14-Harness Engineering驾驭工程

参考资料:
- OpenAI驾驭工程(原文):https://openai.com/zh-Hans-CN/index/harness-engineering/
2026 年,OpenAI 在一篇博客中提出 Harness Engineering(驾驭工程) 后,迅速在 AI 圈走红。很多人还没弄清概念就开始跟风追捧,在三天一个重磅、五天一个炸裂的 AI 行业里,虽然离谱,但也合理。
本文会把 Harness Engineering / Prompt Engineering / Context Engineering 三个概念彻底串透,帮你理解:
- AI Agent 开发本质上在做什么
- 为什么同模型换个 AI IDE 效果天差地别
- “有了 AI 程序员不用写代码”到底是不是真的、怎么实现
全网资料参差不齐,如有差异,以本文为准。

一、Prompt Engineering(提示词工程)
把 ChatGPT、Cursor、TRAE 这类产品的外壳剥开,底层大模型(LLM)本质就是:
- 磁盘上的一个超大参数文件
- 加载到显存 + HTTP 接口 → 大模型 API 服务
- 套个聊天界面 → 聊天 AI
- 套个代码编辑器 → AI IDE
大模型做的事非常简单:基于当前输入,预测下一个 token 最可能是什么。
本质上它只是在“猜你想要什么”,如果指令太宽泛,输出就会极度发散。
比如你说“给这段代码加个排序”,它可能只返回几行逻辑;你必须补充:“给我完整函数代码,不要乱改原有代码”,结果才会贴合预期。
你能补充的内容包括:
- 角色设定
- 背景信息
- 历史对话
- 参考文档
- 输出格式限制
- 约束条件
这些约束共同构成了提示词(Prompt)。

提示词工程:
通过有意识地设计、调整提示词,让模型稳定按照预期内容与格式输出的技术手段。它解决的核心问题是:大模型无引导乱说话。
二、Context Engineering(上下文工程)
提示词写得越长、越细,模型知道的信息越多,回答越准;反之亦然。于是大家自然会不断往模型里塞各种资料。
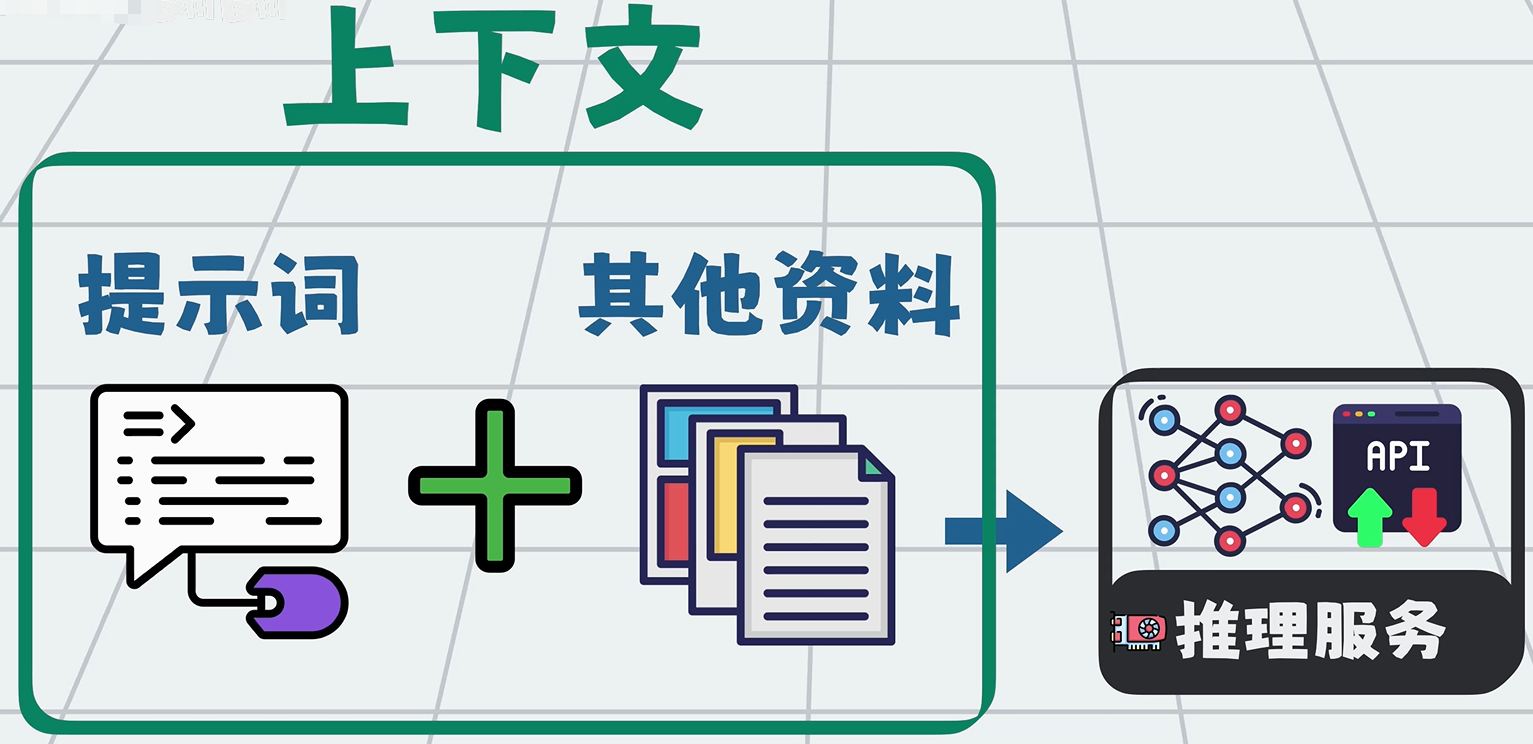
所有一起发给大模型的信息,统称为上下文(Context)。
提示词,只是上下文的一部分。但大模型再强,单次能处理的上下文也有上限,这个上限叫:上下文窗口(Context Window)
多轮对话后,上下文很容易被打满,必须通过策略压缩、丢弃部分信息。
