。日常用到的一些功能,隐藏掉部分IP地址、绝对相对路径的转换等等。
NetUtil 工具中主要的方法包括:
longToIpv4 根据long值获取ip v4地址ipv4ToLong 根据ip地址计算出long型的数据isUsableLocalPort 检测本地端口可用性isValidPort 是否为有效的端口isInnerIP 判定是否为内网IPlocalIpv4s 获得本机的IP地址列表toAbsoluteUrl 相对URL转换为绝对URLhideIpPart 隐藏掉IP地址的最后一部分为 * 代替buildInetSocketAddress 构建InetSocketAddressgetIpByHost 通过域名得到IPisInner 指定IP的long是否在指定范围内
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 String ip= "127.0.0.1" ;long iplong = 2130706433L ;long ip= NetUtil.ipv4ToLong(ip);boolean result= NetUtil.isUsableLocalPort(6379 );boolean result= NetUtil.isValidPort(6379 );String result = NetUtil.hideIpPart(ip);
更多方法请见:
API文档-NetUtil
URL生成器-UrlBuilder 在JDK中,我们可以借助URL对象完成URL的格式化,但是无法完成一些特殊URL的解析和处理,例如编码过的URL、不标准的路径和参数。在旧版本的hutool中,URL的规范完全靠字符串的替换来完成,不但效率低,而且处理过程及其复杂。于是在5.3.1之后,加入了UrlBuilder类,拆分URL的各个部分,分别处理和格式化,完成URL的规范。
按照Uniform Resource Identifier 的标准定义,URL的结构如下:
[scheme:]scheme-specific-part[#fragment]
[scheme:][//authority][path][?query][#fragment]
[scheme:][//host:port][path][?query][#fragment]
按照这个格式,UrlBuilder将URL分成scheme、host、port、path、query、fragment部分,其中path和query较为复杂,又使用UrlPath和UrlQuery分别封装。
相比URL对象,UrlBuilder更加人性化,例如:
1 URL url = new URL ("www.hutool.cn" )
此时会报java.net.MalformedURLException: no protocol的错误,而使用UrlBuilder则会有默认协议:
1 2 String buildUrl = UrlBuilder.create().setHost("www.hutool.cn" ).build();
1 2 3 4 5 6 7 8 String buildUrl = UrlBuilder.create()"https" )"www.hutool.cn" )"/aaa" ).addPath("bbb" )"ie" , "UTF-8" )"wd" , "test" )
当参数中有中文时,自动编码中文,默认UTF-8编码,也可以调用setCharset方法自定义编码。
1 2 3 4 5 6 7 8 9 String buildUrl = UrlBuilder.create()"https" )"www.hutool.cn" )"/s" )"ie" , "UTF-8" )"ie" , "GBK" )"wd" , "测试" )
当有一个URL字符串时,可以使用of方法解析:
1 2 3 4 5 6 UrlBuilder builder = UrlBuilder.ofHttp("www.hutool.cn/aaa/bbb/?a=张三&b=%e6%9d%8e%e5%9b%9b#frag1" , CharsetUtil.CHARSET_UTF_8);"a" ));"b" ));
我们发现这个例子中,原URL中的参数a是没有编码的,b是编码过的,当用户提供此类混合URL时,Hutool可以很好的识别并全部decode,当然,调用build()之后,会全部再encode。
有时候URL中会存在&这种分隔符,谷歌浏览器会将此字符串转换为&使用,Hutool中也同样如此:
1 2 3 4 5 String urlStr = "https://mp.weixin.qq.com/s?__biz=MzI5NjkyNTIxMg==&mid=100000465&idx=1" ;UrlBuilder builder = UrlBuilder.ofHttp(urlStr, CharsetUtil.CHARSET_UTF_8);
UrlBuilder主要应用于http模块,在构建HttpRequest时,用户传入的URL五花八门,为了做大最好的适应性,减少用户对URL的处理,使用UrlBuilder完成URL的规范化。
源码编译工具-CompilerUtil.md JDK提供了JavaCompiler用于动态编译java源码文件,然后通过类加载器加载,这种动态编译可以让Java有动态脚本的特性,Hutool针对此封装了对应工具。
首先我们将编译需要依赖的class文件和jar文件打成一个包:
1 2 3 4 5 6 7 8 final File libFile = ZipUtil.zip(FileUtil.file("lib.jar" ),new String []{"a/A.class" , "a/A$1.class" , "a/A$InnerClass.class" },new InputStream []{"test-compile/a/A.class" ),"test-compile/a/A$1.class" ),"test-compile/a/A$InnerClass.class" )
开始编译:
1 2 3 4 5 6 7 8 final ClassLoader classLoader = CompilerUtil.getCompiler(null )"test-compile/b/B.java" ))"c.C" , FileUtil.readUtf8String("test-compile/c/C.java" ))
加载编译好的类:
1 2 3 final Class<?> clazz = classLoader.loadClass("c.C" );Object obj = ReflectUtil.newInstance(clazz);
设置文件-Setting Setting除了兼容Properties文件格式外,还提供了一些特有功能,这些功能包括:
首先说编码支持,在Properties中,只支ISO8859-1导致在Properties文件中注释和value没法使用中文,(用日本的那个插件在Eclipse里可以读写,放到服务器上读就费劲了),因此Setting中引入自定义编码,可以很好的支持各种编码的配置文件。
再就是变量支持,在Setting中,支持${key}变量,可以将之前定义的键对应的值做为本条值得一部分,这个特性可以减少大量的配置文件冗余。
最后是分组支持。分组的概念我第一次在Linux的rsync的/etc/rsyncd.conf配置文件中有所了解,发现特别实用,具体大家可以自行百度之。当然,在Windows的ini文件中也有分组的概念,Setting将这一概念引入,从而大大增加配置文件的可读性。
1 2 3 4 5 6 7 8 9 10 11 12 # 中括表示一个分组,其下面的所有属性归属于这个分组,在此分组名为demo,也可以没有分组 # 自定义数据源设置文件,这个文件会针对当前分组生效,用于给当前分组配置单独的数据库连接池参数,没有则使用全局的配置 # 数据库驱动名,如果不指定,则会根据url自动判定 # JDBC url,必须 # 用户名,必须 # 密码,必须,如果密码为空,请填写 pass =
配置文件可以放在任意位置,具体Setting类如何寻在在构造方法中提供了多种读取方式,具体稍后介绍。现在说下配置文件的具体格式 Setting配置文件类似于Properties文件,规则如下:
注释用#开头表示,只支持单行注释,空行和无法正常被识别的键值对也会被忽略,可作为注释,但是建议显式指定注释。同时在value之后不允许有注释,会被当作value的一部分。
键值对使用key = value 表示,key和value在读取时会trim掉空格,所以不用担心空格。
分组为中括号括起来的内容(例如配置文件中的[demo]),中括号以下的行都为此分组的内容,无分组相当于空字符分组,即[]。若某个key是name,分组是group,加上分组后的key相当于group.name。
支持变量,默认变量命名为 ${变量名},变量只能识别读入行的变量,例如第6行的变量在第三行无法读取,例如配置文件中的${driver}会被替换为com.mysql.jdbc.Driver,为了性能,Setting创建的时候构造方法会指定是否开启变量替换,默认不开启。
代码具体请见cn.hutool.setting.test.SettingTest
Setting初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 Setting setting = new Setting ("XXX.setting" );new Setting ("config/XXX.setting" );new Setting (FileUtil.touc("/home/looly/XXX.setting" ), CharsetUtil.CHARSET_UTF_8, true );new Setting ("XXX.setting" , SettingDemo.class,CharsetUtil.CHARSET_UTF_8, true );
Setting读取配置参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 "name" );"name" , "group1" );"name" , "默认值" );"name" , "group1" , "默认值" );"name" );"name" , "group1" );"group1" )
重新加载配置和保存配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 true );"name1" , "value" );"/home/looly/XXX.setting" );UserVO userVo = new UserVo ();"\\$\\{(.*?)\\}" );
Properties扩展-Props 对于Properties的广泛使用使我也无能为力,有时候遇到Properties文件又想方便的读写也不容易,于是对Properties做了简单的封装,提供了方便的构造方法(与Setting一致),并提供了与Setting一致的getXXX方法来扩展Properties类,Props类继承自Properties,所以可以兼容Properties类。
Props的使用方法和Properties以及Setting一致(同时支持):
1 2 3 Props props = new Props ("test.properties" );String user = props.getProperty("user" );String driver = props.getStr("driver" );
日志工厂-LogFactory Hutool-log做为一个日志门面,为了兼容各大日志框架,一个用于自动创建日志对象的日志工厂类必不可少。
LogFactory类用于灵活的创建日志对象,通过static方法创建我们需要的日志,主要功能如下:
LogFactory.get 自动识别引入的日志框架,从而创建对应日志框架的门面Log对象(此方法创建一次后,下次再次get会根据传入类名缓存Log对象,对于每个类,Log对象都是单例的),同时自动识别当前类,将当前类做为类名传入日志框架。LogFactory.createLog 与get方法作用类似。但是此方法调用后会每次创建一个新的Log对象。LogFactory.setCurrentLogFactory 自定义当前日志门面的日志实现类。当引入多个日志框架时,我们希望自定义所用的日志框架,调用此方法即可。需要注意的是,此方法为全局方法,在获取Log对象前只调用一次即可。
1 2 private static final Log log = LogFactory.get();
如果你想获得自定义name的Log对象(像普通Log日志实现一样),那么可以使用如下方式获取Log:
1 private static final Log log = LogFactory.get("我是一个自定义日志名" );
1 2 3 4 5 6 7 8 new ApacheCommonsLogFactory ());new JdkLogFactory ());new ConsoleLogFactory ());
LogFactory是一个抽象类,我们可以继承此类,实现createLog方法即可(同时我们可能需要实现Log接口来达到自定义门面的目的),这样我们就可以自定义一个日志门面。最后通过LogFactory.setCurrentLogFactory方法装入这个自定义LogFactory即可实现自定义日志门面。
PS 自定义日志门面的实现可以参考cn.hutool.log.dialect包中的实现内容自定义扩展。 本质上,实现Log接口,做一个日志实现的Wrapper,然后在相应的工厂类中创建此Log实例即可。同时,LogFactory中还可以初始化一些启动配置参数。
静态调用日志-StaticLog 很多时候,我们只是想简简单的使用日志,最好一个方法搞定,我也不想创建Log对象,那么StaticLog或许是你需要的。
1 StaticLog.info("This is static {} log." , "INFO" );
同样StaticLog提供了trace、debug、info、warn、error方法,提供变量占位符支持,使项目中日志的使用简单到没朋友。
StaticLog类中同样提供log方法,可能在极致简洁的状况下,提供非常棒的灵活性(打印日志等级由level参数决定)
假如你只知道StaticLog,不知道LogFactory怎么办?Hutool非常贴心的提供了get方法,此方法与Logfactory中的get方法一样,同样可以获得Log对象。
缓存工具-CacheUtil CacheUtil是缓存创建的快捷工具类。用于快速创建不同的缓存对象。
1 2 3 );
同样其它类型的Cache也可以调用newXXX的方法创建。
先入先出-FIFOCache FIFO(first in first out) 先进先出策略。元素不停的加入缓存直到缓存满为止,当缓存满时,清理过期缓存对象,清理后依旧满则删除先入的缓存(链表首部对象)。
优点:简单快速 缺点:不灵活,不能保证最常用的对象总是被保留
1 2 3 4 5 6 7 8 9 10 11 12 Cache<String,String> fifoCache = CacheUtil.newFIFOCache(3 );"key1" , "value1" , DateUnit.SECOND.getMillis() * 3 );"key2" , "value2" , DateUnit.SECOND.getMillis() * 3 );"key3" , "value3" , DateUnit.SECOND.getMillis() * 3 );"key4" , "value4" , DateUnit.SECOND.getMillis() * 3 );String value1 = fifoCache.get("key1" );
最少使用-LFUCache LFU(least frequently used) 最少使用率策略。根据使用次数来判定对象是否被持续缓存(使用率是通过访问次数计算),当缓存满时清理过期对象,清理后依旧满的情况下清除最少访问(访问计数最小)的对象并将其他对象的访问数减去这个最小访问数,以便新对象进入后可以公平计数。
1 2 3 4 5 6 7 8 9 10 11 12 13 Cache<String, String> lfuCache = CacheUtil.newLFUCache(3 );"key1" , "value1" , DateUnit.SECOND.getMillis() * 3 );"key1" );"key2" , "value2" , DateUnit.SECOND.getMillis() * 3 );"key3" , "value3" , DateUnit.SECOND.getMillis() * 3 );"key4" , "value4" , DateUnit.SECOND.getMillis() * 3 );String value2 = lfuCache.get("key2" );String value3 = lfuCache.get("key3" );
最近最久未使用-LRUCache LRU (least recently used)最近最久未使用缓存。根据使用时间来判定对象是否被持续缓存,当对象被访问时放入缓存,当缓存满了,最久未被使用的对象将被移除。此缓存基于LinkedHashMap,因此当被缓存的对象每被访问一次,这个对象的key就到链表头部。这个算法简单并且非常快,他比FIFO有一个显著优势是经常使用的对象不太可能被移除缓存。缺点是当缓存满时,不能被很快的访问。
1 2 3 4 5 6 7 8 9 10 11 Cache<String, String> lruCache = CacheUtil.newLRUCache(3 );"key1" , "value1" , DateUnit.SECOND.getMillis() * 3 );"key2" , "value2" , DateUnit.SECOND.getMillis() * 3 );"key3" , "value3" , DateUnit.SECOND.getMillis() * 3 );"key1" );"key4" , "value4" , DateUnit.SECOND.getMillis() * 3 );String value2 = lruCache.get("key" );
超时-TimedCache 定时缓存,对被缓存的对象定义一个过期时间,当对象超过过期时间会被清理。此缓存没有容量限制,对象只有在过期后才会被移除。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 4 );"key1" , "value1" , 1 );"key2" , "value2" , DateUnit.SECOND.getMillis() * 5 );"key3" , "value3" );5 );5 );String value1 = timedCache.get("key1" );String value2 = timedCache.get("key2" );String value3 = timedCache.get("key3" );
如果用户在超时前调用了get(key)方法,会重头计算起始时间。举个例子,用户设置key1的超时时间5s,用户在4s的时候调用了get("key1"),此时超时时间重新计算,再过4s调用get("key1")方法值依旧存在。如果想避开这个机制,请调用get("key1", false)方法。
说明 如果启动了定时器,那会定时清理缓存中的过期值,但是如果不起动,那只有在get这个值得时候才检查过期并清理。不起动定时器带来的问题是:有些值如果长时间不访问,会占用缓存的空间。
弱引用-WeakCache 弱引用缓存。对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。丢弃某个键时,其条目从映射中有效地移除。该类使用了WeakHashMap做为其实现,缓存的清理依赖于JVM的垃圾回收。
与TimedCache使用方法一致:
1 WeakCache<String, String> weakCache = CacheUtil.newWeakCache(DateUnit.SECOND.getMillis() * 3 );
WeakCache也可以像TimedCache一样设置定时清理时间,同时具备垃圾回收清理。
文件缓存-FileCache FileCache主要是将小文件以byte[]的形式缓存到内存中,减少文件的访问,以解决频繁读取文件引起的性能问题。
LFUFileCache
LRUFileCache
1 2 3 4 5 LFUFileCache cache = new LFUFileCache (1000 , 500 , 2000 );byte [] bytes = cache.getFileBytes("d:/a.jpg" );
LRUFileCache的使用与LFUFileCache一致,不再举例。
JSON工具-JSONUtil JSONUtil是针对JSONObject和JSONArray的静态快捷方法集合,在之前的章节我们已经介绍了一些工具方法,在本章节我们将做一些补充。
JSONUtil.toJsonStr可以将任意对象(Bean、Map、集合等)直接转换为JSON字符串。 如果对象是有序的Map等对象,则转换后的JSON字符串也是有序的。
1 2 3 4 5 6 7 8 9 SortedMap<Object, Object> sortedMap = new TreeMap <Object, Object>() {private static final long serialVersionUID = 1L ;"attributes" , "a" );"b" , "b" );"c" , "c" );
