官网地址:https://www.elastic.co/cn/Elasticsearch/
参考资料:https://wiki.jikexueyuan.com/project/Elasticsearch-definitive-guide-cn/
1. 简介
- 海量数据的存储和搜索
随着系统的并发量越来越大,系统的数据量也越来越多,也就会数据搜索速度越来越低,存储和搜索的压力
越来越大。
- 存储:数据的分片、搭建数据库的集群、第三方云数据库(弹性扩容)
- 搜索:全文检索技术(Elasticsearch、Solr)
1.1 主流全文检索框架
- Lucene
Lucene是Apache Jakarta家族中的一个开源项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎、索引引擎和部分文本分析引
擎。 Elasticsearch和Solr都是基于Lucene实现的。
官网:https://lucene.apache.org/
- Solr
Solr具有高度的可靠性,可伸缩性和容错性,可提供分布式索引,复制和负载平衡查询,自动故障转移和恢
复,集中式配置等。Solr为许多世界上最大的互联网站点提供搜索和导航功能。
分布式的开发中,占比重要,但是在微服务占有度下降。
官网:https://lucene.apache.org/solr/
Elasticsearch
Elasticsearch是一个高度可扩展的开源全文本搜索和分析引擎。可以快速,近乎实时地存储,搜索和分析大量
数据。它通常用作支持具有复杂搜索功能和要求的应用程序的基础引擎/技术。
现在各大互联网主流
1.2 Elasticsearch
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。同时也一个高度可扩展的开源全文本搜索和分析引擎。可以快速,近乎实时地存储,搜索和分析大量数据。它通常用作支持具有复杂搜索功能和要求的应用程序的基础引擎/技术。
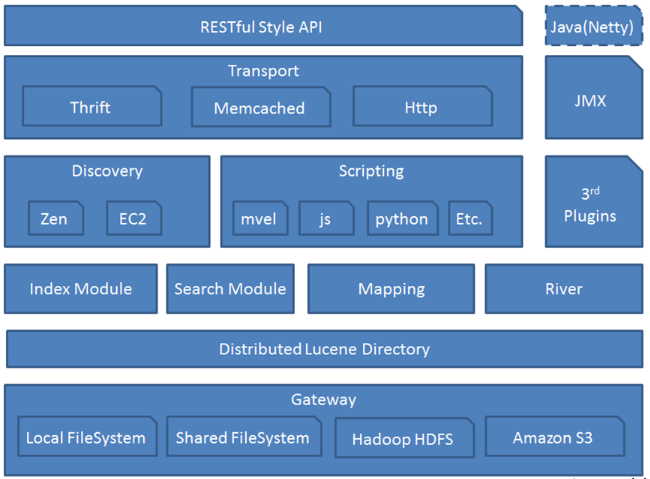
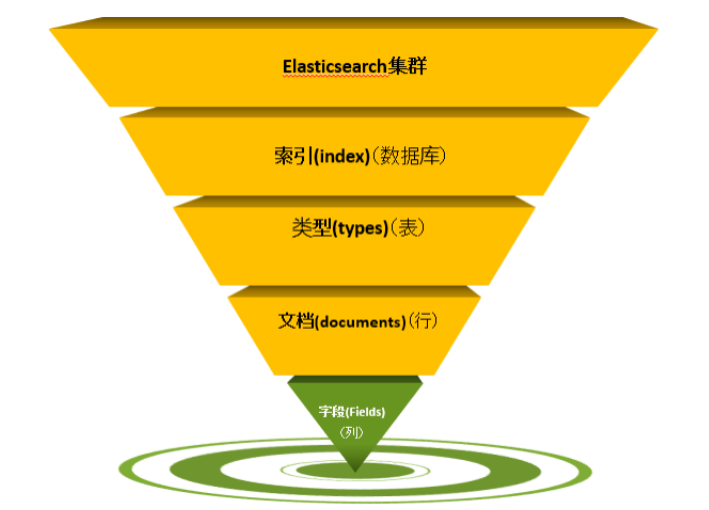
集群索引-Index 类似 数据库-Database
索引是Elasticsearch存放数据的地方,可以理解为关系型数据库中的一个数据库。事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。然而,这只是一些内部细节——我们的程序完全不用关心分片。对于我们的程序而言,文档存储在索引(index)中。剩下的细节由Elasticsearch关心既可。(索引的名字必须是全部小写,不能以下划线开头,不能包含逗号)类型-Type 类似 数据库中的表-Table
类型用于区分同一个索引下不同的数据类型,相当于关系型数据库中的表。在Elasticsearch中,我们使用相同
类型(type)的文档表示相同的“事物”,因为他们的数据结构也是相同的。每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所有类型下的文档被存储在同一个索引下,但是类型的映射(mapping)会告诉Elasticsearch不同的文档如何被索引。
es 6.0 开始不推荐一个index下多个type的模式,在 7.0 中完全移除。在 7.0 的index下是无法创建多个
type文档-Document 类似 表中的行级数据
文档是Elasticsearch中存储的实体,类比关系型数据库,每个文档相当于数据库表中的一行数据。 在Elasticsearch中,文档(document)这个术语有着特殊含义。它特指最顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID标识并存储于Elasticsearch中)。字段-Field 类似 数据库表中的列名。
- 作用
- 实现海量数据的存储 支持PB级别
- 快速搜索 性能高(倒排索引)
- 对海量数据进行分析
2. 安装
Linux 安装 / Linux 在 Docker 中安装。
步骤:
1
2
3
4