这个过程不可避免会丢失关键信息,破坏上下文完整性与准确性,这类问题统称为:上下文腐化(Context Corruption)
表现就是:模型记不住、前后矛盾、理解跑偏。
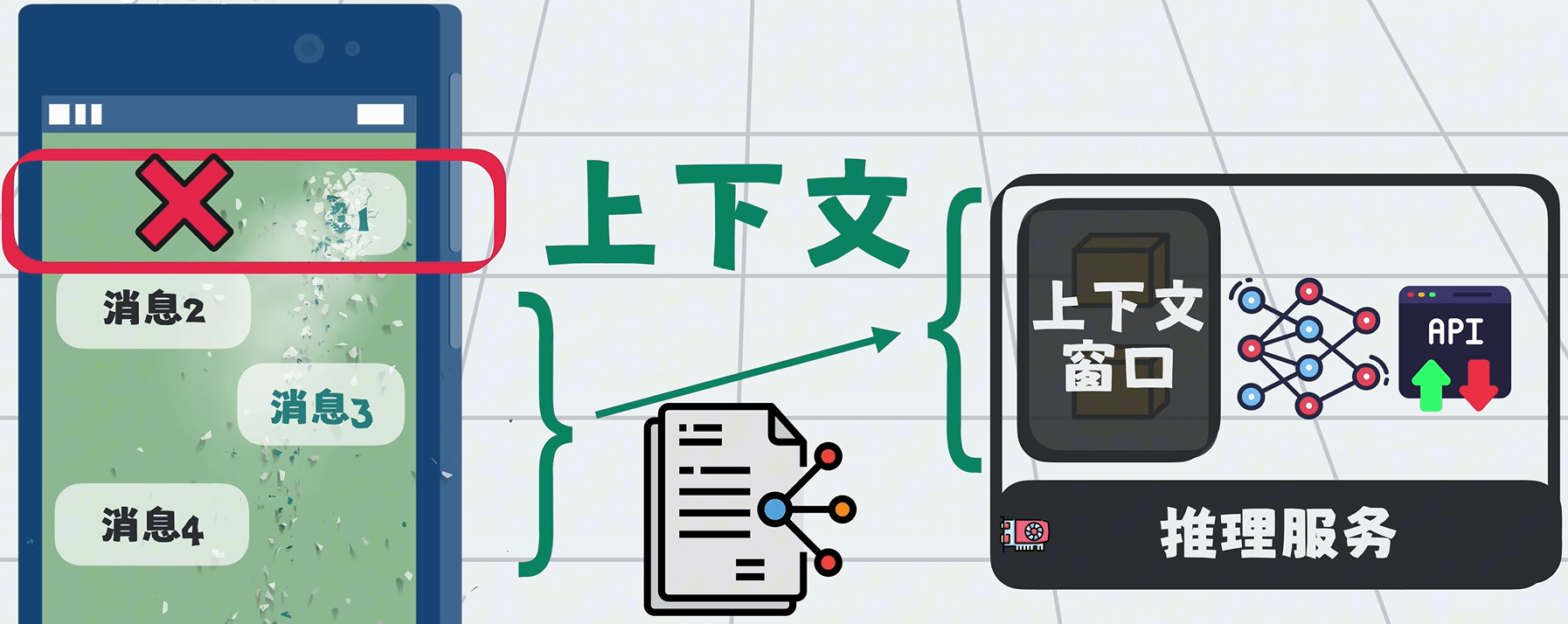
上下文窗口就这么大,问题就变成:如何在合适时机,把合适内容塞进有限上下文。
由此衍生出一整套动态管理上下文的技术,就是上下文工程。
提示词工程属于上下文工程的一部分,通常由外部程序实现(如 Cursor、Claude Code、CodeTree 等 Coding Agent)。
整体可概括为三步:
1. 召回(Retrieval)

从各类数据源找出最相关信息:
- 外部文档
- 历史聊天记录
- 当前代码环境
- 运行报错日志
- 项目结构
涉及 RAG、Memory 等技术。
2. 压缩(Compression)
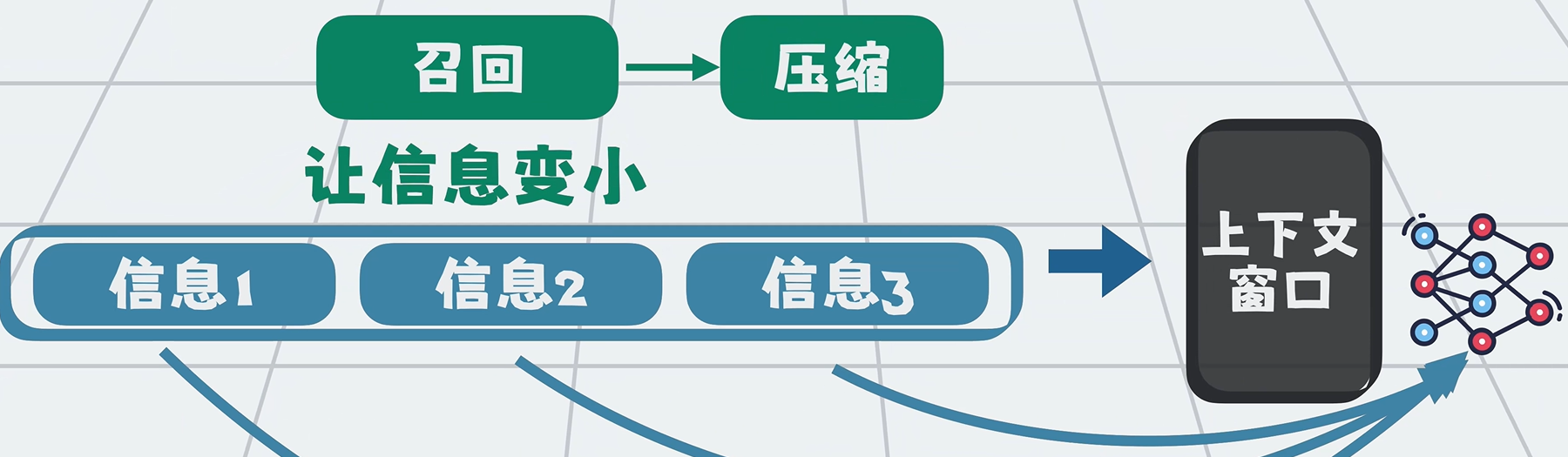
信息多、窗口小,必须精简:
- 分批总结
- 提取关键信息
- 过滤冗余内容
3. 组装(Assembly)
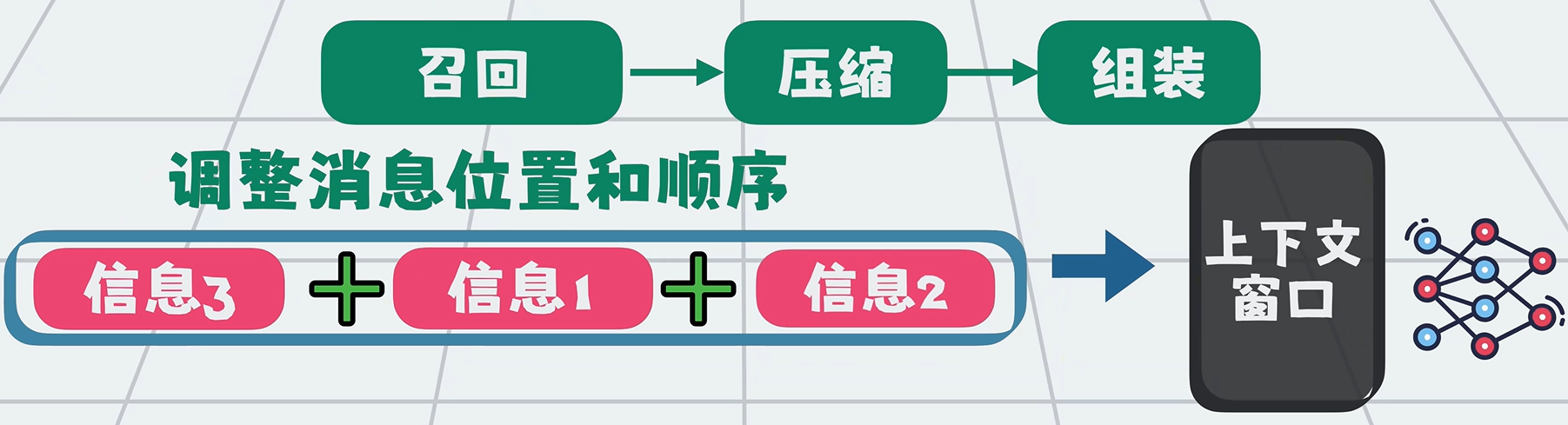