结果:
1 { "attributes" : "a" , "b" : "b" , "c" : "c" }
如果我们想获得格式化后的JSON,则:
1 JSONUtil.toJsonPrettyStr(sortedMap);
结果:
1 2 3 4 5 { "attributes" : "a" , "b" : "b" , "c" : "c" }
1 2 3 String html = "{\"name\":\"Something must have been changed since you leave\"}" ;JSONObject jsonObject = JSONUtil.parseObj(html);"name" );
1 2 3 4 5 String s = "<sfzh>123</sfzh><sfz>456</sfz><name>aa</name><gender>1</gender>" ;JSONObject json = JSONUtil.parseFromXml(s);"sfzh" );"name" );
1 2 3 4 5 6 final JSONObject put = JSONUtil.createObj()"aaa" , "你好" )"键2" , "test" );final String s = JSONUtil.toXmlStr(put);
我们先定义两个较为复杂的Bean(包含泛型)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Data public class ADT {private List<String> BookingCode;@Data public class Price {private List<List<ADT>> ADT;String json = "{\"ADT\":[[{\"BookingCode\":[\"N\",\"N\"]}]]}" ;Price price = JSONUtil.toBean(json, Price.class);0 ).get(0 ).getBookingCode().get(0 );
这类方法主要是从JSON文件中读取JSON对象的快捷方法。包括:
readJSON
readJSONObject
readJSONArray
除了上面中常用的一些方法,JSONUtil还提供了一些JSON辅助方法:
quote 对所有双引号做转义处理(使用双反斜杠做转义)
wrap 包装对象,可以将普通任意对象转为JSON对象
formatJsonStr 格式化JSON字符串,此方法并不严格检查JSON的格式正确与否
JSON对象-JSONObject JSONObject代表一个JSON中的键值对象,这个对象以大括号包围,每个键值对使用,隔开,键与值使用:隔开,一个JSONObject类似于这样:
1 2 3 4 { "key1" : "value1" , "key2" : "value2" }
此处键部分可以省略双引号,值为字符串时不能省略,为数字或波尔值时不加双引号。
1 2 3 4 JSONObject json1 = JSONUtil.createObj()"a" , "value1" )"b" , "value2" )"c" , "value3" );
JSONUtil.createObj()是快捷新建JSONObject的工具方法,同样我们可以直接new:
1 2 JSONObject json1 = new JSONObject ();
JSON字符串解析
1 2 3 4 5 String jsonStr = "{\"b\":\"value2\",\"c\":\"value3\",\"a\":\"value1\"}" ;JSONObject jsonObject = JSONUtil.parseObj(jsonStr);JSONObject jsonObject2 = new JSONObject (jsonStr);
//JSON对象转字符串(一行) jsonObject.toString();
// 也可以美化一下,即显示出带缩进的JSON: jsonObject.toStringPretty();
1 2 3 4 5 6 7 8 9 10 11 12 2. JavaBean解析public class UserA private String name;private String a;private Date date;private List<Seq> sqs;
解析为JSON:
1 2 3 4 5 6 7 8 UserA userA = new UserA ();"nameTest" );new Date ());new Seq (null ), new Seq ("seq2" )));JSONObject json = JSONUtil.parseObj(userA, false );
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 { "date" : 1585618492295 , "a" : null , "sqs" : [ { "seq" : null } , { "seq" : "seq2" } ] , "name" : "nameTest" }
可以看到,输出的字段顺序和Bean的字段顺序不一致,如果想保持一致,可以:
1 2 JSONObject json = JSONUtil.parseObj(userA, false , true );
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 { "name" : "nameTest" , "a" : null , "date" : 1585618648523 , "sqs" : [ { "seq" : null } , { "seq" : "seq2" } ] }
默认的,Hutool将日期输出为时间戳,如果需要自定义日期格式,可以调用:
1 json.setDateFormat("yyyy-MM-dd HH:mm:ss" );
得到结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 { "name" : "nameTest" , "a" : null , "date" : "2020-03-31 09:41:29" , "sqs" : [ { "seq" : null } , { "seq" : "seq2" } ] }
JSON数组-JSONArray 在JSON中,JSONArray代表一个数组,使用中括号包围,每个元素使用逗号隔开。一个JSONArray类似于这样:
1 [ "value1" , "value2" , "value3" ]
1 2 3 4 5 6 7 8 9 10 11 JSONArray array = JSONUtil.createArray();JSONArray array = new JSONArray ();"value1" );"value2" );"value3" );
先定义bean:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Data public class KeyBean {private String akey;private String bkey;KeyBean b1 = new KeyBean ();"aValue1" );"bValue1" );KeyBean b2 = new KeyBean ();"aValue2" );"bValue2" );JSONArray jsonArray = JSONUtil.parseArray(list);0 ).getStr("akey" );
1 2 String jsonStr = "[\"value1\", \"value2\", \"value3\"]" ;JSONArray array = JSONUtil.parseArray(jsonStr);
先定义一个Bean
1 2 3 4 5 6 7 8 9 10 11 12 @Data static class User {private Integer id;private String name;String jsonArr = "[{\"id\":111,\"name\":\"test1\"},{\"id\":112,\"name\":\"test2\"}]" ;JSONArray array = JSONUtil.parseArray(jsonArr);0 ).getId();
Dict是Hutool定义的特殊Map,提供了以字符串为key的Map功能,并提供getXXX方法,转换也类似:
1 2 3 4 5 6 7 String jsonArr = "[{\"id\":111,\"name\":\"test1\"},{\"id\":112,\"name\":\"test2\"}]" ;JSONArray array = JSONUtil.parseArray(jsonArr);0 ).getInt("id" );
1 2 3 4 String jsonArr = "[{\"id\":111,\"name\":\"test1\"},{\"id\":112,\"name\":\"test2\"}]" ;JSONArray array = JSONUtil.parseArray(jsonArr);new User [0 ]);
如果JSON的层级特别深,那么获取某个值就变得非常麻烦,代码也很臃肿,Hutool提供了getByPath方法可以通过表达式获取JSON中的值。
1 2 3 4 5 String jsonStr = "[{\"id\": \"1\",\"name\": \"a\"},{\"id\": \"2\",\"name\": \"b\"}]" ;final JSONArray jsonArray = JSONUtil.parseArray(jsonStr);"[1].name" );
加密解密工具-SecureUtil SecureUtil主要针对常用加密算法构建快捷方式,还有提供一些密钥生成的快捷工具方法。
SecureUtil.aesSecureUtil.des
SecureUtil.md5SecureUtil.sha1SecureUtil.hmacSecureUtil.hmacMd5SecureUtil.hmacSha1
SecureUtil.rsaSecureUtil.dsa
SecureUtil.simpleUUID 方法提供无“-”的UUID
SecureUtil.generateKey 针对对称加密生成密钥SecureUtil.generateKeyPair 生成密钥对(用于非对称加密)SecureUtil.generateSignature 生成签名(用于非对称加密)
其它方法为针对特定加密方法的一些密钥生成和签名相关方法,详细请参阅API文档。
对称加密-SymmetricCrypto 对称加密(也叫私钥加密)指加密和解密使用相同密钥的加密算法。有时又叫传统密码算法,就是加密密钥能够从解密密钥中推算出来,同时解密密钥也可以从加密密钥中推算出来。而在大多数的对称算法中,加密密钥和解密密钥是相同的,所以也称这种加密算法为秘密密钥算法或单密钥算法。它要求发送方和接收方在安全通信之前,商定一个密钥。对称算法的安全性依赖于密钥,泄漏密钥就意味着任何人都可以对他们发送或接收的消息解密,所以密钥的保密性对通信的安全性至关重要。
对于对称加密,封装了JDK的,具体介绍见:https://docs.oracle.com/javase/7/docs/technotes/guides/security/StandardNames.html#KeyGenerator:
AES (默认AES/ECB/PKCS5Padding)
ARCFOUR
Blowfish
DES (默认DES/ECB/PKCS5Padding)
DESede
RC2
PBEWithMD5AndDES
PBEWithSHA1AndDESede
PBEWithSHA1AndRC2_40
以AES算法为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 String content = "test中文" ;byte [] key = SecureUtil.generateKey(SymmetricAlgorithm.AES.getValue()).getEncoded();SymmetricCrypto aes = new SymmetricCrypto (SymmetricAlgorithm.AES, key);byte [] encrypt = aes.encrypt(content);byte [] decrypt = aes.decrypt(encrypt);String encryptHex = aes.encryptHex(content);String decryptStr = aes.decryptStr(encryptHex, CharsetUtil.CHARSET_UTF_8);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 String content = "test中文" ;byte [] key = SecureUtil.generateKey(SymmetricAlgorithm.DESede.getValue()).getEncoded();SymmetricCrypto des = new SymmetricCrypto (SymmetricAlgorithm.DESede, key);byte [] encrypt = des.encrypt(content);byte [] decrypt = des.decrypt(encrypt);String encryptHex = des.encryptHex(content);String decryptStr = des.decryptStr(encryptHex);
AES全称高级加密标准(英语:Advanced Encryption Standard,缩写:AES),在密码学中又称Rijndael加密法。
对于Java中AES的默认模式是:AES/ECB/PKCS5Padding,如果使用CryptoJS,请调整为:padding: CryptoJS.pad.Pkcs7
快速构建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 String content = "test中文" ;byte [] key = SecureUtil.generateKey(SymmetricAlgorithm.AES.getValue()).getEncoded();AES aes = SecureUtil.aes(key);byte [] encrypt = aes.encrypt(content);byte [] decrypt = aes.decrypt(encrypt);String encryptHex = aes.encryptHex(content);String decryptStr = aes.decryptStr(encryptHex, CharsetUtil.CHARSET_UTF_8);
自定义内置模式和偏移
1 AES aes = new AES (Mode.CTS, Padding.PKCS5Padding, "0CoJUm6Qyw8W8jud" .getBytes(), "0102030405060708" .getBytes());
PKCS7Padding模式
由于IOS等移动端对AES加密有要求,必须为PKCS7Padding模式,但JDK本身并不提供这种模式,因此想要支持必须做一些工作。
首先引入bc库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <dependency > <groupId > org.bouncycastle</groupId > <artifactId > bcprov-jdk15to18</artifactId > <version > 1.68</version > </dependency >
DES全称为Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法,Java中默认实现为:DES/CBC/PKCS5Padding
DES使用方法与AES一致,构建方法为:
快速构建
1 2 byte [] key = SecureUtil.generateKey(SymmetricAlgorithm.DES.getValue()).getEncoded();DES des = SecureUtil.des(key);
自定义模式和偏移
1 DES des = new DES (Mode.CTS, Padding.PKCS5Padding, "0CoJUm6Qyw8W8jud" .getBytes(), "01020304" .getBytes());
在4.2.1之后,Hutool借助Bouncy Castle库可以支持国密算法,以SM4为例:
我们首先需要引入Bouncy Castle库:
1 2 3 4 5 <dependency > <groupId > org.bouncycastle</groupId > <artifactId > bcpkix-jdk15on</artifactId > <version > 1.60</version > </dependency >
然后可以调用SM4算法,调用方法与其它算法一致:
1 2 3 4 5 String content = "test中文" ;SymmetricCrypto sm4 = new SymmetricCrypto ("SM4" );String encryptHex = sm4.encryptHex(content);String decryptStr = sm4.decryptStr(encryptHex, CharsetUtil.CHARSET_UTF_8);
同样我们可以指定加密模式和偏移:
1 2 3 4 5 String content = "test中文" ;SymmetricCrypto sm4 = new SymmetricCrypto ("SM4/ECB/PKCS5Padding" );String encryptHex = sm4.encryptHex(content);String decryptStr = sm4.decryptStr(encryptHex, CharsetUtil.CHARSET_UTF_8);
非对称加密-AsymmetricCrypto 对于非对称加密,最常用的就是RSA和DSA,在Hutool中使用AsymmetricCrypto对象来负责加密解密。
非对称加密有公钥和私钥两个概念,私钥自己拥有,不能给别人,公钥公开。根据应用的不同,我们可以选择使用不同的密钥加密:
签名:使用私钥加密,公钥解密。用于让所有公钥所有者验证私钥所有者的身份并且用来防止私钥所有者发布的内容被篡改,但是不用来保证内容不被他人获得。
加密:用公钥加密,私钥解密。用于向公钥所有者发布信息,这个信息可能被他人篡改,但是无法被他人获得。
Hutool封装了JDK的,详细见https://docs.oracle.com/javase/7/docs/technotes/guides/security/StandardNames.html#KeyPairGenerator:
RSA
RSA_ECB_PKCS1(RSA/ECB/PKCS1Padding)
RSA_None(RSA/None/NoPadding)
ECIES(需要Bouncy Castle库)
在非对称加密中,我们可以通过AsymmetricCrypto(AsymmetricAlgorithm algorithm)构造方法,通过传入不同的算法枚举,获得其加密解密器。
当然,为了方便,我们针对最常用的RSA算法构建了单独的对象:RSA。
我们以RSA为例,介绍使用RSA加密和解密 在构建RSA对象时,可以传入公钥或私钥,当使用无参构造方法时,Hutool将自动生成随机的公钥私钥密钥对:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 RSA rsa = new RSA ();byte [] encrypt = rsa.encrypt(StrUtil.bytes("我是一段测试aaaa" , CharsetUtil.CHARSET_UTF_8), KeyType.PublicKey);byte [] decrypt = rsa.decrypt(encrypt, KeyType.PrivateKey);byte [] encrypt2 = rsa.encrypt(StrUtil.bytes("我是一段测试aaaa" , CharsetUtil.CHARSET_UTF_8), KeyType.PrivateKey);byte [] decrypt2 = rsa.decrypt(encrypt2, KeyType.PublicKey);
对于加密和解密可以完全分开,对于RSA对象,如果只使用公钥或私钥,另一个参数可以为null
有时候我们想自助生成密钥对可以:
1 2 3 KeyPair pair = SecureUtil.generateKeyPair("RSA" );
自助生成的密钥对是byte[]形式,我们可以使用Base64.encode方法转为Base64,便于存储为文本。
当然,如果使用RSA对象,也可以使用encryptStr和decryptStr加密解密为字符串。