5
6
7
8
9
10
|
docker pull Elasticsearch:7.6.1
docker run --name es9200 -p 9200:9200 -d Elasticsearch:7.6.1
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 --name es elasticsearch:7.6.1
http://服务器IP:9200/
|
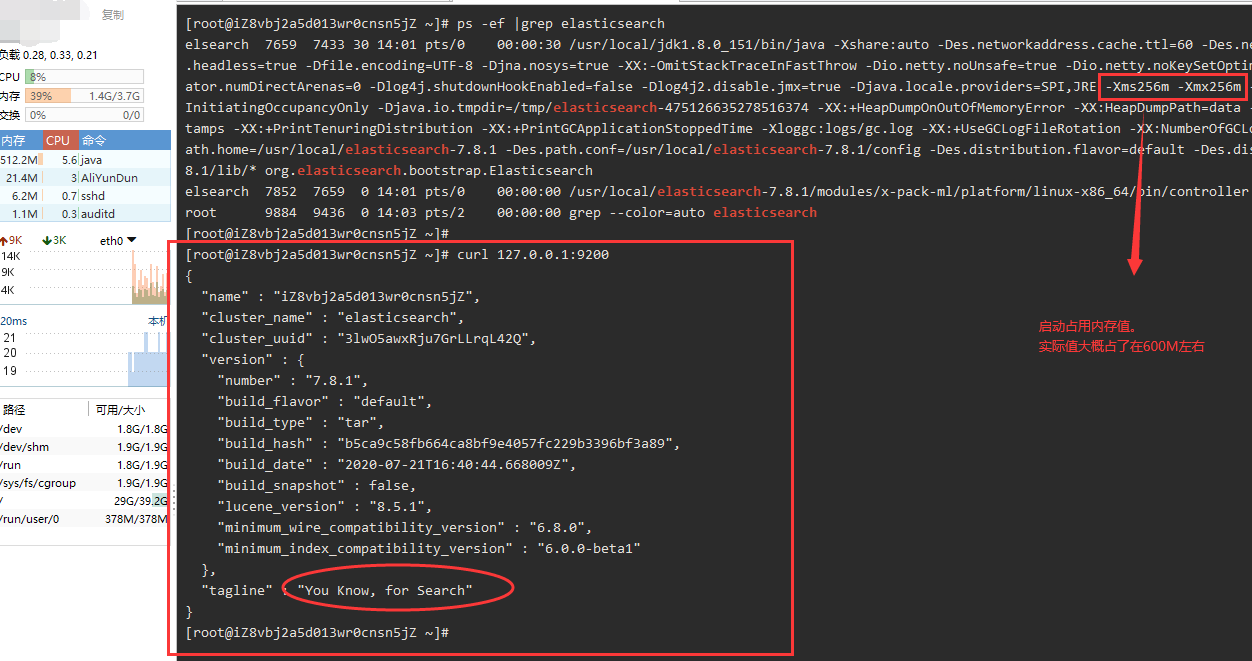
Elasticsearch 对内存的要求较高,一般最低 8G 起步。
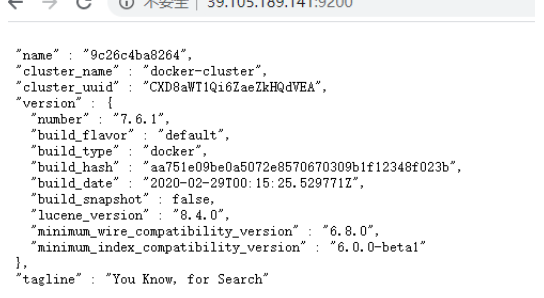
可视化:
1
2
3
4
5
6
7
| 谷歌浏览器安装 ES-Head 插件,实现可视化ES
1.下载插件
2.打开谷歌浏览器
设置 --> 扩展程序 --> 启动开发者模式
3.解压
crx 后缀名改为zip,再解压,删除内部文件夹:_metadata
浏览器 --> 设置 --> 扩展程序 --> 加载已解压的扩展程序
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
docker pull elasticsearch:7.6.1
find / -name "jvm.options"
找到文件修改 -Xms256m -Xmx256m 即可
docker network create esnet
docker run -d --name es -p 9200:9200 -p 9300:9300 --network esnet -e "discovery.type=single-node" 镜像ID
docker ps
curl 127.0.0.1:9200
云服务器IP:9200
|
参考资料:https://www.cnblogs.com/powerbear/p/11298135.html
3. 使用
Elasticsearch存储数据,可以实现常用的CRUD,擅长搜索,Java使用ES有 2 种方式:
- 原生
Transport
Spring Data Elasticsearch
3.1 Transport
1
2
3
4
5
6
7
8
9
10
11
12
|
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>7.6.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.1</version>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| public static void main(String[] args) throws IOException {
RestHighLevelClient client=new RestHighLevelClient(
RestClient.builder(
new HttpHost("39.105.189.141",9200,"http")
)
);
Student stu01=new Student("2","小二",18);
IndexResponse response=client.index(new IndexRequest("es2001")
.id(stu01.getNo())
.source(JSON.toJSONString(stu01), XContentType.JSON)
,RequestOptions.DEFAULT);
System.err.println("操作----"+response.status().name());
Student stu02=new Student("22","小王吧",18);
UpdateResponse response02=client.update(new UpdateRequest("es2001","2")
.doc(JSON.toJSONString(stu02),XContentType.JSON)
,RequestOptions.DEFAULT);