信息位置与顺序会显著影响模型理解(越靠后越容易被关注)。
通过结构化重新组织内容,让上下文更精简、更相关,输出更稳定准确。
这也是为什么:同模型、不同 AI 工具,效果差异巨大 ——核心就是上下文工程策略不同。
三、Harness Engineering(驾驭工程)
提示词工程解决:模型乱说话
上下文工程解决:上下文组织
模型更聪明了,但它仍然只能“聊天”,不能真正帮你干活。
于是我们给大模型加入外部能力,构成执行层:
- Bash / 沙箱环境
- 文件系统
- MCP 等工具能力
- 读写代码、执行命令、运行测试
再套一层外部循环:
- 用提示词 + 上下文工程组装上下文
- 大模型负责思考决策
- 外部程序负责执行
- 执行报错、日志再塞回上下文继续推理
这套“一边思考一边行动”的循环,就是 ReAct。
能通过聊天帮你执行任务的程序,就是 AI Agent。
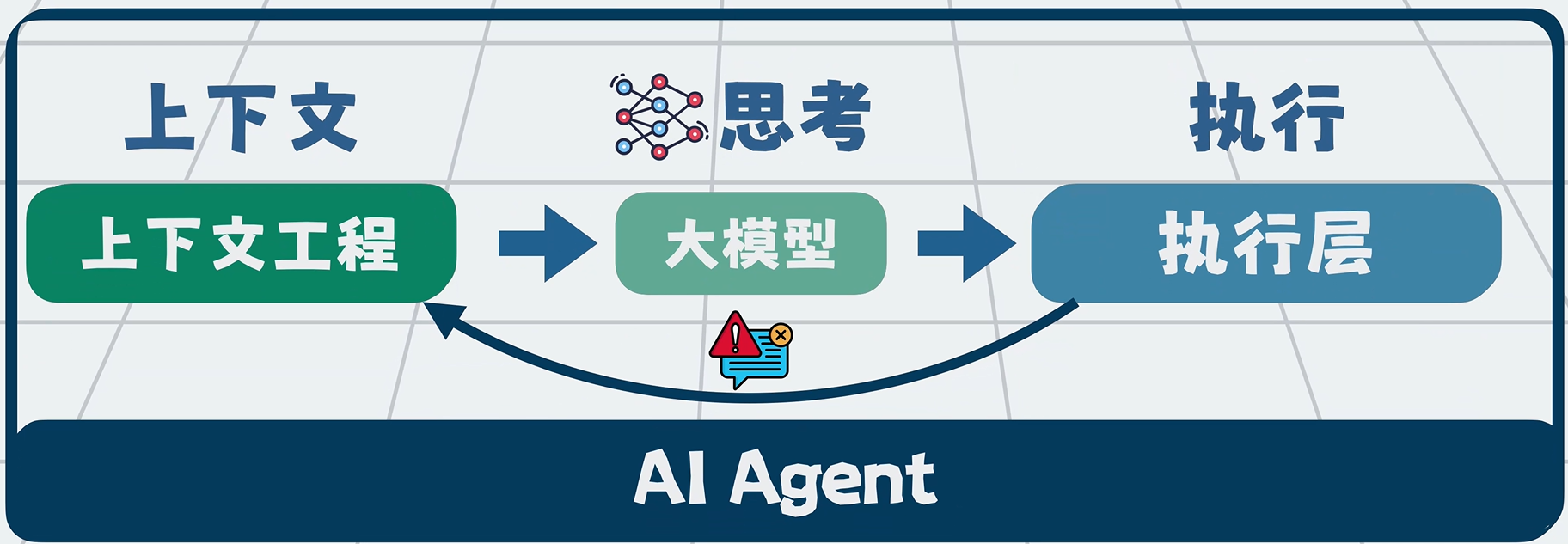
Agent 本质就是一个 for 循环。
但循环一长,上下文必然膨胀,即便上下文工程做得再好,也可能腐化:
- 看过文件越来越多
- 信息越来越杂
- 早期目标与约束被冲淡
- 理解逐渐跑偏
1. 怎么解决?