已知私钥和密文,如何解密密文?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 String PRIVATE_KEY = "MIICdQIBADANBgkqhkiG9w0BAQEFAASCAl8wggJbAgEAAoGBAIL7pbQ+5KKGYRhw7jE31hmA" "f8Q60ybd+xZuRmuO5kOFBRqXGxKTQ9TfQI+aMW+0lw/kibKzaD/EKV91107xE384qOy6IcuBfaR5lv39OcoqNZ" "5l+Dah5ABGnVkBP9fKOFhPgghBknTRo0/rZFGI6Q1UHXb+4atP++LNFlDymJcPAgMBAAECgYBammGb1alndta" "xBmTtLLdveoBmp14p04D8mhkiC33iFKBcLUvvxGg2Vpuc+cbagyu/NZG+R/WDrlgEDUp6861M5BeFN0L9O4hz" "GAEn8xyTE96f8sh4VlRmBOvVdwZqRO+ilkOM96+KL88A9RKdp8V2tna7TM6oI3LHDyf/JBoXaQJBAMcVN7fKlYP" "Skzfh/yZzW2fmC0ZNg/qaW8Oa/wfDxlWjgnS0p/EKWZ8BxjR/d199L3i/KMaGdfpaWbYZLvYENqUCQQCobjsuCW" "nlZhcWajjzpsSuy8/bICVEpUax1fUZ58Mq69CQXfaZemD9Ar4omzuEAAs2/uee3kt3AvCBaeq05NyjAkBme8SwB0iK" "kLcaeGuJlq7CQIkjSrobIqUEf+CzVZPe+AorG+isS+Cw2w/2bHu+G0p5xSYvdH59P0+ZT0N+f9LFAkA6v3Ae56OrI" "wfMhrJksfeKbIaMjNLS9b8JynIaXg9iCiyOHmgkMl5gAbPoH/ULXqSKwzBw5mJ2GW1gBlyaSfV3AkA/RJC+adIjsRGg" "JOkiRjSmPpGv3FOhl9fsBPjupZBEIuoMWOC8GXK/73DHxwmfNmN7C9+sIi4RBcjEeQ5F5FHZ" ;RSA rsa = new RSA (PRIVATE_KEY, null );String a = "2707F9FD4288CEF302C972058712F24A5F3EC62C5A14AD2FC59DAB93503AA0FA17113A020EE4EA35EB53F" "75F36564BA1DABAA20F3B90FD39315C30E68FE8A1803B36C29029B23EB612C06ACF3A34BE815074F5EB5AA3A" "C0C8832EC42DA725B4E1C38EF4EA1B85904F8B10B2D62EA782B813229F9090E6F7394E42E6F44494BB8" ;byte [] aByte = HexUtil.decodeHex(a);byte [] decrypt = rsa.decrypt(aByte, KeyType.PrivateKey);
ECIES全称集成加密方案(elliptic curve integrate encrypt scheme)
Hutool借助Bouncy Castle库可以支持ECIES算法:
我们首先需要引入Bouncy Castle库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <dependency > <groupId > org.bouncycastle</groupId > <artifactId > bcprov-jdk15to18</artifactId > <version > 1.66</version > </dependency >
摘要加密-Digester 摘要算法是一种能产生特殊输出格式的算法,这种算法的特点是:无论用户输入什么长度的原始数据,经过计算后输出的密文都是固定长度的,这种算法的原理是根据一定的运算规则对原数据进行某种形式的提取,这种提取就是摘要,被摘要的数据内容与原数据有密切联系,只要原数据稍有改变,输出的“摘要”便完全不同,因此,基于这种原理的算法便能对数据完整性提供较为健全的保障。
但是,由于输出的密文是提取原数据经过处理的定长值,所以它已经不能还原为原数据,即消息摘要算法是不可逆的,理论上无法通过反向运算取得原数据内容,因此它通常只能被用来做数据完整性验证。
在不引入第三方库的情况下,JDK支持有限的摘要算法:
详细见:https://docs.oracle.com/javase/7/docs/technotes/guides/security/StandardNames.html#MessageDigest
MD2
MD5
SHA-1
SHA-256
SHA-384
SHA-512
以MD5为例:
1 2 3 4 Digester md5 = new Digester (DigestAlgorithm.MD5);String digestHex = md5.digestHex(testStr);
当然,做为最为常用的方法,MD5等方法被封装为工具方法在DigestUtil中,以上代码可以进一步简化为:
1 2 String md5Hex1 = DigestUtil.md5Hex(testStr);
在4.2.1之后,Hutool借助Bouncy Castle库可以支持国密算法,以SM3为例:
我们首先需要引入Bouncy Castle库:
1 2 3 4 5 <dependency > <groupId > org.bouncycastle</groupId > <artifactId > bcprov-jdk15to18</artifactId > <version > 1.66</version > </dependency >
然后可以调用SM3算法,调用方法与其它摘要算法一致:
1 2 3 4 Digester digester = DigestUtil.digester("sm3" );String digestHex = digester.digestHex("aaaaa" );
Java标准库的java.security包提供了一种标准机制,允许第三方提供商无缝接入。当引入Bouncy Castle库的jar后,Hutool会自动检测并接入。具体方法可见SecureUtil.createMessageDigest。
消息认证码算法-HMac HMAC,全称为“Hash Message Authentication Code”,中文名“散列消息鉴别码”,主要是利用哈希算法,以一个密钥和一个消息为输入,生成一个消息摘要作为输出。一般的,消息鉴别码用于验证传输于两个共 同享有一个密钥的单位之间的消息。HMAC 可以与任何迭代散列函数捆绑使用。MD5 和 SHA-1 就是这种散列函数。HMAC 还可以使用一个用于计算和确认消息鉴别值的密钥。
在不引入第三方库的情况下,JDK支持有限的摘要算法:
HmacMD5
HmacSHA1
HmacSHA256
HmacSHA384
HmacSHA512
以HmacMD5为例:
1 2 3 4 5 6 7 8 String testStr = "test中文" ;byte [] key = "password" .getBytes();HMac mac = new HMac (HmacAlgorithm.HmacMD5, key);String macHex1 = mac.digestHex(testStr);
与摘要算法类似,通过加入Bouncy Castle库可以调用更多算法,使用也类似:
1 HMac mac = new HMac ("XXXX" , key);
签名和验证-Sign Hutool针对java.security.Signature做了简化包装,包装类为:Sign,用于生成签名和签名验证。
对于签名算法,Hutool封装了JDK的Signature,具体介绍见:https://docs.oracle.com/javase/7/docs/technotes/guides/security/StandardNames.html#Signature:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
1 2 3 4 5 6 byte [] data = "我是一段测试字符串" .getBytes();Sign sign = SecureUtil.sign(SignAlgorithm.MD5withRSA);byte [] signed = sign.sign(data);boolean verify = sign.verify(data, signed);
国密算法工具-SmUtil Hutool针对Bouncy Castle做了简化包装,用于实现国密算法中的SM2、SM3、SM4。
国密算法工具封装包括:
非对称加密和签名:SM2
摘要签名算法:SM3
对称加密:SM4
国密算法需要引入Bouncy Castle库的依赖。
1 2 3 4 5 <dependency > <groupId > org.bouncycastle</groupId > <artifactId > bcprov-jdk15to18</artifactId > <version > 1.69</version > </dependency >
说明 bcprov-jdk15to18的版本请前往Maven中央库搜索,查找对应JDK的最新版本。
使用随机生成的密钥对加密或解密
1 2 3 4 5 6 String text = "我是一段测试aaaa" ;SM2 sm2 = SmUtil.sm2();String encryptStr = sm2.encryptBcd(text, KeyType.PublicKey);String decryptStr = StrUtil.utf8Str(sm2.decryptFromBcd(encryptStr, KeyType.PrivateKey));
使用自定义密钥对加密或解密
1 2 3 4 5 6 7 8 9 10 String text = "我是一段测试aaaa" ;KeyPair pair = SecureUtil.generateKeyPair("SM2" );byte [] privateKey = pair.getPrivate().getEncoded();byte [] publicKey = pair.getPublic().getEncoded();SM2 sm2 = SmUtil.sm2(privateKey, publicKey);String encryptStr = sm2.encryptBcd(text, KeyType.PublicKey);String decryptStr = StrUtil.utf8Str(sm2.decryptFromBcd(encryptStr, KeyType.PrivateKey));
SM2签名和验签
1 2 3 4 5 6 String content = "我是Hanley." ;final SM2 sm2 = SmUtil.sm2();String sign = sm2.signHex(HexUtil.encodeHexStr(content));boolean verify = sm2.verifyHex(HexUtil.encodeHexStr(content), sign);
当然,也可以自定义密钥对:
1 2 3 4 5 6 7 8 String content = "我是Hanley." ;KeyPair pair = SecureUtil.generateKeyPair("SM2" );final SM2 sm2 = new SM2 (pair.getPrivate(), pair.getPublic());byte [] sign = sm2.sign(content.getBytes());boolean verify = sm2.verify(content.getBytes(), sign);
使用SM2曲线点构建SM2
使用曲线点构建中的点生成和验证见:https://i.goto327.top/CryptTools/SM2.aspx?tdsourcetag=s_pctim_aiomsg
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 String privateKeyHex = "FAB8BBE670FAE338C9E9382B9FB6485225C11A3ECB84C938F10F20A93B6215F0" ;String x = "9EF573019D9A03B16B0BE44FC8A5B4E8E098F56034C97B312282DD0B4810AFC3" ;String y = "CC759673ED0FC9B9DC7E6FA38F0E2B121E02654BF37EA6B63FAF2A0D6013EADF" ;String data = "434477813974bf58f94bcf760833c2b40f77a5fc360485b0b9ed1bd9682edb45" ;String id = "31323334353637383132333435363738" ;final SM2 sm2 = new SM2 (privateKeyHex, x, y);final String sign = sm2.signHex(data, id);boolean verify = sm2.verifyHex(data, sign)
使用私钥D值签名
1 2 3 4 5 6 7 8 9 byte [] dataBytes = "我是一段测试aaaa" .getBytes();String privateKeyHex = "1ebf8b341c695ee456fd1a41b82645724bc25d79935437d30e7e4b0a554baa5e" ;final SM2 sm2 = new SM2 (privateKeyHex, null , null );byte [] sign = sm2.sign(dataBytes, null );
使用公钥Q值验证签名
1 2 3 4 5 6 7 8 9 10 11 12 String publicKeyHex = "04db9629dd33ba568e9507add5df6587a0998361a03d3321948b448c653c2c1b7056434884ab6f3d1c529501f166a336e86f045cea10dffe58aa82ea13d725363" ;byte [] dataBytes = "我是一段测试aaaa" .getBytes();String signHex = "2881346e038d2ed706ccdd025f2b1dafa7377d5cf090134b98756fafe084dddbcdba0ab00b5348ed48025195af3f1dda29e819bb66aa9d4d088050ff148482a" ;final SM2 sm2 = new SM2 (null , ECKeyUtil.toSm2PublicParams(publicKeyHex));boolean verify = sm2.verify(dataBytes, HexUtil.decodeHex(signHex));
其他格式的密钥
在SM2算法中,密钥的格式分以下几种:
私钥:
D值 一般为硬件直接生成的值
PKCS#8 JDK默认生成的私钥格式
PKCS#1 一般为OpenSSL生成的的EC密钥格式
公钥:
Q值 一般为硬件直接生成的值
X.509 JDK默认生成的公钥格式
PKCS#1 一般为OpenSSL生成的的EC密钥格式
在新版本的Hutool中,SM2的构造方法对这几类的密钥都做了兼容,即用户无需关注密钥类型:
1 2 String digestHex = SmUtil.sm3("aaaaa" );
1 2 3 4 5 String content = "test中文" ;SymmetricCrypto sm4 = SmUtil.sm4();String encryptHex = sm4.encryptHex(content);String decryptStr = sm4.decryptStr(encryptHex, CharsetUtil.CHARSET_UTF_8);
DFA查找 1 2 3 4 5 6 WordTree tree = new WordTree ();"大" );"大土豆" );"土豆" );"刚出锅" );"出锅" );
1 2 String text = "我有一颗大土豆,刚出锅的" ;
情况一:标准匹配,匹配到最短关键词,并跳过已经匹配的关键词
1 2 3 4 1 , false , false );"[大, 土豆, 刚出锅]" );
情况二:匹配到最短关键词,不跳过已经匹配的关键词
1 2 3 4 1 , true , false );"[大, 土豆, 刚出锅, 出锅]" );
情况三:匹配到最长关键词,跳过已经匹配的关键词
1 2 3 4 1 , false , true );"[大, 大土豆, 刚出锅]" );
情况四:匹配到最长关键词,不跳过已经匹配的关键词(最全关键词)
1 2 3 4 1 , true , true );"[大, 大土豆, 土豆, 刚出锅, 出锅]" );
除了matchAll方法,WordTree还提供了match和isMatch两个方法,这两个方法只会查找第一个匹配的结果,这样一旦找到第一个关键字,就会停止继续匹配,大大提高了匹配效率。
有时候,正文中的关键字常常包含特殊字符,比如:”〓关键☆字”,针对这种情况,Hutool提供了StopChar类,专门针对特殊字符做跳过处理,这个过程是在match方法或matchAll方法执行的时候自动去掉特殊字符。
数据库简单操作-Db 数据库操作不外乎四门功课:增删改查,在Java的世界中,由于JDBC的存在,这项工作变得简单易用,但是也并没有做到使用上的简化。于是出现了JPA(Hibernate)、MyBatis、Jfinal、BeetlSQL等解决框架,或解决多数据库差异问题,或解决SQL维护问题。而Hutool对JDBC的封装,多数为在小型项目中对数据处理的简化,尤其只涉及单表操作时。OK,废话不多,来个Demo感受下。
我们以MySQL为例
Maven项目中在src/main/resources目录下添加db.setting文件(非Maven项目添加到ClassPath中即可):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ## db.setting文件root pass = 123456 SQL showSql = true SQL formatSql = false true error sqlLevel = debug
1 2 3 4 5 6 <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > ${mysql.version}</version > </dependency >
注意 此处不定义MySQL版本,请参考官方文档使用匹配的驱动包版本。
1 2 3 4 5 Db.use().insert("user" )"name" , "unitTestUser" )"age" , 66 )
插入数据并返回自增主键:
1 2 3 4 5 Db.use().insertForGeneratedKey("user" )"name" , "unitTestUser" )"age" , 66 )
1 2 3 Db.use().del("user" ).set("name" , "unitTestUser" )
注意 考虑安全性,使用del方法时不允许使用空的where条件,防止全表删除,如有相关操作需要,请调用execute方法执行SQL实现。
1 2 3 4 Db.use().update("age" , 88 ), "user" ).set("name" , "unitTestUser" )
注意 条件语句除了可以用=精确匹配外,也可以范围条件匹配,例如表示 age < 12 可以这样构造Entity:Entity.create("user").set("age", "< 12"),但是通过Entity方式传入条件暂时不支持同字段多条件的情况。
查询全部字段
1 2 "user" );
条件查询
1 Db.use().findAll(Entity.create("user" ).set("name" , "unitTestUser" ));
模糊查询
1 Db.use().findLike("user" , "name" , "Test" , LikeType.Contains);
或者:
1 List<Entity> find = Db.use().find(Entity.create("user" ).set("name" , "like 王%" ));
分页查询
1 2 "user" ).set("age" , "> 30" ), new Page (10 , 20 ));
执行SQL语句
1 2 3 4 5 6 7 8 9 10 "select * from user where age < ?" , 3 );"select * from user where name like ?" , "王%" );"insert into user values (?, ?, ?)" , "张三" , 17 , 1 );"delete from user where name = ?" , "张三" );"update user set age = ? where name = ?" , 3 , "张三" );
事务
1 2 3 4 5 6 7 Db.use().tx(new TxFunc () {@Override public void call (Db db) throws SQLException {"user" ).set("name" , "unitTestUser" ));"age" , 79 ), Entity.create("user" ).set("name" , "unitTestUser" ));