System.err.println("ssss----->"+response02.status().name());
DeleteResponse response03=client.delete(new
DeleteRequest("es2001","2"),RequestOptions.DEFAULT);
System.err.println("删除---->"+response03.status().name());
GetResponse response04=client.get(new
GetRequest("es2001","22"),RequestOptions.DEFAULT);
System.err.println("操作-----》"+response04.getSourceAsString());
client.close();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| public static void main(String[] args) throws IOException {
RestHighLevelClient client=new RestHighLevelClient(
RestClient.builder(
new HttpHost("39.105.189.141",9200,"http"))
);
RangeQueryBuilder rangeQueryBuilder= QueryBuilders.rangeQuery("age").gt(10).lt(24);
TermQueryBuilder termQueryBuilder=QueryBuilders.termQuery("name","小二");
WildcardQueryBuilder wildcardQueryBuilder=QueryBuilders.wildcardQuery("name","*z*");
BoolQueryBuilder boolQueryBuilder=QueryBuilders.boolQuery();
boolQueryBuilder.must(wildcardQueryBuilder);
SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();
sourceBuilder.from(0).size(10).query(boolQueryBuilder);
SearchResponse response=client.search(new SearchRequest("es2001")
.source(sourceBuilder)
, RequestOptions.DEFAULT);
SearchHits searchHits=response.getHits();
for(SearchHit sh : searchHits){
System.err.println(sh.getSourceAsString());
}
client.close();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public static void main(String[] args) throws IOException {
RestHighLevelClient client=new RestHighLevelClient(
RestClient.builder(
new HttpHost("39.105.189.141",9200,"http"))
);
BulkRequest request=new BulkRequest();
for(int i=10;i<1000;i++){
request.add(new IndexRequest("es2001")
.id(i+"")
.source(JSON.toJSONString(new Student(i+"", "测试-"+i, i/10))
,XContentType.JSON));
}
BulkResponse responses=client.bulk(request,RequestOptions.DEFAULT);