保证每次上下文中,都包含可复用的核心约束信息:
- 项目目标
- 技术栈
- 需求背景
- 代码风格
- 禁止事项
- 验收规则
这些信息固定存在仓库里,比如:
- Claude Code:
claude.md - TRAE:各类规则文件
rule.md
这类文件暂时没有统一命名,本文统称为:规则文件。调用模型时,它会作为系统提示词自动注入上下文。
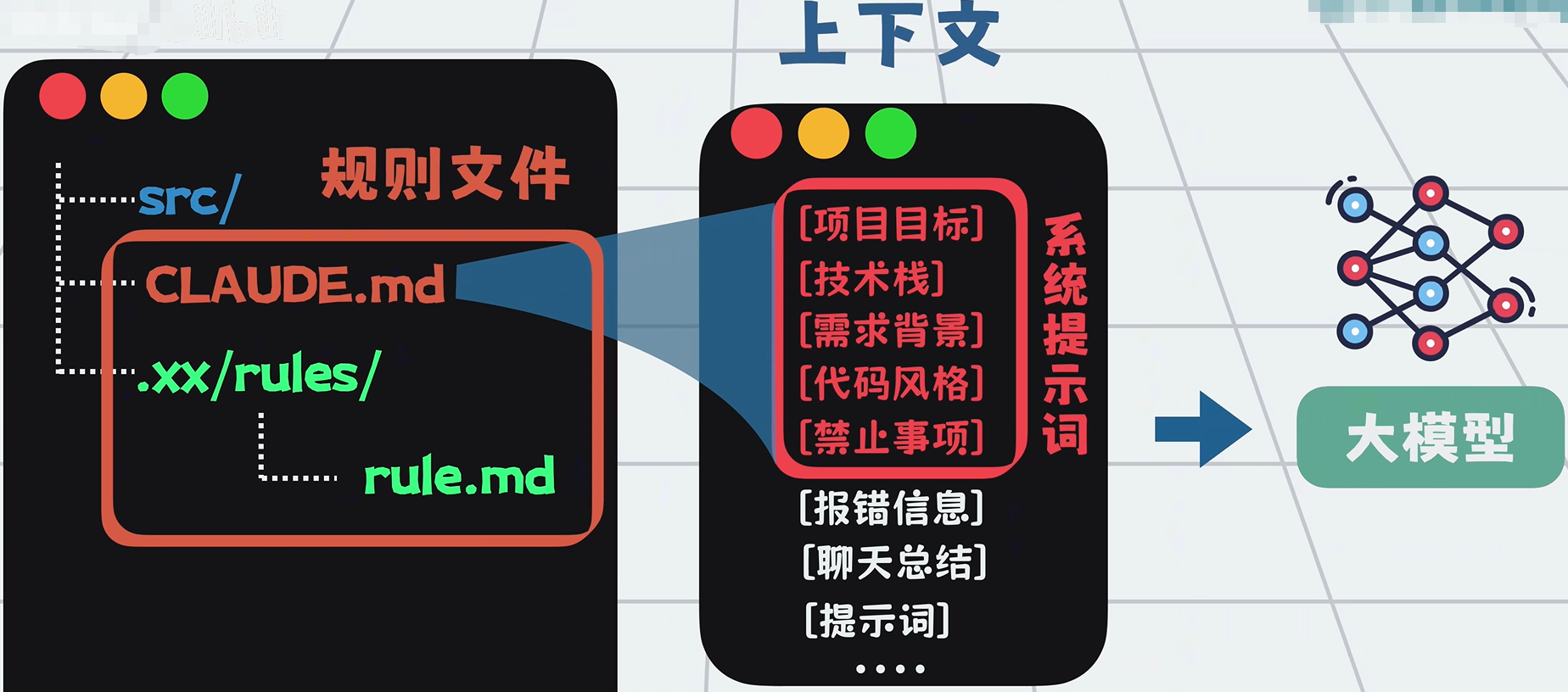
规则文件多了也会膨胀,于是可以:
拆成多个短文件
做简单路由:
.xx/rules/bg.mdstack.md
平时只加载路径,需要时再读全文
由此形成记忆层。
2. 反馈层
记忆层 + 执行层配合,Agent 可以:
- 持续写代码
- 跑 Linter
- 跑单元测试
- 把报错、测试结果回传上下文
- 驱动下一轮自动修复
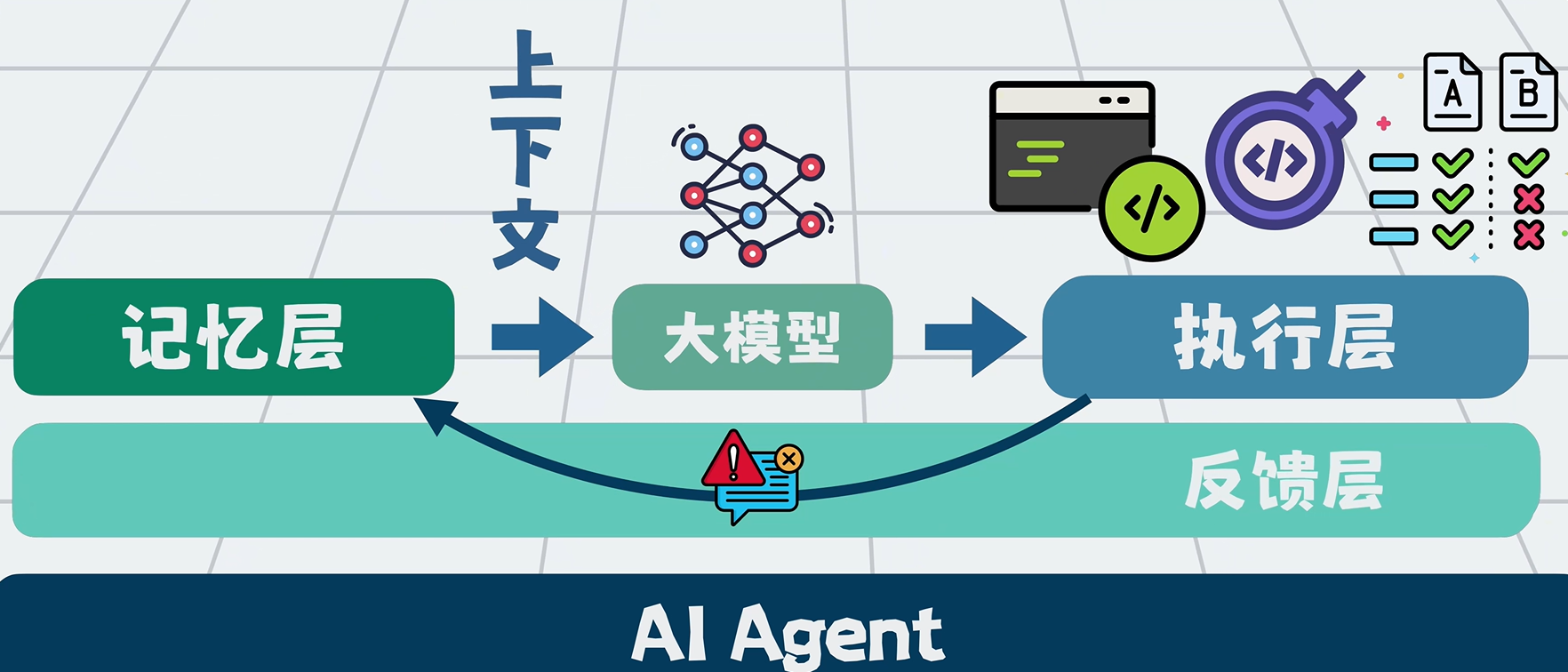