JDK8中可以用lambda表达式(since:5.x):
1 2 3 4 Db.use().tx(db -> {"user" ).set("name" , "unitTestUser2" ));"age" , 79 ), Entity.create("user" ).set("name" , "unitTestUser2" ));
支持命名占位符的SQL执行
有时候使用”?”占位符比较繁琐,且在复杂SQL中很容易出错,Hutool支持使用命名占位符来执行SQL。
1 2 Map<String, Object> paramMap = MapUtil.builder("name1" , (Object)"张三" ).put("age" , 12 ).put("subName" , "小豆豆" ).build();"select * from table where id=@id and name = @name1 and nickName = @subName" , paramMap);
在Hutool中,占位符支持以下几种形式:
IN查询
我们在执行类似于select * from user where id in 1,2,3这类SQL的时候,Hutool封装如下:
1 2 3 List<Entity> results = db.findAll("user" )"id" , "in 1,2,3" ));
当然你也可以直接:
1 2 3 List<Entity> results = db.findAll("user" )"id" , new long []{1 , 2 , 3 }));
支持事务的CRUD-Session Session非常类似于SqlRunner,差别是Session对象中只有一个Connection,所有操作也是用这个Connection,便于事务操作,而SqlRunner每执行一个方法都要从DataSource中去要Connection。样例如下:
与SqlRunner类似,Session也可以通过调用create
1 2 3 4 5 Session session = Session.create();Session session = Session.create(DSFactory.get("test" ));
session.beginTransaction()表示事务开始,调用后每次执行语句将不被提交,只有调用commit方法后才会合并提交,提交或者回滚后会恢复默认的自动提交模式。
新增
1 2 3 4 5 6 7 8 9 Entity entity = Entity.create(TABLE_NAME).set("字段1" , "值" ).set("字段2" , 2 );try {catch (SQLException e) {
更新
1 2 3 4 5 6 7 8 9 10 Entity entity = Entity.create(TABLE_NAME).set("字段1" , "值" ).set("字段2" , 2 );Entity where = Entity.create(TABLE_NAME).set("条件1" , "条件值" );try {catch (SQLException e) {
删除
1 2 3 4 5 6 7 8 9 Entity where = Entity.create(TABLE_NAME).set("条件1" , "条件值" );try {catch (SQLException e) {
数据源配置db.setting样例 DsFactory默认读取的配置文件是config/db.setting或db.setting,db.setting的配置包括两部分:基本连接信息和连接池配置信息。
基本连接信息所有连接池都支持,连接池配置信息根据不同的连接池,连接池配置是根据连接池相应的配置项移植而来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 url = jdbc:mysql://<host>:<port>/<database_name>username = 用户名password = 密码driver = com.mysql.jdbc.DrivershowSql = true formatSql = false showParams = true sqlLevel = debug
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 autoCommit = true connectionTimeout = 30000 idleTimeout = 600000 maxLifetime = 1800000 connectionTestQuery = SELECT 1 minimumIdle = 10 maximumPoolSize = 10 readOnly = false
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 defaultAutoCommit = true defaultReadOnly = false defaultTransactionIsolation = NONEinitialSize = 10 maxActive = 100 maxIdle = 8 minIdle = 0 maxWait = 30000 validationQuery = SELECT 1 testOnBorrow = false testOnReturn = false testWhileIdle = false
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 maxPoolSize = 15 minPoolSize = 3 initialPoolSize = 3 maxIdleTime = 0 checkoutTimeout = 0 acquireIncrement = 3 acquireRetryAttempts = 0 acquireRetryDelay = 1000 autoCommitOnClose = false automaticTestTable = nullbreakAfterAcquireFailure = false idleConnectionTestPeriod = 0 maxStatements = 0 maxStatementsPerConnection = 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 defaultAutoCommit = true defaultReadOnly = false defaultTransactionIsolation = NONEinitialSize = 10 maxActive = 100 maxIdle = 8 minIdle = 0 maxWait = 30000 validationQuery = SELECT 1 testOnBorrow = false testOnReturn = false testWhileIdle = false
数据源工厂-DsFactory 数据源(DataSource)的概念来自于JDBC规范中,一个数据源表示针对一个数据库(或者集群)的描述,从数据源中我们可以获得N个数据库连接,从而对数据库进行操作。
每一个开源JDBC连接池都有对DataSource的实现,比如Druid为DruidDataSource,Hikari为HikariDataSource。但是各大连接池配置各不相同,配置文件也不一样,Hutool的针对常用的连接池做了封装,最大限度简化和提供一致性配置。
Hutool的解决方案是:在ClassPath中使用config/db.setting一个配置文件,配置所有种类连接池的数据源,然后使用DsFactory.get()方法自动识别数据源以及自动注入配置文件中的连接池配置(包括数据库连接配置)。DsFactory通过try的方式按照顺序检测项目中引入的jar包来甄别用户使用的是哪种连接池,从而自动构建相应的数据源。
Hutool支持以下连接池,并按照其顺序检测存在与否:
HikariCP
Druid
Tomcat
Dbcp
C3p0
在没有引入任何连接池的情况下,Hutool会使用其内置的连接池:Hutool Pooled(简易连接池,不推荐在线上环境使用)。
Hutool不会强依赖于任何第三方库,在Hutool支持的连接池范围内,用户需自行选择自己喜欢的连接池并引入。
Maven项目中,在src/main/resources/config下创建文件db.setting,编写配置文件即可。这个配置文件位置就是Hutool与用户间的一个约定(符合约定大于配置的原则):
配置文件分为两部分
1 2 3 4 5 6 7 8 9 ## 基本配置信息
** 小提示 ** 其中driver是可选的,Hutool会根据url自动加载相应的Driver类。基本连接信息是所有连接池通用的,原则上,只有基本信息就可以成功连接并操作数据库。
针对不同的连接池,除了基本信息外的配置都各不相同,Hutool针对不同的连接池封装了其配置项,可以在项目的src/test/resources/example中看到针对不同连接池的配置文件样例。
我们以HikariCP为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 自动提交true 30 秒30000 10 分钟600000 30 分钟,建议设置比数据库超时时长少30 秒,参考MySQL wait_timeout参数(show variables like '%timeout%' ;)1800000 SQL connectionTestQuery = SELECT 1 10 10 ;推荐的公式:((core_count * 2 ) + effective_spindle_count)10 true , 保证安全false
1 2 DataSource ds = DSFactory.get()
是滴,就是这么简单,一个简单的方法,可以识别数据源并读取默认路径(config/db.setting)下信息从而获取数据源。
当然你依旧可以按照连接池本身的方式获取数据源对象。我们以Druid为例:
1 2 3 4 5 DruidDataSource ds2 = new DruidDataSource ();"jdbc:mysql://localhost:3306/dbName" );"root" );"123456" );
有时候我们的操作非常简单,亦或者只是测试下远程数据库是否畅通,我们可以使用Hutool提供的SimpleDataSource:
1 DataSource ds = new SimpleDataSource ("jdbc:mysql://localhost:3306/dbName" , "root" , "123456" );
SimpleDataSource只是DriverManager.getConnection的简单包装,本身并不支持池化功能,此类特别适合少量数据库连接的操作。
同样的,SimpleDataSource也支持默认配置文件:
1 DataSource ds = new SimpleDataSource ();
有时候当项目引入多种数据源时,我们希望自定义需要的连接池,此时可以:
1 2 3 new TomcatDSFactory ());DataSource ds = DSFactory.get();
需要注意的是,DSFactory.setCurrentDSFactory是一个全局方法,必须在所有获取数据源的时机之前调用,调用一次即可(例如项目启动)。
有时候由于项目规划的问题,我们希望自定义数据库配置Setting的位置,甚至是动态加载Setting对象,此时我们可以使用以下方法从其它的Setting对象中获取数据库连接信息:
1 2 3 4 5 Setting setting = new Setting ("otherPath/other.setting" );DataSource ds = DSFactory.create(setting).getDataSource();
有的时候我们需要操作不同的数据库,也有可能我们需要针对线上、开发和测试分别操作其数据库,无论哪种情况,Hutool都针对多数据源做了很棒的支持。
多数据源有两种方式可以实现:
就是按照自定义配置文件的方式读取多个配置文件即可。
1 2 3 4 5 6 7 8 9 [group_db1]
我们按照上面的方式编写db.setting文件,然后:
1 2 DataSource ds1 = DSFactory.get("group_db1" );DataSource ds2 = DSFactory.get("group_db2" );
这样我们就可以在一个配置文件中实现多数据源的配置。
Hutool通过多种方式获取DataSource对象,获取后除了可以在Hutool自身应用外,还可以将此对象传入不同的框架以实现无缝结合。
Hutool对数据源的封装很好的诠释了以下几个原则:
自动识别优于用户定义
便捷性与灵活性并存
适配与兼容
SQL执行器-SqlExecutor 这是一个静态类,对JDBC的薄封装,里面的静态方法只有两种:执行非查询的SQL语句和查询的SQL语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Connection conn = null ;try {int count = SqlExecutor.execute(conn, "UPDATE " + TABLE_NAME + " set field1 = ? where id = ?" , 0 , 0 );"影响行数:{}" , count);Long generatedKey = SqlExecutor.executeForGeneratedKey(conn, "UPDATE " + TABLE_NAME + " set field1 = ? where id = ?" , 0 , 0 );"主键:{}" , generatedKey);"select * from " + TABLE_NAME + " where param1 = ?" , new EntityListHandler (), "值" );"{}" , entityList);catch (SQLException e) {"SQL error!" );finally {
案例1-导出Blob字段图像 有一张单表存储着图片(图片使用Blob字段)以及图片的相关信息,需求是从数据库中将这些Blob字段内容保存为图片文件,文件名为图片的相关信息。
数据库:Oracle 本地:Windows 工具:Hutool-db模块
1 2 3 4 5 6 # JDBC url,必须 # 用户名,必须 # 密码,必须,如果密码为空,请填写 pass =
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class PicTransfer {public static void main (String[] args) throws SQLException {"NAME" , "TYPE" , "GROUP" , "PIC" ), "PIC_INFO" ).set("TYPE" , 1 ),while (rs.next()){return null ;private static void save (ResultSet rs) throws SQLException{String destDir = "f:/pic" ;String path = StrUtil.format("{}/{}-{}.jpg" , destDir, rs.getString("NAME" ), rs.getString("GROUP" ));"PIC" ).getBinaryStream(), path);
Redis客户端封装-RedisDS RedisDS基于Jedis封装,需自行引入Jedis依赖。
1 2 3 4 5 <dependency > <groupId > redis.clients</groupId > <artifactId > jedis</artifactId > <version > 3.7.0</version > </dependency >
在ClassPath(或者src/main/resources)的config目录下下新建redis.setting
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
1 Jedis jedis = RedisDS.create().getJedis();
MongoDB客户端封装-MongoDS 针对MongoDB客户端封装。客户端需自行引入依赖。
1 2 3 4 5 <dependency > <groupId > org.mongodb</groupId > <artifactId > mongo-java-driver</artifactId > <version > 3.12.10</version > </dependency >
在ClassPath(或者src/main/resources)的config目录下下新建mongo.setting
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 connectionsPerHost =100 threadsAllowedToBlockForConnectionMultiplier =10 maxWaitTime = 120000 connectTimeout =0 socketTimeout =0 socketKeepAlive =false [master] host = 127.0 .0.1 :27017 [slave] host = 127.0 .0.1 :27018
1 2 MongoDatabase db = MongoFactory.getDS("master" , "slave" ).getDb("test" );
Http客户端工具类-HttpUtil HttpUtil是应对简单场景下Http请求的工具类封装,此工具封装了HttpRequest 对象常用操作,可以保证在一个方法之内完成Http请求。
此模块基于JDK的HttpUrlConnection封装完成,完整支持https、代理和文件上传。
针对最为常用的GET和POST请求,HttpUtil封装了两个方法,
HttpUtil.getHttpUtil.post
这两个方法用于请求普通页面,然后返回页面内容的字符串,同时提供一些重载方法用于指定请求参数(指定参数支持File对象,可实现文件上传,当然仅仅针对POST请求)。
GET请求栗子:
1 2 3 4 5 6 7 8 9 10 11 "https://www.baidu.com" );"https://www.baidu.com" , CharsetUtil.CHARSET_UTF_8);new HashMap <>();"city" , "北京" );"https://www.baidu.com" , paramMap);
POST请求例子:
1 2 3 4 HashMap<String, Object> paramMap = new HashMap <>();"city" , "北京" );"https://www.baidu.com" , paramMap);
1 2 3 4 5 HashMap<String, Object> paramMap = new HashMap <>();"file" , FileUtil.file("D:\\face.jpg" ));"https://www.baidu.com" , paramMap);
因为Hutool-http机制问题,请求页面返回结果是一次性解析为byte[]的,如果请求URL返回结果太大(比如文件下载),那内存会爆掉,因此针对文件下载HttpUtil单独做了封装。文件下载在面对大文件时采用流的方式读写,内存中只是保留一定量的缓存,然后分块写入硬盘,因此大文件情况下不会对内存有压力。
1 2 3 4 5 String fileUrl = "http://mirrors.sohu.com/centos/8.4.2105/isos/x86_64/CentOS-8.4.2105-x86_64-dvd1.iso" ;long size = HttpUtil.downloadFile(fileUrl, FileUtil.file("e:/" ));"Download size: " + size);
当然,如果我们想感知下载进度,还可以使用另一个重载方法回调感知下载进度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 "e:/" ), new StreamProgress (){@Override public void start () {"开始下载。。。。" );@Override public void progress (long progressSize) {"已下载:{}" , FileUtil.readableFileSize(progressSize));@Override public void finish () {"下载完成!" );
StreamProgress接口实现后可以感知下载过程中的各个阶段。
当然,工具类提供了一个更加抽象的方法:HttpUtil.download,此方法会请求URL,将返回内容写入到指定的OutputStream中。使用这个方法,可以更加灵活的将HTTP内容转换写出,以适应更多场景。