System.err.println(responses.status().name());
client.close();
}
|
3.2 Spring Data Elasticsearch
Spring Data 框架,是Spring给出的一种操作各种数据源的框架,Spring Data的任务是为数据访问提供一个熟悉
且一致的,基于Spring的编程模型,同时仍保留基础数据存储的特殊特征。
- 支持对关系型数据库的操作,比如:Spring Data JPA、Spring Data JDBC
- 支持NO-SQL类型的数据库的操作,比如:Spring Data Redis、Spring Data Mongodb、Spring Data Hbase
- 支持全文检索引擎的操作,比如Spring Data Elasticsearch、Spring Data Solr等
Spring Data Elastcisearch : 是Spring对ElasticSearch操作的封装,ElasticsearchRestTemplate。
1
2
3
4
| <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
@Data
@Document(indexName = "job2001")
public class Job {
@Id
private String id;
@Field
private String jno;
private String jname;
private String company;
private String salary;
}
public interface JobDao extends ElasticsearchRepository<Job,Integer> { }
public interface JobService {
R save(Job job);
R queryAll();
R queryPage(int p,int s);
}
@Service
public class JobServiceImpl implements JobService {
@Autowired
private JobDao dao;
@Autowired
private ElasticsearchRestTemplate restTemplate;
@Override
public R save(Job job) {
if(dao.save(job) != null){
return R.ok(null);
}else {
return R.failed("新增失败");
}
}
@Override
public R queryAll() {
return R.ok(dao.findAll());
}
@Override
public R queryPage(int p, int s) {
return R.ok(dao.findAll(PageRequest.of(p-1, s, Sort.by(Sort.Order.asc("id")))));
}
}
@RestController
public class JobController {
@Autowired
private JobService service;
@GetMapping("/api/job/save.do")
public R save(Job job){
return service.save(job);
}
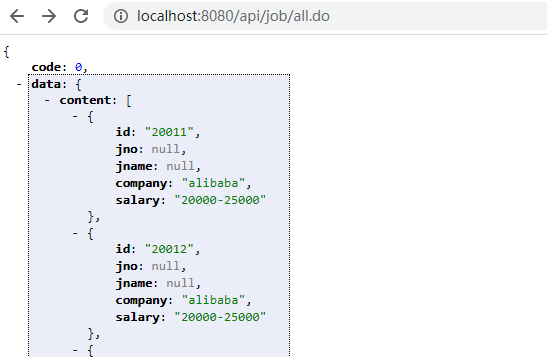
@GetMapping("/api/job/all.do")
public R all(){
return service.queryAll();
}
@GetMapping("/api/job/page.do")
public R page(int p,int s){
return service.queryPage(p, s);
}
}
|
1
2
3
4
5
|
spring:
elasticsearch:
rest:
uris: ES服务器IP:9200
|