这套“校验结果 → 回传错误 → 自动修复”的能力,就是反馈层。
3. 编排层
如果 Agent 缺乏全局规划,很容易跑偏甚至死循环。
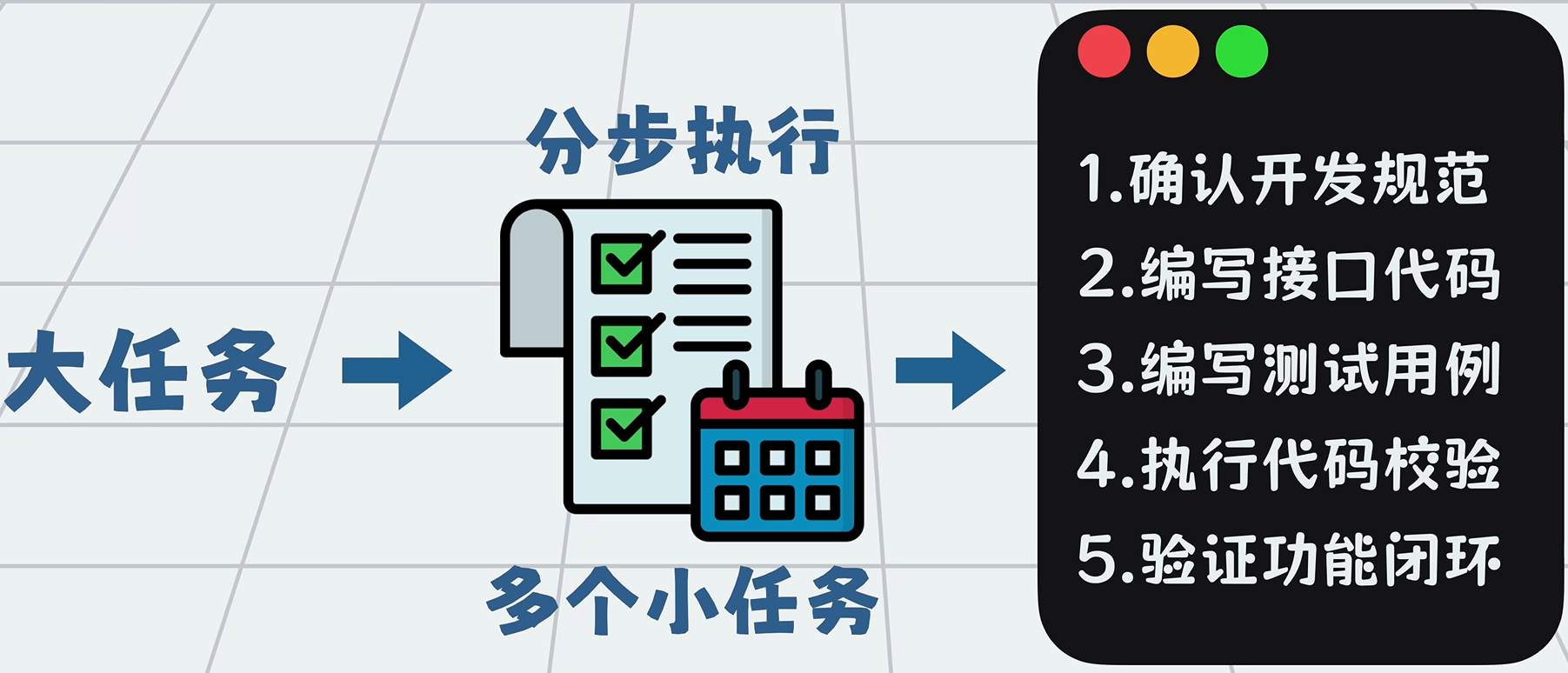
因此需要:
- 把大任务拆解为可验收的子任务
- 按规划分步执行
- 全流程管控
这种以全局规划为核心的任务拆解与管控能力,就是编排层。
四、Harness Engineering 定义(★)
编排层 + 执行层 + 反馈层 + 记忆层 共同构成了一套包裹大模型的工程化外壳。
编排层:全局规划 + 分步执行(大项目拆解为可验收的子任务)执行层:执行命令 + 读写文件 + 调用外部工具反馈层:校验结果 + 回传错误(回传给记忆层) + 自动修复记忆层:即上下文工程(提示词工程(角色设定+背景信息+历史对话+参考文档+输出格式限制+约束条件))