HttpUtil.encodeParams 对URL参数做编码,只编码键和值,提供的值可以是url附带参数,但是不能只是urlHttpUtil.toParams和HttpUtil.decodeParams 两个方法是将Map参数转为URL参数字符串和将URL参数字符串转为Map对象HttpUtil.urlWithForm是将URL字符串和Map参数拼接为GET请求所用的完整字符串使用HttpUtil.getMimeType 根据文件扩展名快速获取其MimeType(参数也可以是完整文件路径)
如果想设置头信息、超时、代理等信息,请见下一章节《Http客户端-HttpRequest》。
Http请求-HttpRequest 本质上,HttpUtil中的get和post工具方法都是HttpRequest对象的封装,因此如果想更加灵活操作Http请求,可以使用HttpRequest。
我们以POST请求为例:
1 2 3 4 5 6 7 String result2 = HttpRequest.post(url)"Hutool http" )20000 )
通过链式构建请求,我们可以很方便的指定Http头信息和表单信息,最后调用execute方法即可执行请求,返回HttpResponse对象。HttpResponse包含了服务器响应的一些信息,包括响应的内容和响应的头信息。通过调用body方法即可获取响应内容。
1 2 3 4 String json = ...;String result2 = HttpRequest.post(url)
如果代理无需账号密码,可以直接:
1 2 3 4 String result2 = HttpRequest.post(url)"127.0.0.1" , 9080 )
如果需要自定其他类型代理或更多的项目,可以:
1 2 3 4 5 String result2 = HttpRequest.post(url)new Proxy (Proxy.Type.HTTP,new InetSocketAddress (host, port))
如果遇到https代理错误Proxy returns "HTTP/1.0 407 Proxy Authentication Required",可以尝试:
1 2 3 4 5 6 7 8 9 System.setProperty("jdk.http.auth.tunneling.disabledSchemes" , "" );new Authenticator () {@Override public PasswordAuthentication getPasswordAuthentication () {return new PasswordAuthentication (authUser, authPassword.toCharArray());
同样,我们通过HttpRequest可以很方便的做以下操作:
指定请求头
自定义Cookie(cookie方法)
指定是否keepAlive(keepAlive方法)
指定表单内容(form方法)
指定请求内容,比如rest请求指定JSON请求体(body方法)
超时设置(timeout方法)
指定代理(setProxy方法)
指定SSL协议(setSSLProtocol)
简单验证(basicAuth方法)
Http响应-HttpResponse HttpResponse是HttpRequest执行execute()方法后返回的一个对象,我们可以通过此对象获取服务端返回的:
Http状态码(getStatus方法)
返回内容编码(contentEncoding方法)
是否Gzip内容(isGzip方法)
返回内容(body、bodyBytes、bodyStream方法)
响应头信息(header方法)
此对象的使用非常简单,最常用的便是body方法,会返回字符串Http响应内容。如果想获取byte[]则调用bodyBytes即可。
1 2 HttpResponse res = HttpRequest.post(url)..execute();
1 2 3 4 5 HttpResponse res = HttpRequest.post(url)..execute();"Content-Disposition" ));
HTML工具类-HtmlUtil 针对Http请求中返回的Http内容,Hutool使用此工具类来处理一些HTML页面相关的事情。
比如我们在使用爬虫爬取HTML页面后,需要对返回页面的HTML内容做一定处理,比如去掉指定标签(例如广告栏等)、去除JS、去掉样式等等,这些操作都可以使用HtmlUtil 完成。
转义HTML特殊字符,包括:
' 替换为 '" 替换为 "& 替换为 &< 替换为 <> 替换为 >
1 2 3 String html = "<html><body>123'123'</body></html>" ;String escape = HtmlUtil.escape(html);
还原被转义的HTML特殊字符
1 2 3 String escape = "<html><body>123'123'</body></html>" ;String unescape = HtmlUtil.unescape(escape);
清除指定HTML标签和被标签包围的内容
1 2 3 String str = "pre<img src=\"xxx/dfdsfds/test.jpg\">" ;String result = HtmlUtil.removeHtmlTag(str, "img" );
清除所有HTML标签,但是保留标签内的内容
1 2 3 String str = "pre<div class=\"test_div\">\r\n\t\tdfdsfdsfdsf\r\n</div><div class=\"test_div\">BBBB</div>" ;String result = HtmlUtil.cleanHtmlTag(str);
清除指定HTML标签,不包括内容
1 2 3 String str = "pre<div class=\"test_div\">abc</div>" ;String result = HtmlUtil.unwrapHtmlTag(str, "div" );
去除HTML标签中的指定属性,如果多个标签有相同属性,都去除
1 2 3 String html = "<div class=\"test_div\"></div><span class=\"test_div\"></span>" ;String result = HtmlUtil.removeHtmlAttr(html, "class" );
去除指定标签的所有属性
1 2 3 String html = "<div class=\"test_div\" width=\"120\"></div>" ;String result = HtmlUtil.removeAllHtmlAttr(html, "div" );
1 2 3 String html = "<alert></alert>" ;String filter = HtmlUtil.filter(html);
UA工具类-UserAgentUtil User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、浏览器及版本、浏览器渲染引擎等。
Hutool在4.2.1之后支持User-Agent的解析。
以桌面浏览器为例,假设你已经获取了用户的UA:
1 String uaStr = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1" ;
我们可以借助UserAgentUtil.parse方法解析:
1 2 3 4 5 6 7 8 UserAgent ua = UserAgentUtil.parse(uaStr);
常用Http状态码-HttpStatus 针对Http响应,Hutool封装了一个类用于保存Http状态码
此类用于保存一些状态码的别名,例如:
1 2 3 4 public static final int HTTP_OK = 200 ;
案例1-爬取开源中国的开源资讯
Soap客户端-SoapClient 在接口对接当中,WebService接口占有着很大份额,而我们为了使用这些接口,不得不引入类似Axis等库来实现接口请求。
现在有了Hutool,就可以在无任何依赖的情况下,实现简便的WebService请求。
使用SoapUI 解析WSDL地址,找到WebService方法和参数。
我们得到的XML模板为:
1 2 3 4 5 6 7 8 9 <soapenv:Envelope xmlns:soapenv ="http://schemas.xmlsoap.org/soap/envelope/" xmlns:web ="http://WebXml.com.cn/" > <soapenv:Header /> <soapenv:Body > <web:getCountryCityByIp > <web:theIpAddress > ?</web:theIpAddress > </web:getCountryCityByIp > </soapenv:Body > </soapenv:Envelope >
按照SoapUI中的相应内容构建SOAP请求。
我们知道:
方法名为:web:getCountryCityByIp
参数只有一个,为:web:theIpAddress
定义了一个命名空间,前缀为web,URI为http://WebXml.com.cn/
这样我们就能构建相应SOAP请求:
1 2 3 4 5 6 7 8 9 10 SoapClient client = SoapClient.create("http://www.webxml.com.cn/WebServices/IpAddressSearchWebService.asmx" )"web:getCountryCityByIp" , "http://WebXml.com.cn/" )"theIpAddress" , "218.21.240.106" );true ));
调用SoapClient对象的getMsgStr方法可以查看生成的XML,以检查是否与SoapUI生成的一致。
1 2 SoapClient client = ...;true ));
对于请求体是列表参数或多参数的情况,如:
1 2 3 4 5 6 <web:method > <arg0 > <fd1 > aaa</fd1 > <fd2 > bbb</fd2 > </arg0 > </web:method >
这类请求可以借助addChildElement完成。
1 2 3 4 5 SoapClient client = SoapClient.create("https://hutool.cn/WebServices/test.asmx" )"web:method" , "http://hutool.cn/" )SOAPElement arg0 = client.getMethodEle().addChildElement("arg0" );"fdSource" ).setValue("?" );"fdTemplated" ).setValue("?" );
详细的问题解答见:https://gitee.com/dromara/hutool/issues/I4QL1V
简易Http服务器-SimpleServer Oracle JDK提供了一个简单的Http服务端类,叫做HttpServer,当然它是sun的私有包,位于com.sun.net.httpserver下,必须引入rt.jar才能使用,Hutool基于此封装了SimpleServer,用于在不引入Tomcat、Jetty等容器的情况下,实现简单的Http请求处理。
SimpleServer在Hutool-5.3.0后才引入,请升级到最新版本
启动一个Http服务非常简单:
1 HttpUtil.createServer(8888 ).start();
通过浏览器访问 http://localhost:8888/ 即可,当然此时访问任何path都是404。
处理简单请求:
1 2 3 4 5 HttpUtil.createServer(8888 )("/" , (req, res)->{ res.write("Hello Hutool Server" ); }) .start () ;
此处我们定义了一个简单的action,绑定在”/“路径下,此时我们可以访问,输出“Hello Hutool Server”。
同理,我们通过调用addAction方法,定义不同path的处理规则,实现相应的功能。
Hutool默认提供了简单的文件服务,即定义一个root目录,则请求路径后直接访问目录下的资源,默认请求index.html,类似于Nginx。
1 2 3 4 HttpUtil .Server(8888) Root("D:\\workspace\\site\\hutool-site" ) () ;
此时访问http://localhost:8888/即可访问HTML静态页面。
hutool-site是Hutool主页的源码项目,地址在:https://gitee.com/loolly_admin/hutool-site,下载后配合SimpleServer实现离线文档。
有时候我们需要自定义读取请求参数,然后根据参数访问不同的数据,整理返回,此时我们自定义Action即可完成:
返回JSON数据
1 2 3 4 5 HttpUtil.createServer(8888 )"/restTest" , (request, response) ->"{\"id\": 1, \"msg\": \"OK\"}" , ContentType.JSON.toString())
获取表单数据并返回
1 2 3 4 5 HttpUtil.createServer(8888 )"/formTest" , (request, response) ->
除了常规Http服务,Hutool还封装了文件上传操作:
1 2 3 4 5 6 7 8 9 HttpUtil.createServer(8888 )"/file" , (request, response) -> {final UploadFile file = request.getMultipart().getFile("file" );"d:/test/" );"OK!" , ContentType.TEXT_PLAIN.toString());
全局定时任务-CronUtil CronUtil通过一个全局的定时任务配置文件,实现统一的定时任务调度。
对于Maven项目,首先在src/main/resources/config下放入cron.setting文件(默认是这个路径的这个文件),然后在文件中放入定时规则,规则如下:
1 2 3 4 # 我是注释 */10 * * * * TestJob2.run = * /10 * * * *
中括号表示分组,也表示需要执行的类或对象方法所在包的名字,这种写法有利于区分不同业务的定时任务。
TestJob.run表示需要执行的类名和方法名(通过反射调用,不支持Spring和任何框架的依赖注入),*/10 * * * *表示定时任务表达式,此处表示每10分钟执行一次,以上配置等同于:
1 2 com.company.aaa.job.TestJob.run = */10 * * * * com.company.aaa.job.TestJob2.run = * /10 * * * *
提示 关于表达式语法,见:http://www.cnblogs.com/peida/archive/2013/01/08/2850483.html
如果想让执行的作业同定时任务线程同时结束,可以将定时任务设为守护线程,需要注意的是,此模式下会在调用stop时立即结束所有作业线程,请确保你的作业可以被中断:
考虑到Quartz表达式的兼容性,且存在对于秒级别精度匹配的需求,Hutool可以通过设置使用秒匹配模式来兼容。
1 2 true );
此时Hutool可以兼容Quartz表达式(5位表达式、6位表达式都兼容)
当然,如果你想动态的添加定时任务,使用CronUtil.schedule(String schedulingPattern, Runnable task)方法即可(使用此方法加入的定时任务不会被写入到配置文件)。
1 2 3 4 5 6 7 8 9 10 CronUtil.schedule("*/2 * * * * *" , new Task () {@Override public void execute () {"Task excuted." );true );
邮件工具-MailUtil 在Java中发送邮件主要品依靠javax.mail包,但是由于使用比较繁琐,因此Hutool针对其做了封装。由于依赖第三方包,因此将此工具类归类到extra模块中。
Hutool对所有第三方都是可选依赖,因此在使用MailUtil时需要自行引入第三方依赖。
1 2 3 4 5 <dependency > <groupId > com.sun.mail</groupId > <artifactId > javax.mail</artifactId > <version > 1.6.2</version > </dependency >
说明 com.sun.mail是javax.mail升级后的版本,新版本包名做了变更。
在classpath(在标准Maven项目中为src/main/resources)的config目录下新建mail.setting文件,最小配置内容如下,在此配置下,smtp服务器和用户名都将通过from参数识别:
1 2 3 4 from = hutool@yeah.net pass = q1w2e3
有时候一些非标准邮箱服务器(例如企业邮箱服务器)的smtp地址等信息并不与发件人后缀一致,端口也可能不同,此时Hutool可以提供完整的配置文件:
完整配置
1 2 3 4 5 6 7 8 9 10 host = smtp.yeah.net port = 25 from = hutool@yeah.net user = hutool pass = q1w2e3
注意 邮件服务器必须支持并打开SMTP协议,详细请查看相关帮助说明 配置文件的样例中提供的是我专门为测试邮件功能注册的yeah.net邮箱,帐号密码公开,供Hutool用户测试使用。
发送普通文本邮件,最后一个参数可选是否添加多个附件:
1 MailUtil.send("hutool@foxmail.com" , "测试" , "邮件来自Hutool测试" , false );
发送HTML格式的邮件并附带附件,最后一个参数可选是否添加多个附件:
1 MailUtil ."hutool@foxmail.com" , "测试" , "<h1>邮件来自Hutool测试</h1>" , true , FileUtil ."d:/aaa.xml" ));
群发邮件,可选HTML或普通文本,可选多个附件:
1 2 3 4 5 6 7 ArrayList<String> tos = CollUtil.newArrayList("person1@bbb.com" , "person2@bbb.com" , "person3@bbb.com" , "person4@bbb.com" );"测试" , "邮件来自Hutool群发测试" , false );
发送邮件非常简单,只需一个方法即可搞定其中按照参数顺序说明如下:
tos: 对方的邮箱地址,可以是单个,也可以是多个(Collection表示)
subject:标题
content:邮件正文,可以是文本,也可以是HTML内容
isHtml: 是否为HTML,如果是,那参数3识别为HTML内容
files: 可选:附件,可以为多个或没有,将File对象加在最后一个可变参数中即可
自定义邮件服务器
除了使用配置文件定义全局账号以外,MailUtil.send方法同时提供重载方法可以传入一个MailAccount对象,这个对象为一个普通Bean,记录了邮件服务器信息。
1 2 3 4 5 6 7 8 9 MailAccount account = new MailAccount ();"smtp.yeah.net" );"25" );true );"hutool@yeah.net" );"hutool" );"q1w2e3" );"hutool@foxmail.com" ), "测试" , "邮件来自Hutool测试" , false );
使用SSL加密方式发送邮件 在使用QQ或Gmail邮箱时,需要强制开启SSL支持,此时我们只需修改配置文件即可:
1 2 3 4 5 6 7 from = 小磊<hutool@yeah.net> pass = q1w2e3 sslEnable = true
在原先极简配置下只需加入sslEnable即可完成SSL连接,当然,这是最简单的配置,很多参数根据已有参数已设置为默认。
完整的配置文件如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 host = smtp.yeah.net port = 465 from = hutool@yeah.net user = hutool pass = q1w2e3 starttlsEnable = true sslEnable = true socketFactoryClass = javax.net.ssl.SSLSocketFactory socketFactoryFallback = true socketFactoryPort = 465 timeout = 0 connectionTimeout = 0
针对QQ邮箱和Foxmail邮箱的说明
(1) QQ邮箱中SMTP密码是单独生成的授权码,而非你的QQ密码,至于怎么生成,见腾讯的帮助说明:http://service.mail.qq.com/cgi-bin/help?subtype=1&&id=28&&no=1001256
使用帮助引导生成授权码后,配置如下即可:
(2) Foxmail邮箱本质上也是QQ邮箱的一种别名,你可以在你的QQ邮箱中设置一个foxmail邮箱,不过配置上有所区别。在Hutool中user属性默认提取你邮箱@前面的部分,但是foxmail邮箱是无效的,需要单独配置为与之绑定的qq号码或者XXXX@qq.com的XXXX。即:
1 2 3 4 host = smtp.qq.comuser = foxmail 邮箱对应的QQ号码或者qq邮箱@前面部分
(3) 阿里云邮箱的user是邮箱的完整地址,即xxx@aliyun.com
针对QQ邮箱(foxmail)PKIX path building failed错误(since 5.6.4)
部分用户反馈发送邮件时会遇到错误:
1 2 3 cn.hutool.extra.mail.MailException: MessagingException: Could not connect to SMTP host: smtp.qq.com, port: 465
这个错误可能是需要SSL验证造成的,我们可以手动跳过这个验证:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 MailAccount mailAccount = new MailAccount ();true );true );MailSSLSocketFactory sf = new MailSSLSocketFactory ();true );"mail.smtp.ssl.socketFactory" , sf);Mail mail = Mail.create(mailAccount)"xx@xx.com" )"邮箱验证" )"您的验证码是:<h3>2333</h3>" )true )
二维码工具-QrCodeUtil 由于大家对二维码的需求较多,对于二维码的生成和解析我认为应该作为简单的工具存在于Hutool中。考虑到自行实现的难度,因此Hutool针对被广泛接受的的zxing 库进行封装。而由于涉及第三方包,因此归类到extra模块中。
考虑到Hutool的非强制依赖性,因此zxing需要用户自行引入:
1 2 3 4 5 <dependency > <groupId > com.google.zxing</groupId > <artifactId > core</artifactId > <version > 3.3.3</version > </dependency >
说明 zxing-3.3.3是此文档编写时的最新版本,理论上你引入的版本应与此版本一致或比这个版本新。
在此我们将Hutool主页的url生成为二维码,微信扫一扫可以看到H5主页哦:
1 2 "https://hutool.cn/" , 300 , 300 , FileUtil.file("d:/qrcode.jpg" ));
效果qrcode.jpg:
基本参数设定
通过QrConfig可以自定义二维码的生成参数,例如长、宽、二维码的颜色、背景颜色、边距等参数,使用方法如下:
1 2 3 4 5 6 7 8 9 10 QrConfig config = new QrConfig (300 , 300 );3 );"http://hutool.cn/" , config, FileUtil.file("e:/qrcode.jpg" ));
效果qrcode.jpg:
附带logo小图标
1 2 3 4 5 QrCodeUtil.generate("http://hutool.cn/" , "e:/logo_small.jpg" ), "e:/qrcodeWithLogo.jpg" )
效果如图:
调整纠错级别
很多时候,二维码无法识别,这时就要调整纠错级别。纠错级别使用zxing的ErrorCorrectionLevel枚举封装,包括:L、M、Q、H几个参数,由低到高。低级别的像素块更大,可以远距离识别,但是遮挡就会造成无法识别。高级别则相反,像素块小,允许遮挡一定范围,但是像素块更密集。
1 2 3 4 QrConfig config = new QrConfig ();"https://hutool.cn/" , config, FileUtil.file("e:/qrcodeCustom.jpg" ));
效果如图:
1 2 String decode = QrCodeUtil.decode(FileUtil.file("d:/qrcode.jpg" ));
Servlet工具-ServletUtil 最早Servlet相关的工具并不在Hutool的封装考虑范围内,但是后来很多人提出需要一个Servlet Cookie工具,于是我决定建立ServletUtil,这样工具的使用范围就不仅限于Cookie,还包括参数等等。
其实最早的Servlet封装来自于作者的一个MVC框架:Hulu ,这个MVC框架对Servlet做了一层封装,使请求处理更加便捷。于是Hutool将Hulu中Request类和Response类中的方法封装于此。
1 2 3 4 5 6 7 <dependency > <groupId > javax.servlet</groupId > <artifactId > javax.servlet-api</artifactId > <version > 3.1.0</version > <scope > provided</scope > </dependency >
getParamMap 获得所有请求参数fillBean 将请求参数转为BeangetClientIP 获取客户端IP,支持从Nginx头部信息获取,也可以自定义头部信息获取位置getHeader、getHeaderIgnoreCase 获得请求header中的信息isIE 客户浏览器是否为IEisMultipart 是否为Multipart类型表单,此类型表单用于文件上传getCookie 获得指定的CookiereadCookieMap 将cookie封装到Map里面addCookie 设定返回给客户端的Cookiewrite 返回数据给客户端setHeader 设置响应的Header
模板引擎封装-TemplateUtil 随着前后分离的流行,JSP技术和模板引擎慢慢变得不再那么重要,但是早某些场景中(例如邮件模板、页面静态化等)依旧无可可替代,但是各种模板引擎语法大相径庭,使用方式也不尽相同,学习成本很高。Hutool旨在封装各个引擎的共性,使用户只关注模板语法即可,减少学习成本。
Hutool现在封装的引擎有:
类似于Java日志门面的思想,Hutool将模板引擎的渲染抽象为两个概念:
TemplateEngine 模板引擎,用于封装模板对象,配置各种配置
Template 模板对象,用于配合参数渲染产生内容
通过实现这两个接口,用户便可抛开模板实现,从而渲染模板。Hutool同时会通过TemplateFactory根据用户引入的模板引擎库的jar来自动选择用哪个引擎来渲染 。
1 2 3 4 5 6 7 8 9 TemplateEngine engine = TemplateUtil.createEngine(new TemplateConfig ());Template template = engine.getTemplate("Hello ${name}" );String result = template.render(Dict.create().set("name" , "Hutool" ));
也就是说,使用Hutool之后,无论你用任何一种模板引擎,代码不变(只变更模板内容)。
只需修改TemplateConfig配置文件内容即可更换(这里以Velocity为例):
1 2 3 TemplateEngine engine = TemplateUtil.createEngine(new TemplateConfig ("templates" , ResourceMode.CLASSPATH));Template template = engine.getTemplate("velocity_test.vtl" );String result = template.render(Dict.create().set("name" , "Hutool" ));
查找模板的方式由ResourceMode定义,包括:
CLASSPATH 从ClassPath加载模板
FILE 从File本地目录加载模板
WEB_ROOT 从WebRoot目录加载模板
STRING 从模板文本加载模板
COMPOSITE 复合加载模板(分别从File、ClassPath、Web-root、String方式尝试查找模板)
Jsch(SSH)工具-JschUtil 此工具最早来自于我的早期项目:Common-tools,当时是为了解决在存在堡垒机(跳板机)环境时无法穿透堡垒机访问内部主机端口问题,于是辗转找到了jsch 库。为了更加便捷的、且容易理解的方式使用此库,因此有了JschUtil。
1 2 3 4 5 <dependency > <groupId > com.jcraft</groupId > <artifactId > jsch</artifactId > <version > 0.1.54</version > </dependency >
说明 截止本文档撰写完毕,jsch的最新版为0.1.54,理论上应引入的版本应大于或等于此版本。
1 2 Session session = JschUtil.getSession("10.1.1.1" , 22 , "test" , "123456" );
1 2 3 4 5 Session session = JschUtil.getSession("10.1.1.1" , 22 , "test" , "123456" );"172.20.12.123" , 8080 , 8080 );
generateLocalPort 生成一个本地端口(从10001开始尝试,找到一个未被使用的本地端口)unBindPort 解绑端口映射openAndBindPortToLocal 快捷方法,将连接到跳板机和绑定远程主机端口到本地使用一个方法搞定close 关闭SSH会话
FTP客户端封装-Ftp FTP客户端封装,此客户端基于Apache Commons Net 。
1 2 3 4 5 <dependency > <groupId > commons-net</groupId > <artifactId > commons-net</artifactId > <version > 3.6</version > </dependency >
1 2 3 4 5 6 7 8 9 10 11 Ftp ftp = new Ftp ("172.0.0.1" );"/opt/upload" );"/opt/upload" , FileUtil.file("e:/test.jpg" ));"/opt/upload" , "test.jpg" , FileUtil.file("e:/test2.jpg" ));
FTP客户端连接到FTP服务器的21端口,发送用户名和密码登录,登录成功后要list列表或者读取数据时,客户端随机开放一个端口(1024以上),发送 PORT命令到FTP服务器,告诉服务器客户端采用主动模式并开放端口;FTP服务器收到PORT主动模式命令和端口号后,通过服务器的20端口和客户端开放的端口连接,发送数据。
FTP客户端连接到FTP服务器的21端口,发送用户名和密码登录,登录成功后要list列表或者读取数据时,发送PASV命令到FTP服务器, 服务器在本地随机开放一个端口(1024以上),然后把开放的端口告诉客户端, 客户端再连接到服务器开放的端口进行数据传输。
更多介绍见:https://www.cnblogs.com/huhaoshida/p/5412615.html
Ftp中默认是被动模式,需要切换则:
1 2 3 4 Ftp ftp = new Ftp ("172.0.0.1" );
简易FTP服务器-SimpleFtpServer Hutool基于 [Apache FtpServer](http://mina.apache.org/ftpserver-project/)封装了一个简易的FTP服务端组件,主要用于在一些测试场景或小并发应用场景下使用。
1 2 3 4 5 <dependency > <groupId > org.apache.ftpserver</groupId > <artifactId > ftpserver-core</artifactId > <version > 1.1.1</version > </dependency >
1 2 3 4 5 SimpleFtpServer"d:/test/ftp/" )
此时就可以通过资源管理器访问:
1 2 3 4 5 6 7 8 9 BaseUser user = new BaseUser ();"username" );"123" );"d:/test/user/" );
Emoji工具-EmojiUtil 考虑到MySQL等数据库中普通的UTF8编码并不支持Emoji(只有utf8mb4支持),因此对于数据中的Emoji字符进行处理(转换、清除)变成一项必要工作。因此Hutool基于emoji-java库提供了Emoji工具实现。
此工具在Hutoo-4.2.1之后版本可用。
1 2 3 4 5 <dependency > <groupId > com.vdurmont</groupId > <artifactId > emoji-java</artifactId > <version > 4.0.0</version > </dependency >
转义Emoji字符
1 String alias = EmojiUtil.toAlias("😄" );
将转义的别名转为Emoji字符
1 String emoji = EmojiUtil .to Unicode(":smile:" ) ;
将字符串中的Unicode Emoji字符转换为HTML表现形式
1 String alias = EmojiUtil .to Html("😄" ) ;
中文分词封装-TokenizerUtil 现阶段,应用于搜索引擎和自然语言处理的中文分词库五花八门,使用方式各不统一,虽然有适配于Lucene和Elasticsearch的插件,但是我们想在多个库之间选择更换时,依旧有学习时间。
Hutool针对常见中文分词库做了统一接口封装,既定义一套规范,隔离各个库的差异,做到一段代码,随意更换。
Hutool现在封装的引擎有:
注意 此工具和模块从Hutool-4.4.0开始支持。
类似于Java日志门面的思想,Hutool将分词引擎的渲染抽象为三个概念:
TokenizerEngine 分词引擎,用于封装分词库对象
Result 分词结果接口定义,用于抽象对文本分词的结果,实现了Iterator和Iterable接口,用于遍历分词
Word 表示分词中的一个词,既分词后的单词,可以获取单词文本、起始位置和结束位置等信息
通过实现这三个接口,用户便可抛开分词库的差异,实现多文本分词。
Hutool同时会通过TokenizerFactory根据用户引入的分词库的jar来自动选择用哪个库实现分词 。
1 2 3 4 5 6 7 8 TokenizerEngine engine = TokenizerUtil.createEngine();String text = "这两个方法的区别在于返回值" ;Result result = engine.parse(text);String resultStr = CollUtil.join((Iterator<Word>)result, " " );
当你引入Ansj,会自动路由到Ansi的库去实现分词,引入HanLP则会路由到HanLP,依此类推。
也就是说,使用Hutool之后,无论你用任何一种分词库,代码不变。
此处以HanLP为例:
1 2 3 4 5 6 7 TokenizerEngine engine = new HanLPEngine ();String text = "这两个方法的区别在于返回值" ;Result result = engine.parse(text);String resultStr = CollUtil.join((Iterator<Word>)result, " " );
Spring工具-SpringUtil 使用Spring Boot时,通过依赖注入获取bean是非常方便的,但是在工具化的应用场景下,想要动态获取bean就变得非常困难,于是Hutool封装了Spring中Bean获取的工具类——SpringUtil。
使用ComponentScan注册类
1 2 @ComponentScan(basePackages={"cn.hutool.extra.spring"})
使用Import导入
1 @Import(cn.hutool.extra.spring.SpringUtil.class)
定义一个Bean
1 2 3 4 5 6 7 8 9 10 11 12 13 @Data public static class Demo2 {private long id;private String name;@Bean(name="testDemo") public Demo2 generateDemo () {Demo2 demo = new Demo2 ();12345 );"test" );return demo;
获取Bean
1 final Demo2 testDemo = SpringUtil.getBean("testDemo" );
Cglib工具-CglibUtil CGLib (Code Generation Library) 是一个强大的,高性能,高质量的Code生成类库,通过此库可以完成动态代理、Bean拷贝等操作。
Hutool在5.4.1之后加入对Cglib的封装——CglibUtil,用于解决Bean拷贝的性能问题。
1 2 3 4 5 6 <dependency > <groupId > cglib</groupId > <artifactId > cglib</artifactId > <version > ${cglib.version}</version > <scope > compile</scope > </dependency >
Bean拷贝
首先我们定义两个Bean:
1 2 3 4 5 6 7 8 @Data public class SampleBean {private String value;@Data public class OtherSampleBean {private String value;
@Data是Lombok的注解,请自行补充get和set方法,或者引入Lombok依赖
1 2 3 4 5 6 7 8 9 SampleBean bean = new SampleBean ();"Hello world" );OtherSampleBean otherBean = new OtherSampleBean ();
当然,目标对象也可以省略,你可以传入一个class,让Hutool自动帮你实例化它:
1 2 3 4 OtherSampleBean otherBean2 = CglibUtil .OtherSampleBean .class );Value() ;
Cglib的性能是目前公认最好的,其时间主要耗费在BeanCopier创建上,因此,Hutool根据传入Class不同,缓存了BeanCopier对象,使性能达到最好。
拼音工具-PinyinUtil 拼音工具类在旧版本的Hutool中在core包中,但是发现自己实现相关功能需要庞大的字典,放在core包中便是累赘。
于是为了方便,Hutool封装了拼音的门面,用于兼容以下拼音库:
TinyPinyin
JPinyin
Pinyin4j
和其它门面模块类似,采用SPI方式识别所用的库。例如你想用Pinyin4j,只需引入jar,Hutool即可自动识别。
以下为Hutool支持的拼音库的pom坐标,你可以选择任意一个引入项目中,如果引入多个,Hutool会按照以上顺序选择第一个使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <dependency > <groupId > io.github.biezhi</groupId > <artifactId > TinyPinyin</artifactId > <version > 2.0.3.RELEASE</version > </dependency > <dependency > <groupId > com.belerweb</groupId > <artifactId > pinyin4j</artifactId > <version > 2.5.1</version > </dependency > <dependency > <groupId > com.github.stuxuhai</groupId > <artifactId > jpinyin</artifactId > <version > 1.1.8</version > </dependency >
获取拼音
1 2 String pinyin = PinyinUtil.getPinyin("你好" , " " );
这里定义的分隔符为空格,你也可以按照需求自定义分隔符,亦或者使用””无分隔符。
获取拼音首字母
1 2 String result = PinyinUtil.getFirstLetter("H是第一个" , ", " );
自定义拼音库(拼音引擎)
1 2 3 4 Pinyin4jEngine engine = new Pinyin4jEngine ();String pinyin = engine.getPinyin("你好h" , " " );
压缩封装-CompressUtil 虽然Hutool基于JDK提供了ZipUtil用于压缩或解压ZIP相关文件,但是对于7zip、tar等格式的压缩依旧无法处理,于是基于commons-compress做了进一步封装:CompressUtil。
此工具支持的格式有:
对于流式压缩支持:
GZIP