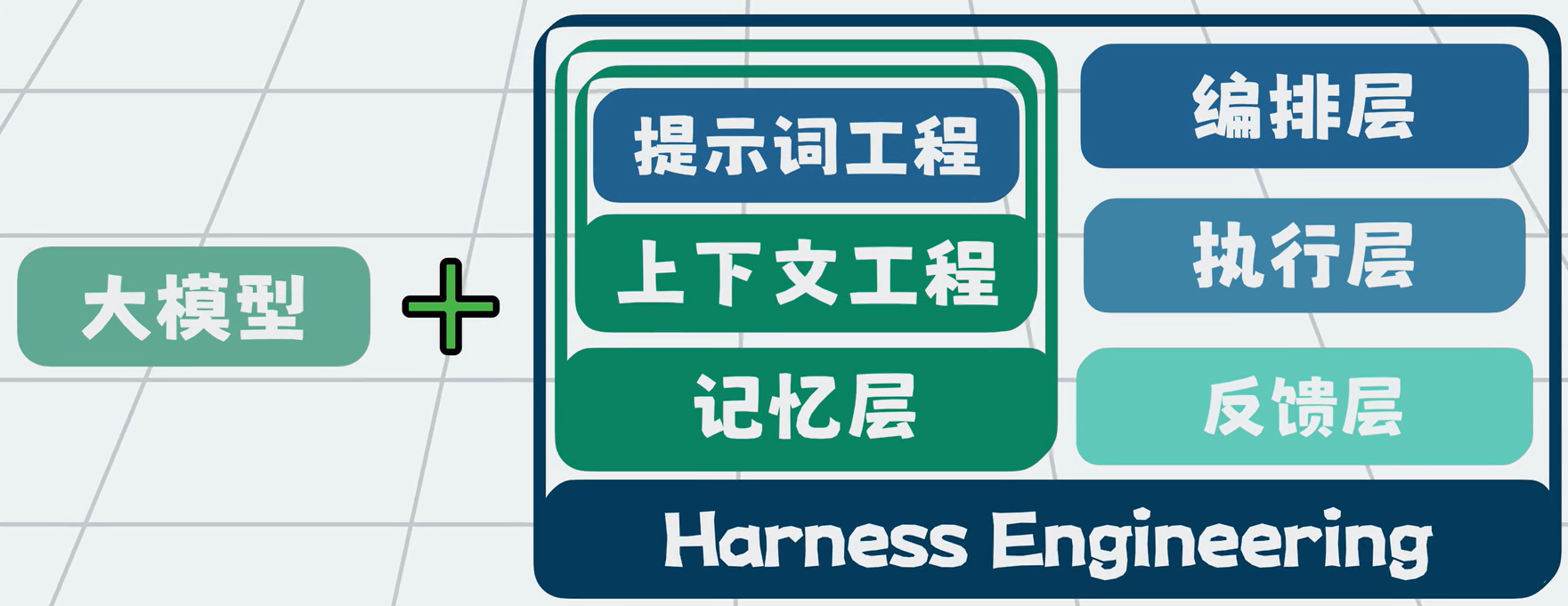
这就是:Harness Engineering(驾驭工程)。
- 模型越强,外壳可以越薄
- 但无论如何,这层外壳必须存在
一个公式:Agent = LLM + Harness Engineering
只要不属于大模型本身的部分,全都属于 Harness Engineering 范畴,这会成为存量程序员未来的核心主战场。
五、Harness Engineering 如何落地(★)
以 Claude Code 为例:软件本身已原生支持 Harness 四层能力。
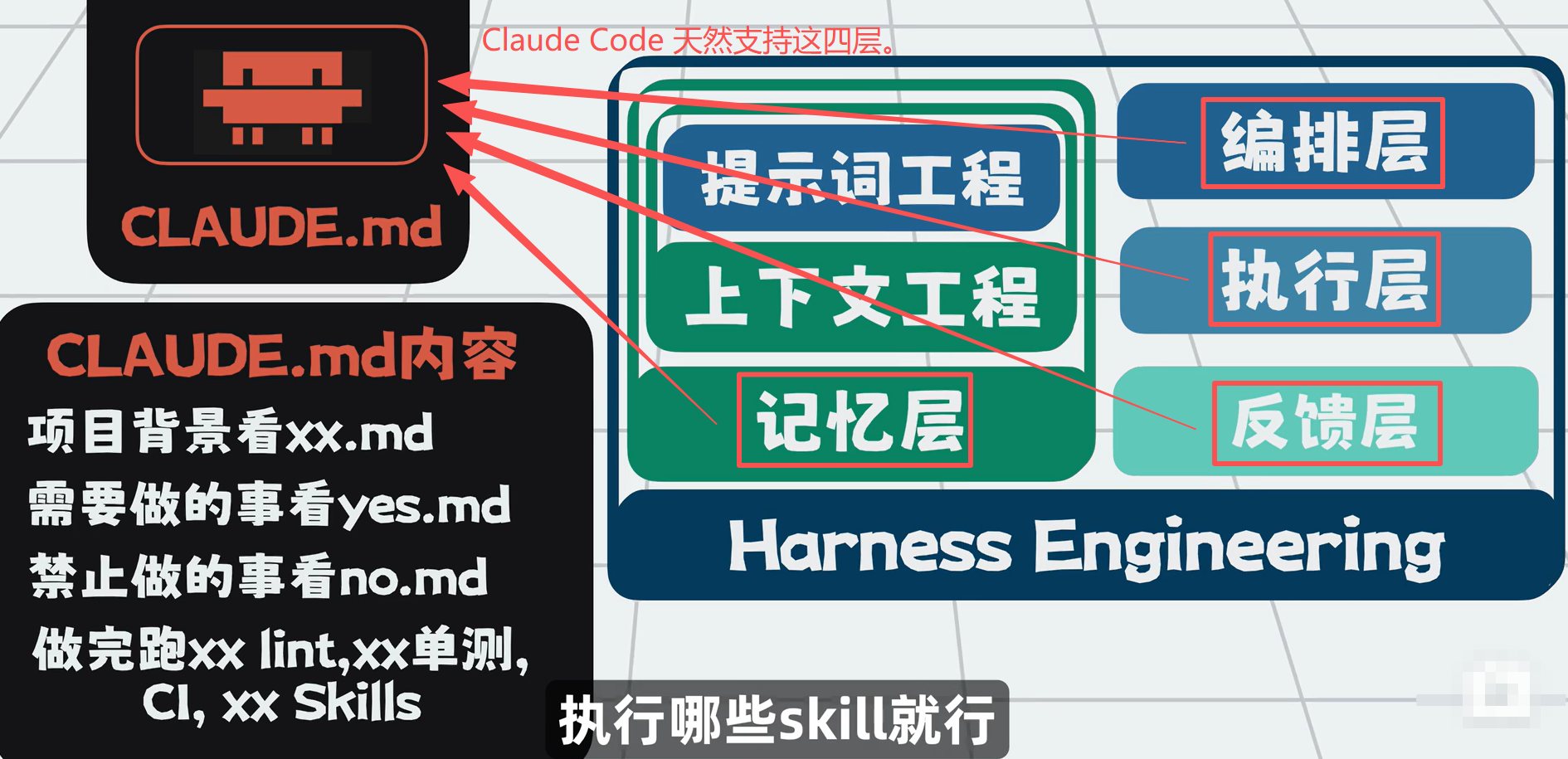
最轻量落地方式
在 claude.md 里写清楚:
- 项目背景
- 允许做什么、禁止做什么
- 完成后要跑哪些 Lint、单测、CI
- 执行哪些 Skill
进阶落地:插件/扩展方案
如 Spark Agent 这类扩展:
- 生成约束文件,明确需求
- 制定开发计划,拆解任务
- 执行修改 + 测试
- 每个阶段更新
claude.md
这套模式被称为:SD (Skill-Driven Development)
本质就是 Harness Engineering 的工程化落地,未来一定会出现更强、更全面的替代方案。
六、三者关系总结
- 提示词工程:让大模型明白 你要什么、输出标准是什么
- 上下文工程:让大模型获得:精准、有效、不过载的上下文
- Harness Engineering(驾驭工程):让大模型能够
- 持续按规范执行
- 自我修复
- 按规划推进
- 最终交付可用结果
七、对程序员的影响
有了 Harness Engineering,程序员的工作重心会逐渐从:写代码 → 写规则、写 Skill
一句很形象的话:
那些拿了 N+1 的同事其实从未离开,他们只是变成了 Skill,默默陪在你身边。o_O!!!