BZIP2
XZ
XZ
PACK200
SNAPPY_FRAMED
LZ4_BLOCK
LZ4_FRAMED
ZSTANDARD
DEFLATE
对于归档文件支持:
对于归档文件,Hutool提供了两个通用接口:
Archiver 数据归档,提供打包工作,如增加文件到压缩包等
Extractor 归档数据解包,用于解压或者提取压缩文件
首先引入commons-compress
1 2 3 4 5 <dependency > <groupId > org.apache.commons</groupId > <artifactId > commons-compress</artifactId > <version > 1.21</version > </dependency >
我们以7Zip为例:
1 2 3 4 5 final File file = FileUtil.file("d:/test/compress/test.7z" );"d:/test/someFiles" ));
其中ArchiveStreamFactory.SEVEN_Z就是自定义的压缩格式,可以自行选择
add方法同时支持文件或目录,多个文件目录多次调用add方法即可。
有时候我们不想把目录下所有的文件放到压缩包,这时候可以使用add方法的第二个参数Filter,此接口用于过滤不需要加入的文件。
1 2 3 4 5 6 7 8 CompressUtil.createArchiver(CharsetUtil.CHARSET_UTF_8, ArchiveStreamFactory.SEVEN_Z, zipFile)"d:/Java/apache-maven-3.6.3" ), (file)->{if ("invalid" .equals(file.getName())){return false ;return true ;
我们以7Zip为例:
1 2 3 4 5 Extractor extractor = CompressUtil.createExtractor("d:/test/compress/test.7z" ));"d:/test/compress/test2/" ));
表达式引擎封装-ExpressionUtil 与模板引擎类似,Hutool针对较为流行的表达式计算引擎封装为门面模式,提供统一的API,去除差异。 现有的引擎实现有:
首先引入我们需要的模板引擎,引入后,Hutool借助SPI机制可自动识别使用,我们以Aviator为例:
1 2 3 4 5 <dependency>5.2 .7 </version>
1 2 3 4 5 6 7 final Dict dict = Dict.create()"a" , 100.3 )"b" , 45 )"c" , -199.100 );final Object eval = ExpressionUtil.eval("a-(b-c)" , dict);
如果项目中引入多个引擎,我们想选择某个引擎执行,则可以:
1 2 3 4 5 6 7 8 9 ExpressionEngine engine = new JexlEngine ();final Dict dict = Dict.create()"a" , 100.3 )"b" , 45 )"c" , -199.100 );final Object eval = engine.eval("a-(b-c)" , dict);
引擎的核心就是实现ExpressionEngine接口,此接口只有一个方法:eval。
我们实现此接口后,在项目的META-INF/services/下创建spi文件cn.hutool.extra.expression.ExpressionEngine:
1 com.yourProject.XXXXEngine
这样就可以直接调用ExpressionUtil.eval执行表达式了。
布隆过滤器-Bloom Filter使用 布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
参考:https://www.cnblogs.com/z941030/p/9218356.html
1 2 3 4 5 6 7 8 BitMapBloomFilter filter = new BitMapBloomFilter (10 );"123" );"abc" );"ddd" );"abc" )
切面代理工具-ProxyUtil
我们定义一个接口:
1 2 3 public interface Animal {void eat () ;
定义一个实现类:
1 2 3 4 5 6 7 8 public class Cat implements Animal {@Override public void eat () {"猫吃鱼" );
我们使用TimeIntervalAspect这个切面代理上述对象,来统计猫吃鱼的执行时间:
1 2 Animal cat = ProxyUtil.proxy(new Cat (), TimeIntervalAspect.class);
TimeIntervalAspect位于cn.hutool.aop.aspects包,继承自SimpleAspect,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class TimeIntervalAspect extends SimpleAspect {private TimeInterval interval = new TimeInterval ();@Override public boolean before (Object target, Method method, Object[] args) {return true ;@Override public boolean after (Object target, Method method, Object[] args) {"Method [{}.{}] execute spend [{}]ms" , target.getClass().getName(), method.getName(), interval.intervalMs());return true ;
执行结果为:
1 2 猫吃鱼Method [cn .hutool .aop .test .AopTest $Cat .eat ] execute spend [16]ms
在调用proxy方法后,IDE自动补全返回对象为Cat,因为JDK机制的原因,我们的返回值必须是被代理类实现的接口,因此需要手动将返回值改为Animal ,否则会报类型转换失败。
使用Cglib的好处是无需定义接口即可对对象直接实现切面,使用方式完全一致:
引入Cglib依赖
1 2 3 4 5 <dependency > <groupId > cglib</groupId > <artifactId > cglib</artifactId > <version > 3.2.7</version > </dependency >
定义一个无接口类(此类有无接口都可以)
1 2 3 4 5 6 7 public class Dog {public String eat () {"狗吃肉" );Dog dog = ProxyUtil.proxy(new Dog (), TimeIntervalAspect.class);String result = dog.eat();
执行结果为:
1 2 狗吃肉Method [cn .hutool .aop .test .AopTest $Dog .eat ] execute spend [13]ms
ProxyUtil中还提供了一些便捷的Proxy方法封装,例如newProxyInstance封装了Proxy.newProxyInstance方法,提供泛型返回值,并提供更多参数类型支持。
动态代理对象的创建原理是假设创建的代理对象名为 $Proxy0:
根据传入的interfaces动态生成一个类,实现interfaces中的接口
通过传入的classloder将刚生成的类加载到jvm中。即将$Proxy0类load
调用$Proxy0的$Proxy0(InvocationHandler)构造函数 创建$Proxy0的对象,并且用interfaces参数遍历其所有接口的方法,并生成实现方法,这些实现方法的实现本质上是通过反射调用被代理对象的方法。
将$Proxy0的实例返回给客户端。
当调用代理类的相应方法时,相当于调用 InvocationHandler.invoke(Object, Method, Object []) 方法。
Script工具-ScriptUtil 针对Script执行工具化封装
ScriptUtil.eval 执行Javascript脚本,参数为脚本字符串。
栗子:
1 ScriptUtil.eval("print('Script test!');" );
ScriptUtil.compile 编译脚本,返回一个CompiledScript对象
栗子:
1 2 3 4 5 6 CompiledScript script = ScriptUtil.compile("print('Script test!');" );try {catch (ScriptException e) {throw new ScriptRuntimeException (e);
Excel工具-ExcelUtil Excel操作工具封装
从文件中读取Excel为ExcelReader
1 ExcelReader reader = ExcelUtil.getReader(FileUtil.file("test.xlsx" ));
从流中读取Excel为ExcelReader(比如从ClassPath中读取Excel文件)
1 ExcelReader reader = ExcelUtil.getReader(ResourceUtil.getStream("aaa.xlsx" ));
读取指定的sheet
1 2 3 4 5 6 ExcelReader reader;"test.xlsx" ), 0 );"test.xlsx" ), "sheet1" );
读取大数据量的Excel
1 2 3 4 5 6 7 8 9 10 private RowHandler createRowHandler () {return new RowHandler () {@Override public void handle (int sheetIndex, int rowIndex, List<Object> rowlist) {"[{}] [{}] {}" , sheetIndex, rowIndex, rowlist);"aaa.xlsx" , 0 , createRowHandler());
ExcelUtil.getReader方法只是将实体Excel文件转换为ExcelReader对象进行操作。接下来请参阅章节ExcelReader对Excel工作簿进行具体操作。
Excel读取-ExcelReader 读取Excel内容的封装,通过构造ExcelReader对象,指定被读取的Excel文件、流或工作簿,然后调用readXXX方法读取内容为指定格式。
读取Excel中所有行和列,都用列表表示
1 2 ExcelReader reader = ExcelUtil.getReader("d:/aaa.xlsx" );
读取为Map列表,默认第一行为标题行,Map中的key为标题,value为标题对应的单元格值。
1 2 ExcelReader reader = ExcelUtil.getReader("d:/aaa.xlsx" );
读取为Bean列表,Bean中的字段名为标题,字段值为标题对应的单元格值。
1 2 ExcelReader reader = ExcelUtil.getReader("d:/aaa.xlsx" );
流方式读取Excel2003-Excel03SaxReader 在标准的ExcelReader中,如果数据量较大,读取Excel会非常缓慢,并有可能造成内存溢出。因此针对大数据量的Excel,Hutool封装了event模式的读取方式。
Excel03SaxReader只支持Excel2003格式的Sax读取。
首先我们实现一下RowHandler接口,这个接口是Sax读取的核心,通过实现handle方法编写我们要对每行数据的操作方式(比如按照行入库,入List或者写出到文件等),在此我们只是在控制台打印。
1 2 3 4 5 6 7 8 private RowHandler createRowHandler () {return new RowHandler () {@Override public void handle (int sheetIndex, long rowIndex, List<Object> rowlist) {"[{}] [{}] {}" , sheetIndex, rowIndex, rowlist);
1 ExcelUtil.readBySax("aaa.xls" , 1 , createRowHandler());
1 2 Excel03SaxReader reader = new Excel03SaxReader (createRowHandler());"aaa.xls" , 0 );
reader方法的第二个参数是sheet的序号,-1表示读取所有sheet,0表示第一个sheet,依此类推。
流方式读取Excel2007-Excel07SaxReader 在标准的ExcelReader中,如果数据量较大,读取Excel会非常缓慢,并有可能造成内存溢出。因此针对大数据量的Excel,Hutool封装了Sax模式的读取方式。
Excel07SaxReader只支持Excel2007格式的Sax读取。
首先我们实现一下RowHandler接口,这个接口是Sax读取的核心,通过实现handle方法编写我们要对每行数据的操作方式(比如按照行入库,入List或者写出到文件等),在此我们只是在控制台打印。
1 2 3 4 5 6 7 8 private RowHandler createRowHandler () {return new RowHandler () {@Override public void handle (int sheetIndex, long rowIndex, List<Object> rowlist) {"[{}] [{}] {}" , sheetIndex, rowIndex, rowlist);
1 ExcelUtil.readBySax("aaa.xlsx" , 0 , createRowHandler());
1 2 Excel07SaxReader reader = new Excel07SaxReader (createRowHandler());"d:/text.xlsx" , 0 );
reader方法的第二个参数是sheet的序号,-1表示读取所有sheet,0表示第一个sheet,依此类推。
Excel生成-ExcelWriter Excel有读取也便有写出,Hutool针对将数据写出到Excel做了封装。
Hutool将Excel写出封装为ExcelWriter,原理为包装了Workbook对象,每次调用merge(合并单元格)或者write(写出数据)方法后只是将数据写入到Workbook,并不写出文件,只有调用flush或者close方法后才会真正写出文件。
由于机制原因,在写出结束后需要关闭ExcelWriter对象,调用close方法即可关闭,此时才会释放Workbook对象资源,否则带有数据的Workbook一直会常驻内存。
我们先定义一个嵌套的List,List的元素也是一个List,内层的一个List代表一行数据,每行都有4个单元格,最终list对象代表多行数据。
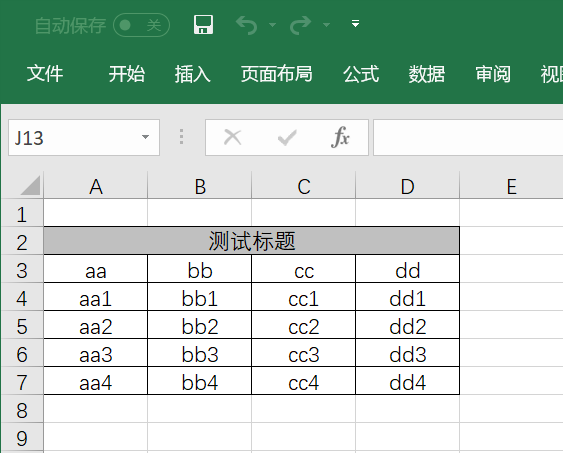
1 2 3 4 5 6 7 List<String> row1 = CollUtil.newArrayList("aa" , "bb" , "cc" , "dd" );"aa1" , "bb1" , "cc1" , "dd1" );"aa2" , "bb2" , "cc2" , "dd2" );"aa3" , "bb3" , "cc3" , "dd3" );"aa4" , "bb4" , "cc4" , "dd4" );
然后我们创建ExcelWriter对象后写出数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ExcelWriter writer = ExcelUtil.getWriter("d:/writeTest.xlsx" );1 , "测试标题" );true );
效果:
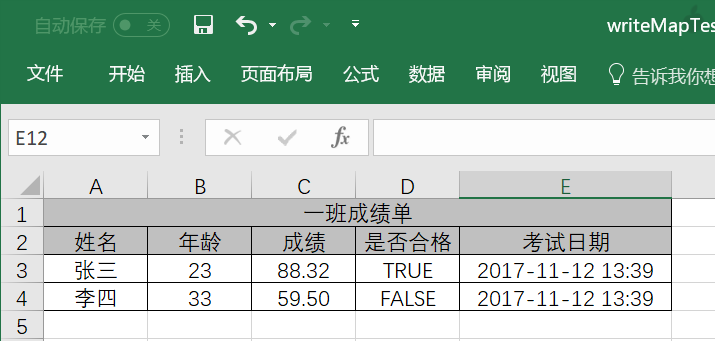
构造数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Map<String, Object> row1 = new LinkedHashMap <>();"姓名" , "张三" );"年龄" , 23 );"成绩" , 88.32 );"是否合格" , true );"考试日期" , DateUtil.date());new LinkedHashMap <>();"姓名" , "李四" );"年龄" , 33 );"成绩" , 59.50 );"是否合格" , false );"考试日期" , DateUtil.date());
写出数据:
1 2 3 4 5 6 7 8 ExcelWriter writer = ExcelUtil.getWriter("d:/writeMapTest.xlsx" );1 , "一班成绩单" );true );
效果:
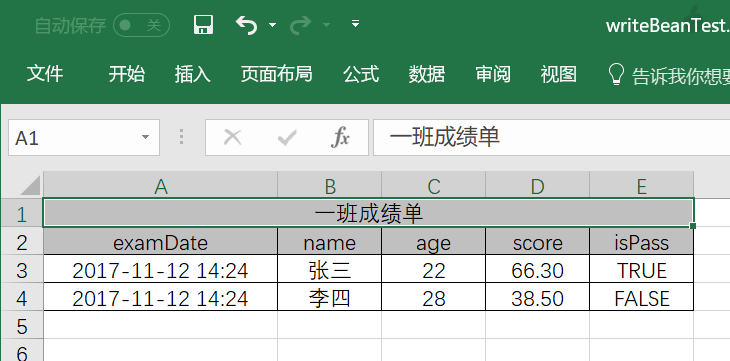
定义Bean:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public class TestBean {private String name;private int age;private double score;private boolean isPass;private Date examDate;public String getName () {return name;public void setName (String name) {this .name = name;public int getAge () {return age;public void setAge (int age) {this .age = age;public double getScore () {return score;public void setScore (double score) {this .score = score;public boolean isPass () {return isPass;public void setPass (boolean isPass) {this .isPass = isPass;public Date getExamDate () {return examDate;public void setExamDate (Date examDate) {this .examDate = examDate;
构造数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 TestBean bean1 = new TestBean ();"张三" );22 );true );66.30 );TestBean bean2 = new TestBean ();"李四" );28 );false );38.50 );
写出数据:
1 2 3 4 5 6 7 8 ExcelWriter writer = ExcelUtil.getWriter("d:/writeBeanTest.xlsx" );4 , "一班成绩单" );true );
效果:
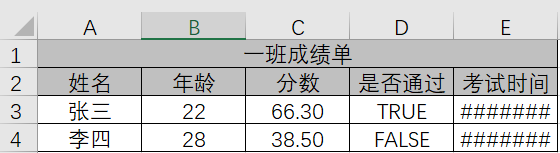
在写出Bean的时候,我们可以调用ExcelWriter对象的addHeaderAlias方法自定义Bean中key的别名,这样就可以写出自定义标题了(例如中文)。
写出数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ExcelWriter writer = ExcelUtil.getWriter("d:/writeBeanTest.xlsx" );"name" , "姓名" );"age" , "年龄" );"score" , "分数" );"isPass" , "是否通过" );"examDate" , "考试时间" );true );4 , "一班成绩单" );true );
效果:
提示(since 4.1.5) 默认情况下Excel中写出Bean字段不能保证顺序,此时可以使用addHeaderAlias方法设置标题别名,Bean的写出顺序就会按照标题别名的加入顺序排序。 如果不需要设置标题但是想要排序字段,请调用writer.addHeaderAlias("age", "age")设置一个相同的别名就可以不更换标题。 未设置标题别名的字段不参与排序,会默认排在前面。
1 2 3 4 5 6 7 8 9 10 ExcelWriter writer = ExcelUtil.getWriter();true );
写出xls
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ExcelWriter writer = ExcelUtil.getWriter();true );"application/vnd.ms-excel;charset=utf-8" ); "Content-Disposition" ,"attachment;filename=test.xls" ); true );
写出xlsx
1 2 3 4 5 6 7 8 9 ExcelWriter writer = ExcelUtil.getWriter(true );true );"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet;charset=utf-8" ); "Content-Disposition" ,"attachment;filename=test.xlsx" ); true );
注意 ExcelUtil.getWriter()默认创建xls格式的Excel,因此写出到客户端也需要自定义文件名为XXX.xls,否则会出现文件损坏的提示。 若想生成xlsx格式,请使用ExcelUtil.getWriter(true)创建。
下载提示文件损坏问题解决
有用户反馈按照代码生成的Excel下载后提示文件损坏,无法打开,经过排查,可能是几个问题:
1 2 3 4 5 6 ExcelWriter writer = ...;StyleSet style = writer.getStyleSet();false );
1 2 3 4 5 6 7 8 ExcelWriter writer = ...;Font font = writer.createFont();true );true ); true );
1 2 3 4 5 6 7 ExcelWriter writer = new ExcelWriter ("d:/aaa.xls" , "表1" );"表2" );"表3" );
在Excel中,由于样式对象个数有限制,因此Hutool根据样式种类分为4个样式对象,使相同类型的单元格可以共享样式对象。样式按照类别存在于StyleSet中,其中包括:
头部样式 headCellStyle
普通单元格样式 cellStyle
数字单元格样式 cellStyleForNumber
日期单元格样式 cellStyleForDate
其中cellStyleForNumber cellStyleForDate用于控制数字和日期的显示方式。
因此我们可以使用以下方式获取CellStyle对象自定义指定种类的样式:
1 2 3 StyleSet style = writer.getStyleSet();CellStyle cellStyle = style.getHeadCellStyle();
你可以实现CellSetter接口来自定义写出到单元格的值,此接口只有一个方法:setValue(Cell cell),通过暴露Cell对象使得用户可以自定义输出单元格内容,甚至是样式。
1 2 3 4 5 6 "自定义内容" ));ExcelWriter writer = ExcelUtil.getWriter("/test/test.xlsx" );
注意 某些特殊的字符出会导致Excel自动转义,如_xXXXX_这种格式的字符串会被当做unicode转义符,会被反转义。 此时可以使用Hutool内置的EscapeStrCellSetter
1 2 3 4 5 List<Object> row = ListUtil.of(new EscapeStrCellSetter ("_x5116_" ));ExcelWriter writer = ExcelUtil.getWriter("/test/test.xlsx" );
此问题的详细说明见:https://gitee.com/dromara/hutool/issues/I466ZZ
Excel大数据生成-BigExcelWriter 对于大量数据输出,采用ExcelWriter容易引起内存溢出,因此有了BigExcelWriter,使用方法与ExcelWriter完全一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 List<?> row1 = CollUtil.newArrayList("aa" , "bb" , "cc" , "dd" , DateUtil.date(), 3.22676575765 );"aa1" , "bb1" , "cc1" , "dd1" , DateUtil.date(), 250.7676 );"aa2" , "bb2" , "cc2" , "dd2" , DateUtil.date(), 0.111 );"aa3" , "bb3" , "cc3" , "dd3" , DateUtil.date(), 35 );"aa4" , "bb4" , "cc4" , "dd4" , DateUtil.date(), 28.00 );"e:/xxx.xlsx" );
Word生成-Word07Writer Hutool针对Word(主要是docx格式)进行封装,实现简单的Word文件创建。
Hutool将POI中Word生成封装为Word07Writer, 通过分段写出,实现word生成。
1 2 3 4 5 6 7 8 9 10 Word07Writer writer = new Word07Writer ();new Font ("方正小标宋简体" , Font.PLAIN, 22 ), "我是第一部分" , "我是第二部分" );new Font ("宋体" , Font.PLAIN, 22 ), "我是正文第一部分" , "我是正文第二部分" );"e:/wordWrite.docx" ));
系统属性调用-SystemUtil 此工具是针对System.getProperty(name)的封装,通过此工具,可以获取如下信息:
1 SystemUtil.getJvmSpecInfo();
1 SystemUtil.getJvmInfo();
1 SystemUtil.getJavaSpecInfo();
1 SystemUtil.getJavaInfo();
1 SystemUtil.getJavaRuntimeInfo();
1 SystemUtil.getUserInfo();
1 SystemUtil.getHostInfo();
1 SystemUtil.getRuntimeInfo();
Oshi封装-OshiUtil Oshi是Java的免费基于JNA的操作系统和硬件信息库,Github地址是:https://github.com/oshi/oshi
它的优点是不需要安装任何其他本机库,并且旨在提供一种跨平台的实现来检索系统信息,例如操作系统版本,进程,内存和CPU使用率,磁盘和分区,设备,传感器等。
这个库可以监测的内容包括:
计算机系统和固件,底板
操作系统和版本/内部版本
物理(核心)和逻辑(超线程)CPU,处理器组,NUMA节点
系统和每个处理器的负载百分比和滴答计数器
CPU正常运行时间,进程和线程
进程正常运行时间,CPU,内存使用率,用户/组,命令行
已使用/可用的物理和虚拟内存
挂载的文件系统(类型,可用空间和总空间)
磁盘驱动器(型号,序列号,大小)和分区
网络接口(IP,带宽输入/输出)
电池状态(电量百分比,剩余时间,电量使用情况统计信息)
连接的显示器(带有EDID信息)
USB设备
传感器(温度,风扇速度,电压)
也就是说配合一个前端界面,完全可以搞定系统监控了。
先引入Oshi库:
1 2 3 4 5 <dependency > <groupId > com.github.oshi</groupId > <artifactId > oshi-core</artifactId > <version > 5.6.1</version > </dependency >
然后可以调用相关API获取相关信息。
例如我们像获取内存总量:
1 long total = OshiUtil.getMemory().getTotal();
我们也可以获取CPU的一些信息:
1 2 3 4 5 6 7 8 9 CpuInfo cpuInfo = OshiUtil.getCpuInfo();12 , CPU总的使用率=12595.0 , CPU系统使用率=1.74 , CPU用户使用率=6.69 , CPU当前等待率=0.0 , CPU当前空闲率=91.57 , CPU利用率=8.43 , CPU型号信息='AMD Ryzen 5 4600U with Radeon Graphics 1 physical CPU package(s) 6 physical CPU core(s) 12 logical CPU(s) Identifier: AuthenticAMD Family 23 Model 96 Stepping 1 ProcessorID: xxxxxxxxx Microarchitecture: unknown' }
图形验证码 由于对验证码需求量巨大,且我之前项目中有所积累,因此在Hutool中加入验证码生成和校验功能。
验证码功能位于cn.hutool.captcha包中,核心接口为ICaptcha,此接口定义了以下方法:
createCode 创建验证码,实现类需同时生成随机验证码字符串和验证码图片getCode 获取验证码的文字内容verify 验证验证码是否正确,建议忽略大小写write 将验证码写出到目标流中
其中write方法只有一个OutputStream,ICaptcha实现类可以根据这个方法封装写出到文件等方法。
AbstractCaptcha为一个ICaptcha抽象实现类,此类实现了验证码文本生成、非大小写敏感的验证、写出到流和文件等方法,通过继承此抽象类只需实现createImage方法定义图形生成规则即可。
生成效果大致如下:
贴栗子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 LineCaptcha lineCaptcha = CaptchaUtil.createLineCaptcha(200 , 100 );"d:/line.png" );"1234" );"d:/line.png" );"1234" );
贴栗子:
1 2 3 4 5 6 7 CircleCaptcha captcha = CaptchaUtil.createCircleCaptcha(200 , 100 , 4 , 20 );"d:/circle.png" );"1234" );
贴栗子:
1 2 3 4 5 6 7 ShearCaptcha captcha = CaptchaUtil.createShearCaptcha(200 , 100 , 4 , 4 );"d:/shear.png" );"1234" );
1 2 3 ICaptcha captcha = ...;
有时候标准的验证码不满足要求,比如我们希望使用纯字母的验证码、纯数字的验证码、加减乘除的验证码,此时我们就要自定义CodeGenerator
1 2 3 4 5 6 7 8 9 10 11 RandomGenerator randomGenerator = new RandomGenerator ("0123456789" , 4 );LineCaptcha lineCaptcha = CaptchaUtil.createLineCaptcha(200 , 100 );ShearCaptcha captcha = CaptchaUtil.createShearCaptcha(200 , 45 , 4 , 4 );new MathGenerator ());
NIO封装-NioServer和NioClient Hutool对NIO其进行了简单的封装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 NioServer server = new NioServer (8080 );ByteBuffer readBuffer = ByteBuffer.allocate(1024 );try {int readBytes = sc.read(readBuffer);if (readBytes > 0 ) {byte [] bytes = new byte [readBuffer.remaining()];String body = StrUtil.utf8Str(bytes);"[{}]: {}" , sc.getRemoteAddress(), body);else if (readBytes < 0 ) {catch (IOException e){throw new IORuntimeException (e);public static void doWrite (SocketChannel channel, String response) throws IOException {"收到消息:" + response;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 NioClient client = new NioClient ("127.0.0.1" , 8080 );ByteBuffer readBuffer = ByteBuffer.allocate(1024 );int readBytes = sc.read(readBuffer);if (readBytes > 0 ) {byte [] bytes = new byte [readBuffer.remaining()];String body = StrUtil.utf8Str(bytes);"[{}]: {}" , sc.getRemoteAddress(), body);else if (readBytes < 0 ) {"你好。\n" ));"你好2。" ));"请输入发送的消息:" );Scanner scanner = new Scanner (System.in);while (scanner.hasNextLine()) {String request = scanner.nextLine();if (request != null && request.trim().length() > 0 ) {
AIO封装-AioServer和AioClient 在JDK7+后,提供了异步Socket库——AIO,Hutool对其进行了简单的封装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 AioServer aioServer = new AioServer (8899 );new SimpleIoAction () {@Override public void accept (AioSession session) {"【客户端】:{} 连接。" , session.getRemoteAddress());"=== Welcome to Hutool socket server. ===" ));@Override public void doAction (AioSession session, ByteBuffer data) {if (false == data.hasRemaining()) {StringBuilder response = StrUtil.builder()"HTTP/1.1 200 OK\r\n" )"Date: " ).append(DateUtil.formatHttpDate(DateUtil.date())).append("\r\n" )"Content-Type: text/html; charset=UTF-8\r\n" )"\r\n" )"Hello Hutool socket" );else {true );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 AioClient client = new AioClient (new InetSocketAddress ("localhost" , 8899 ), new SimpleIoAction () {@Override public void doAction (AioSession session, ByteBuffer data) {if (data.hasRemaining()) {"OK" );"Hello" .getBytes()));
JWT工具-JWTUtil 我们可以通过JWT实现链式创建JWT对象或JWT字符串,Hutool同样提供了一些快捷方法封装在JWTUtil中。主要包括:
1 2 3 4 5 6 7 8 9 Map<String, Object> map = new HashMap <String, Object>() {private static final long serialVersionUID = 1L ;"uid" , Integer.parseInt("123" ));"expire_time" , System.currentTimeMillis() + 1000 * 60 * 60 * 24 * 15 );"1234" .getBytes());
1 2 3 4 5 6 7 8 String rightToken = "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9." +"eyJzdWIiOiIxMjM0NTY3ODkwIiwiYWRtaW4iOnRydWUsIm5hbWUiOiJsb29seSJ9." +"U2aQkC2THYV9L0fTN-yBBI7gmo5xhmvMhATtu8v0zEA" ;final JWT jwt = JWTUtil.parseToken(rightToken);"sub" );
1 2 3 4 5 String token = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9." +"eyJ1c2VyX25hbWUiOiJhZG1pbiIsInNjb3BlIjpbImFsbCJdLCJleHAiOjE2MjQwMDQ4MjIsInVzZXJJZCI6MSwiYXV0aG9yaXRpZXMiOlsiUk9MRV_op5LoibLkuozlj7ciLCJzeXNfbWVudV8xIiwiUk9MRV_op5LoibLkuIDlj7ciLCJzeXNfbWVudV8yIl0sImp0aSI6ImQ0YzVlYjgwLTA5ZTctNGU0ZC1hZTg3LTVkNGI5M2FhNmFiNiIsImNsaWVudF9pZCI6ImhhbmR5LXNob3AifQ." +"aixF1eKlAKS_k3ynFnStE7-IRGiD5YaqznvK2xEjBew" ;"123456" .getBytes());
JWT签名工具-JWTSignerUtil JWT签名算法比较多,主要分为非对称算法和对称算法,支持的算法定义在SignAlgorithm中。
HS256(HmacSHA256)
HS384(HmacSHA384)
HS512(HmacSHA512)
RS256(SHA256withRSA)
RS384(SHA384withRSA)
RS512(SHA512withRSA)
ES256(SHA256withECDSA)
ES384(SHA384withECDSA)
ES512(SHA512withECDSA)
PS256(SHA256WithRSA/PSS)
PS384(SHA384WithRSA/PSS)
PS512(SHA512WithRSA/PSS)
JWTSignerUtil中预定义了一些算法的签名器的创建方法,如创建HS256的签名器:
1 2 final JWTSigner signer = JWTSignerUtil.hs256("123456" .getBytes());JWT jwt = JWT.create().setSigner(signer);
通过JWTSignerUtil.createSigner即可通过动态传入algorithmId创建对应的签名器,如我们如果需要实现ps256算法,则首先引入bcprov-jdk15to18包:
1 2 3 4 5 <dependency > <groupId > org.bouncycastle</groupId > <artifactId > bcprov-jdk15to18</artifactId > <version > 1.69</version > </dependency >
再创建对应签名器即可:
1 2 3 4 String id = "ps256" ;final JWTSigner signer = JWTSignerUtil.createSigner(id, KeyUtil.generateKeyPair(AlgorithmUtil.getAlgorithm(id)));JWT jwt = JWT.create().setSigner(signer);
JWTSigner接口是一个通用的签名器接口,如果想实现自定义算法,实现此接口即可。
JWT验证-JWTValidator 由于JWT.verify,只能验证JWT Token的签名是否有效,其他payload字段验证都可以使用JWTValidator完成。
算法的验证包括两个方面
验证header中算法ID和提供的算法ID是否一致
调用JWT.verify验证token是否正确
1 2 3 4 5 6 7 8 final String token = JWT.create()"123456" .getBytes())"123456" .getBytes()));
对于时间类载荷,有单独的验证方法,主要包括:
生效时间(JWTPayload#NOT_BEFORE)不能晚于当前时间
失效时间(JWTPayload#EXPIRES_AT)不能早于当前时间
签发时间(JWTPayload#ISSUED_AT)不能晚于当前时间
一般时间线是:
(签发时间)———(生效时间)———(当前时间 )———(失效时间)
签发时间和生效时间一般没有前后要求,都早于当前时间即可。
1 2 3 4 5 6 7 8 final String token = JWT.create()"123456" .getBytes())